Мы можем использовать следующий синтаксис для построения линии регрессии по группам с помощью пакета визуализации R ggplot2 :
ggplot(df, aes (x = x_variable, y = y_variable, color = group_variable)) +
geom_point() +
geom_smooth(method = " lm", fill = NA )
В этом руководстве представлен краткий пример того, как использовать эту функцию на практике.
Пример: построение линий регрессии по группам с помощью ggplot2
Предположим, у нас есть следующий набор данных, который показывает следующие три переменные для 15 разных студентов:
- Количество часов обучения
- Экзаменационная оценка получена
- Используемая методика исследования (A, B или C)
#create dataset
df <- data.frame(hours=c(1, 2, 3, 3, 4, 1, 2, 2, 3, 4, 1, 2, 3, 4, 4),
score=c(84, 86, 85, 87, 94, 74, 76, 75, 77, 79, 65, 67, 69, 72, 80),
technique= rep (c('A', 'B', 'C'), each = 5 ))
#view dataset
df
hours score technique
1 1 84 A
2 2 86 A
3 3 85 A
4 3 87 A
5 4 94 A
6 1 74 B
7 2 76 B
8 2 75 B
9 3 77 B
10 4 79 B
11 1 65 C
12 2 67 C
13 3 69 C
14 4 72 C
15 4 80 C
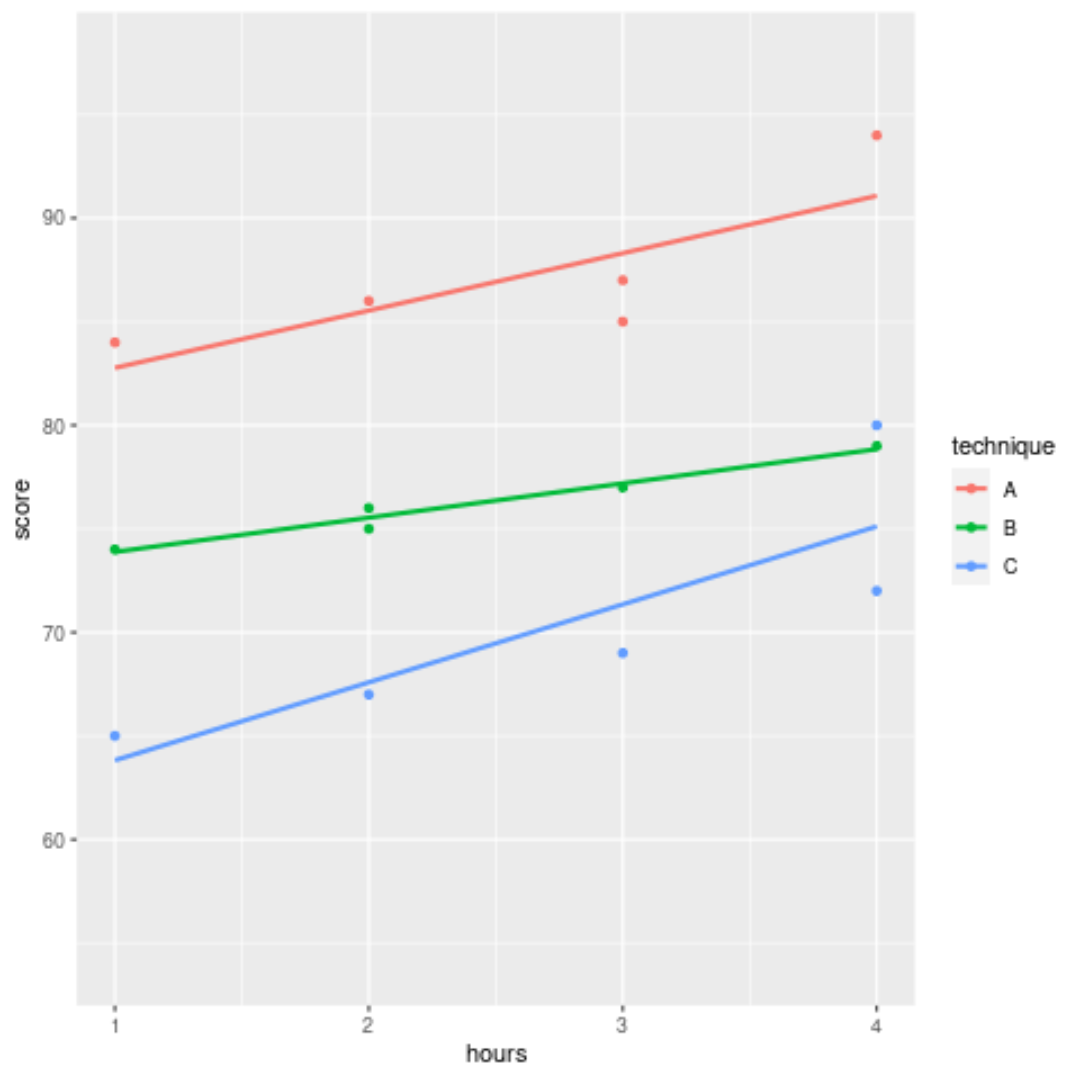
В следующем коде показано, как построить линию регрессии, отражающую взаимосвязь между количеством часов обучения и экзаменационным баллом, полученным для каждого из трех методов обучения:
#load ggplot2
library (ggplot2)
#create regression lines for all three groups
ggplot(df, aes (x = hours, y = score, color = technique)) +
geom_point() +
geom_smooth(method = " lm", fill = NA )
Обратите внимание, что в функции geom_smooth() мы использовали метод = 'lm” для указания линейного тренда.
Мы также могли бы использовать другие методы сглаживания, такие как «glm», «loess» или «gam», чтобы зафиксировать нелинейные тренды в данных. Вы можете найти полную документацию для geom_smooth() здесь .
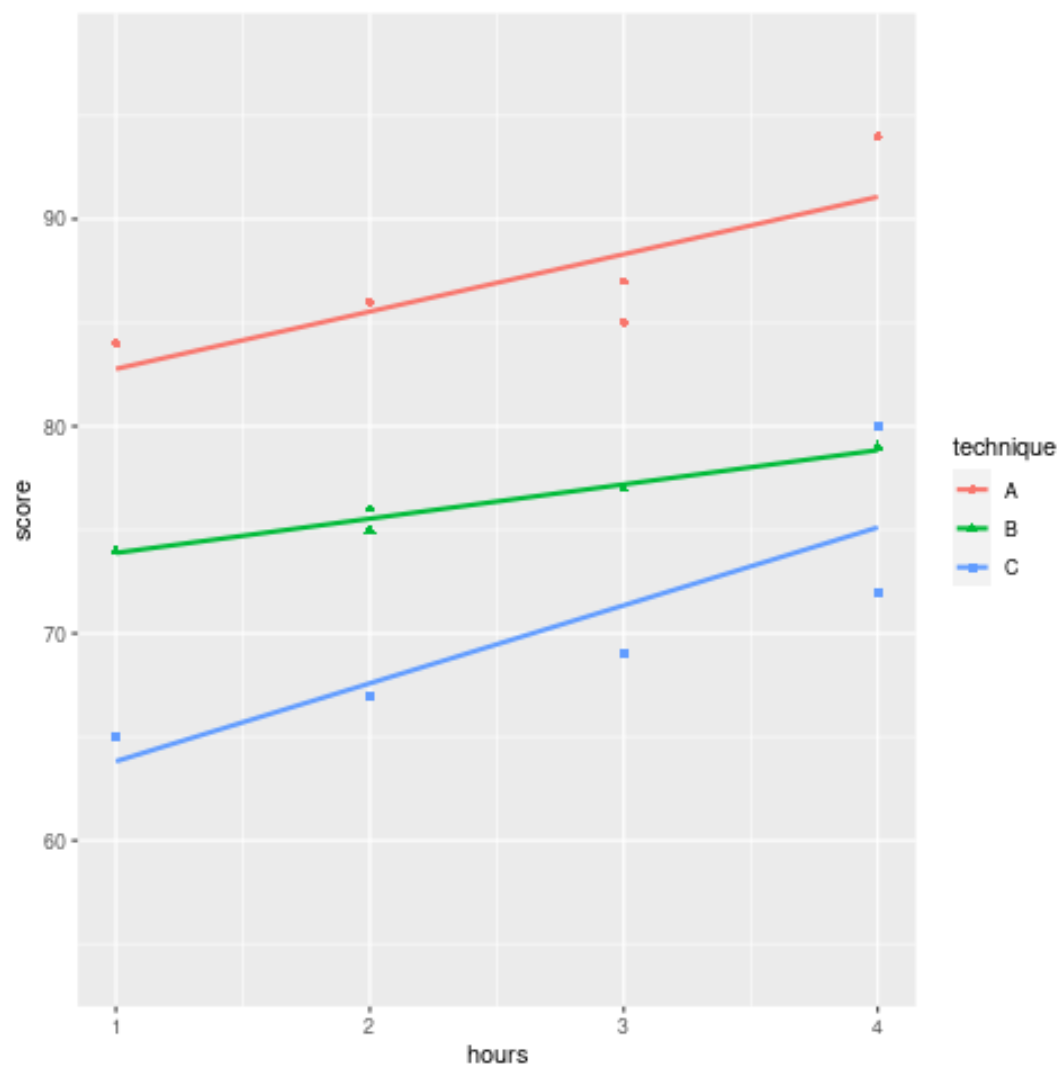
Обратите внимание, что мы также можем использовать разные формы для отображения экзаменационных баллов для каждой из трех групп:
ggplot(df, aes (x = hours, y = score, color = technique, shape = technique)) +
geom_point() +
geom_smooth(method = " lm", fill = NA )
Вы можете найти больше руководств по ggplot2 здесь .