Критерий Крускала-Уоллиса используется для определения наличия статистически значимой разницы между медианами трех или более независимых групп. Он считается непараметрическим эквивалентом однофакторного дисперсионного анализа .
В этом руководстве объясняется, как провести тест Крускала-Уоллиса в Stata.
Как выполнить тест Крускала-Уоллиса в Stata
В этом примере мы будем использовать набор данных переписи , который содержит данные переписи 1980 года для всех пятидесяти штатов США. В наборе данных штаты классифицируются по четырем различным регионам:
- К северо-востоку
- Северо-Центральный
- Юг
- Запад
Мы проведем тест Крускала-Уоллиса, чтобы определить, одинаков ли средний возраст в этих четырех регионах.
Шаг 1: Загрузите и просмотрите данные.
Сначала загрузите набор данных, введя следующую команду в поле «Команда»:
используйте http://www.stata-press.com/data/r13/census
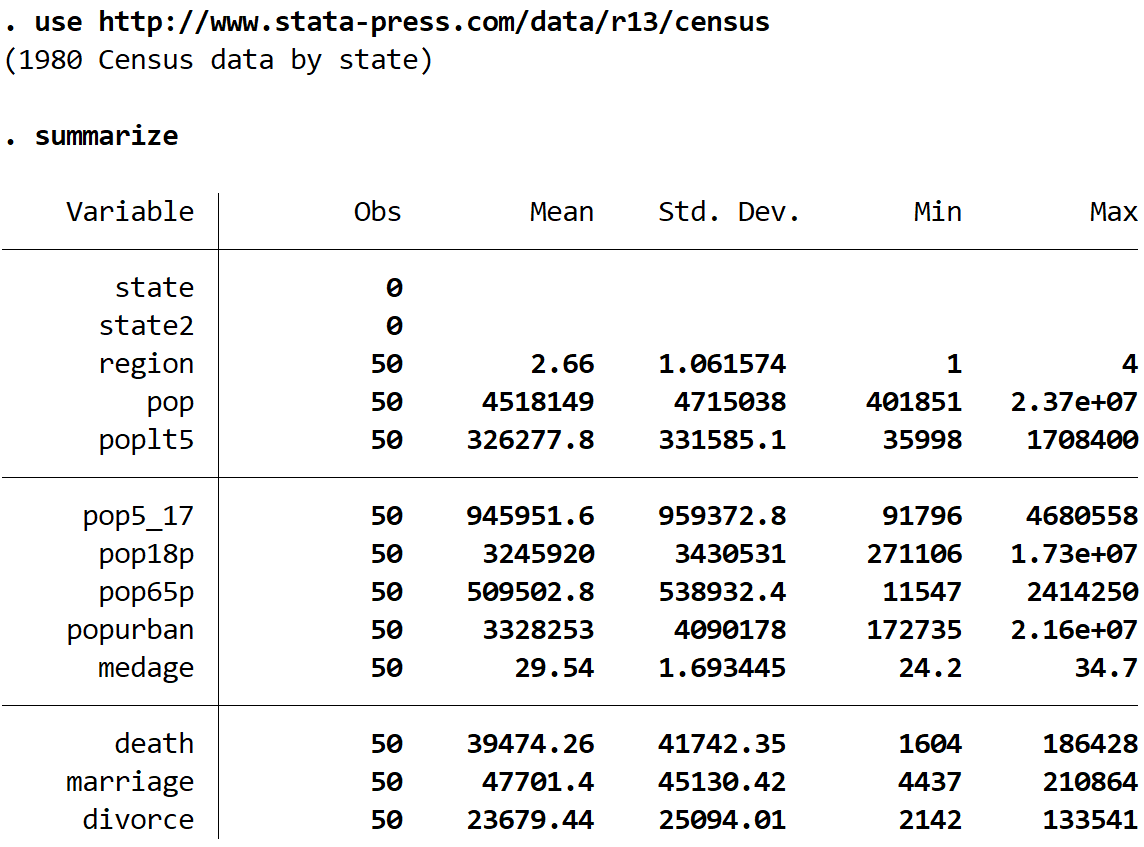
Получите краткую сводку набора данных с помощью следующей команды:
подвести итог
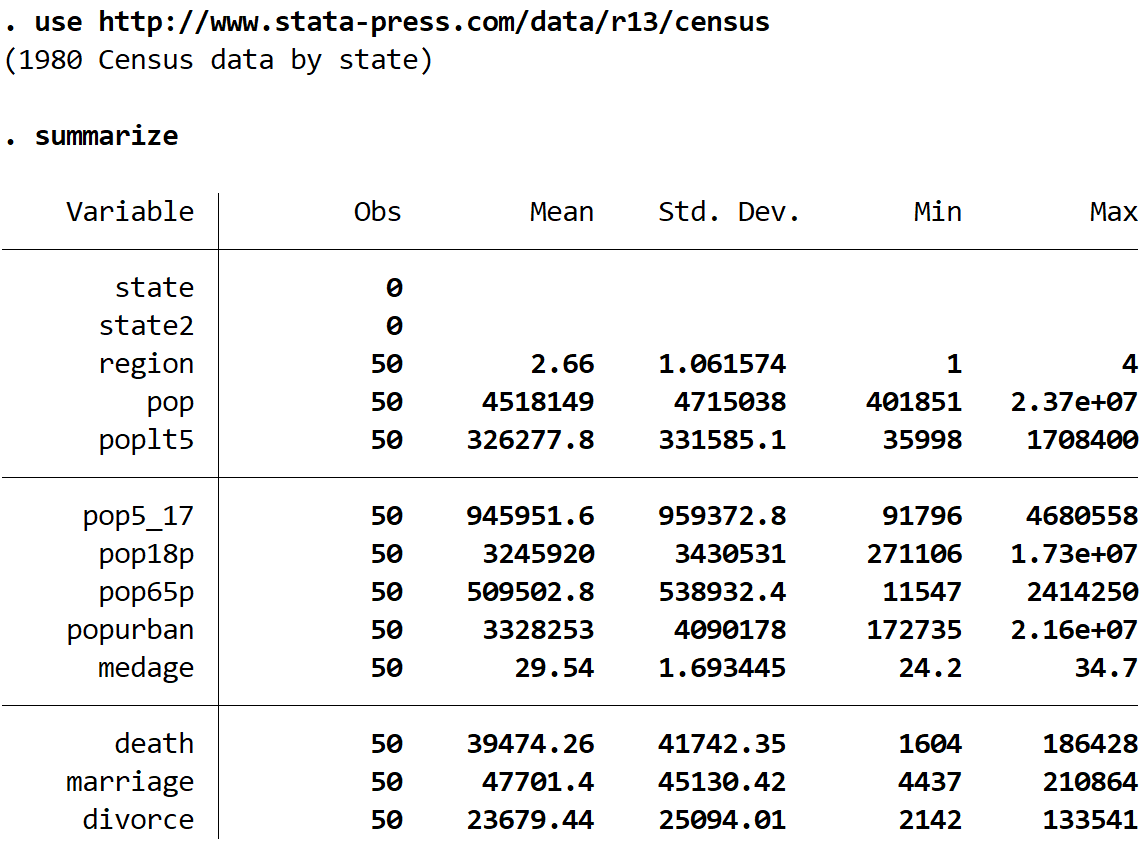
Мы видим, что в этом наборе данных есть 13 различных переменных, но мы будем работать только с двумя — это medage (средний возраст) и регион .
Шаг 2: Визуализируйте данные.
Прежде чем мы выполним тест Крускала-Уоллиса, давайте сначала создадим несколько блочных диаграмм , чтобы визуализировать распределение медианного возраста для каждого из четырех регионов:
Медиа графического окна, более (регион)
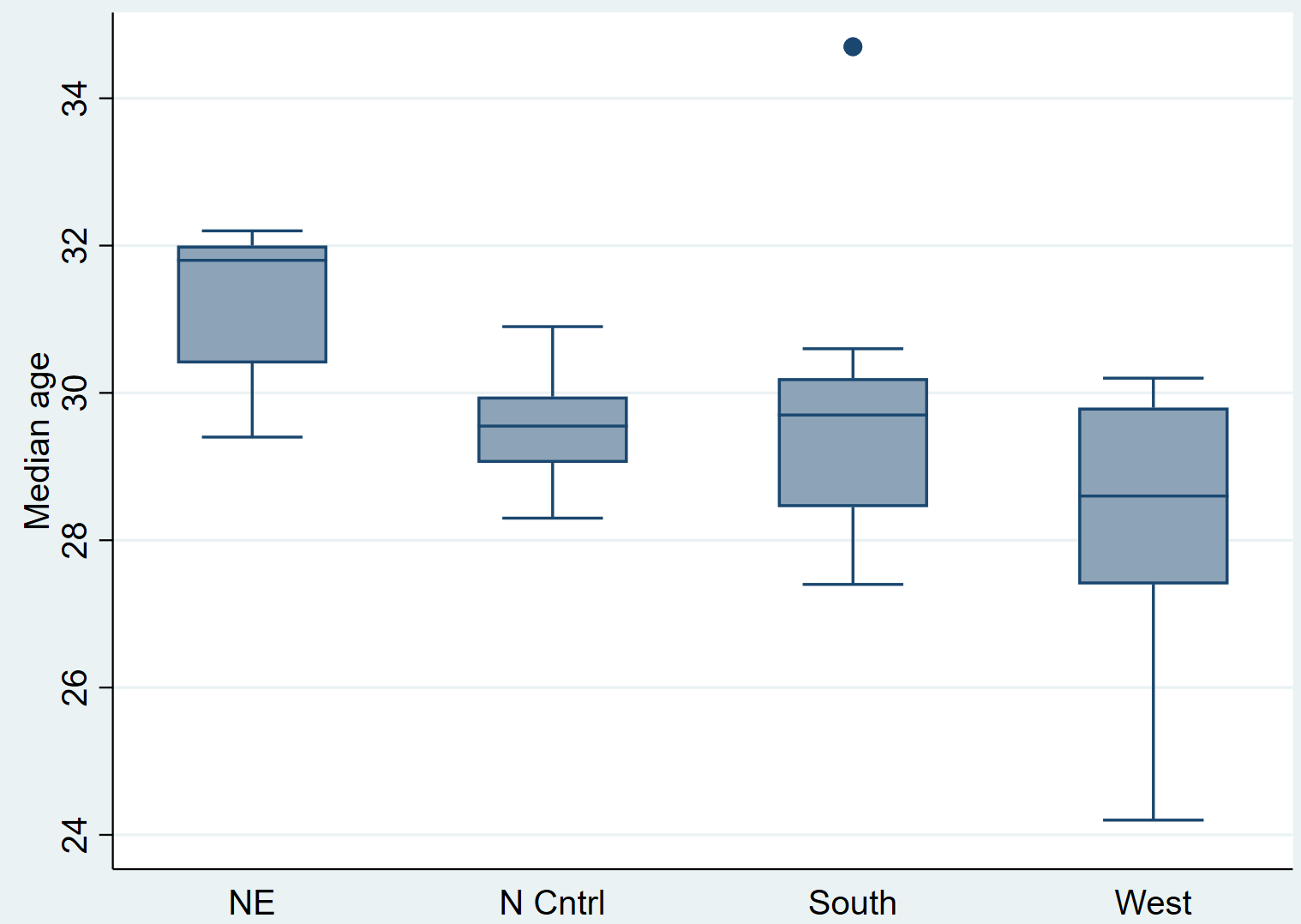
Просто взглянув на диаграммы, мы можем увидеть, что распределения варьируются между регионами. Далее мы проведем тест Крускала-Уоллиса, чтобы увидеть, являются ли эти различия статистически значимыми.
Шаг 3: Проведите тест Крускала-Уоллиса.
Используйте следующий синтаксис для выполнения теста Крускала-Уоллиса:
kwallis переменная_измерения, по (переменная_группировки)
В нашем случае мы будем использовать следующий синтаксис:
kwallis medage, автор(регион)
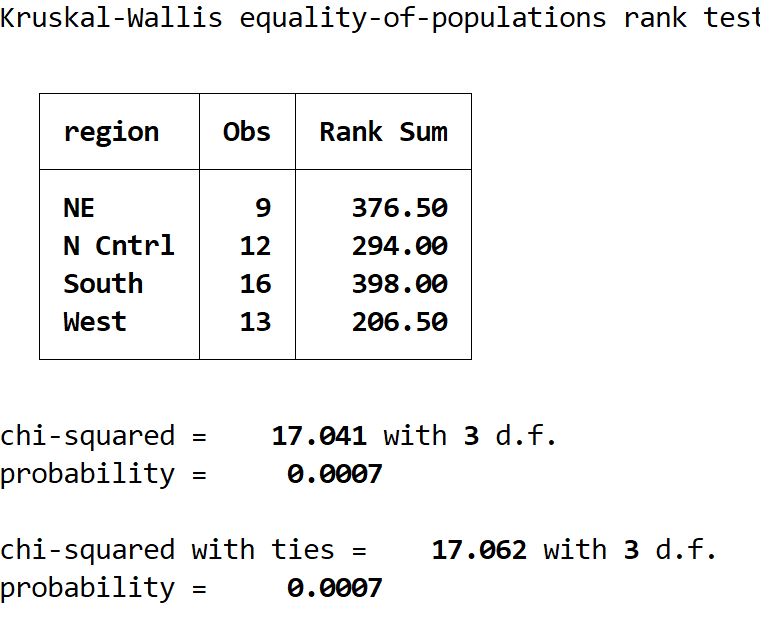
Вот как интерпретировать вывод:
Сводная таблица. В этой таблице показано количество наблюдений по регионам и суммы рангов для каждого региона.
Хи-квадрат со связями: это значение тестовой статистики, которое оказывается равным 17,062.
вероятность: это p-значение, соответствующее тестовой статистике, которая оказывается равной 0,0007. Поскольку это значение меньше 0,05, мы можем отклонить нулевую гипотезу и сделать вывод, что средний возраст не одинаков в четырех регионах.
Шаг 4: Сообщите о результатах.
Наконец, мы хотим сообщить о результатах теста Крускала-Уоллиса. Вот пример того, как это сделать:
Был проведен тест Крускала-Уоллиста, чтобы определить, был ли средний возраст людей одинаковым в следующих четырех регионах США:
- Северо-восток (n = 9)
- Северо-Центральный (n = 12)
- Юг (n = 16)
- Запад (n = 13)
Тест показал, что средний возраст людей не был одинаковым (X 2 =17,062, p = 0,0007) в четырех регионах. То есть имелась статистически значимая разница в среднем возрасте между двумя или более регионами.