Чтобы оценить производительность модели в наборе данных, нам нужно измерить, насколько хорошо прогнозы, сделанные моделью, соответствуют наблюдаемым данным.
Наиболее распространенный способ измерить это — использовать среднеквадратичную ошибку (MSE), которая рассчитывается как:
MSE = (1/n)*Σ(y i – f(x i )) 2
куда:
- n: общее количество наблюдений
- y i : значение отклика i -го наблюдения
- f(x i ): прогнозируемое значение отклика i -го наблюдения.
Чем ближе прогнозы модели к наблюдениям, тем меньше будет MSE.
На практике мы используем следующий процесс для расчета MSE данной модели:
1. Разделите набор данных на обучающий набор и набор для тестирования.
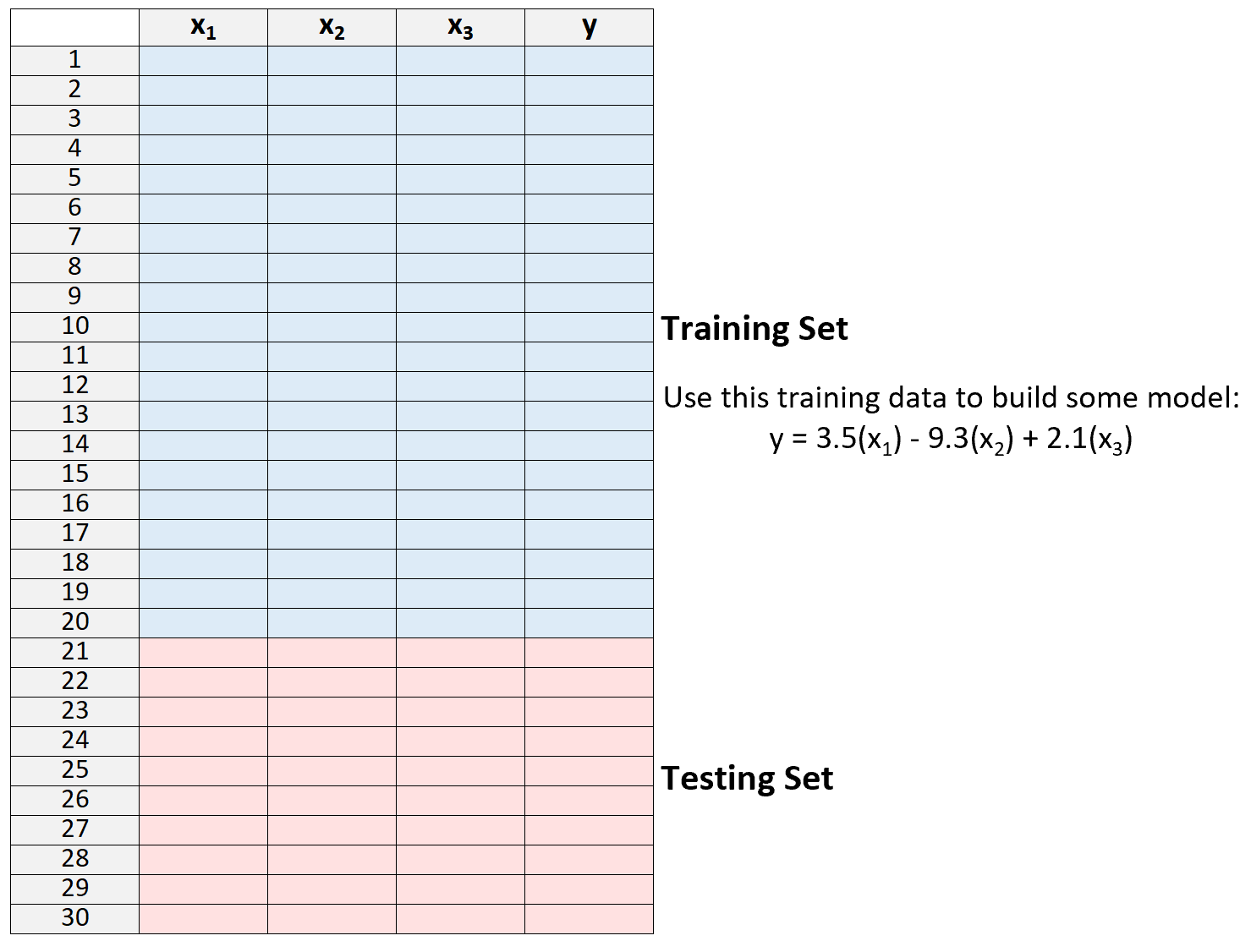
2. Построить модель, используя только данные из обучающей выборки.
3. Используйте модель, чтобы делать прогнозы на тестовом наборе и измерять MSE — это известно как тестовая MSE .
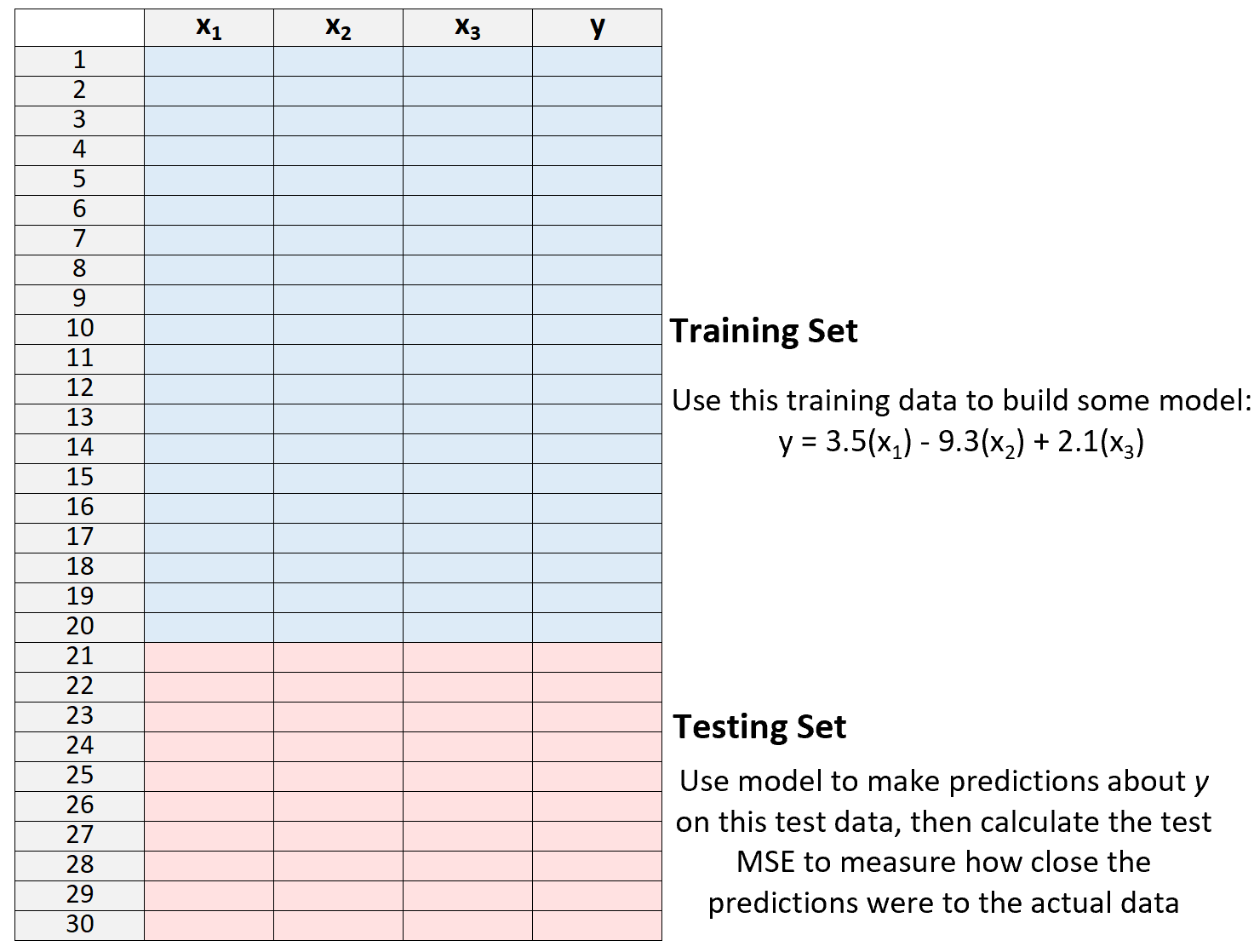
Тестовая MSE дает нам представление о том, насколько хорошо модель будет работать с данными, которые она ранее не видела, т. е. с данными, которые не использовались для «обучения» модели.
Однако недостатком использования только одного тестового набора является то, что тестовая MSE может сильно различаться в зависимости от того, какие наблюдения использовались в обучающем и тестовом наборах.
Вполне возможно, что если мы будем использовать разные наборы наблюдений для обучающего набора и тестового набора, то наша тестовая MSE может оказаться намного больше или меньше.
Один из способов избежать этой проблемы — подобрать модель несколько раз, используя каждый раз другой набор для обучения и тестирования, а затем вычислить тестовую MSE как среднее значение всех тестовых MSE.
Этот общий метод известен как перекрестная проверка, а его конкретная форма известна как перекрестная проверка с исключением одного .
Перекрестная проверка с исключением одного
Перекрестная проверка с исключением одного использует следующий подход для оценки модели:
1. Разделите набор данных на обучающий набор и тестовый набор, используя все наблюдения, кроме одного, как часть обучающего набора:
Обратите внимание, что мы оставляем только одно наблюдение «вне» обучающего набора. Именно здесь метод получает название «перекрестная проверка с исключением одного».
2. Построить модель, используя только данные из обучающей выборки.
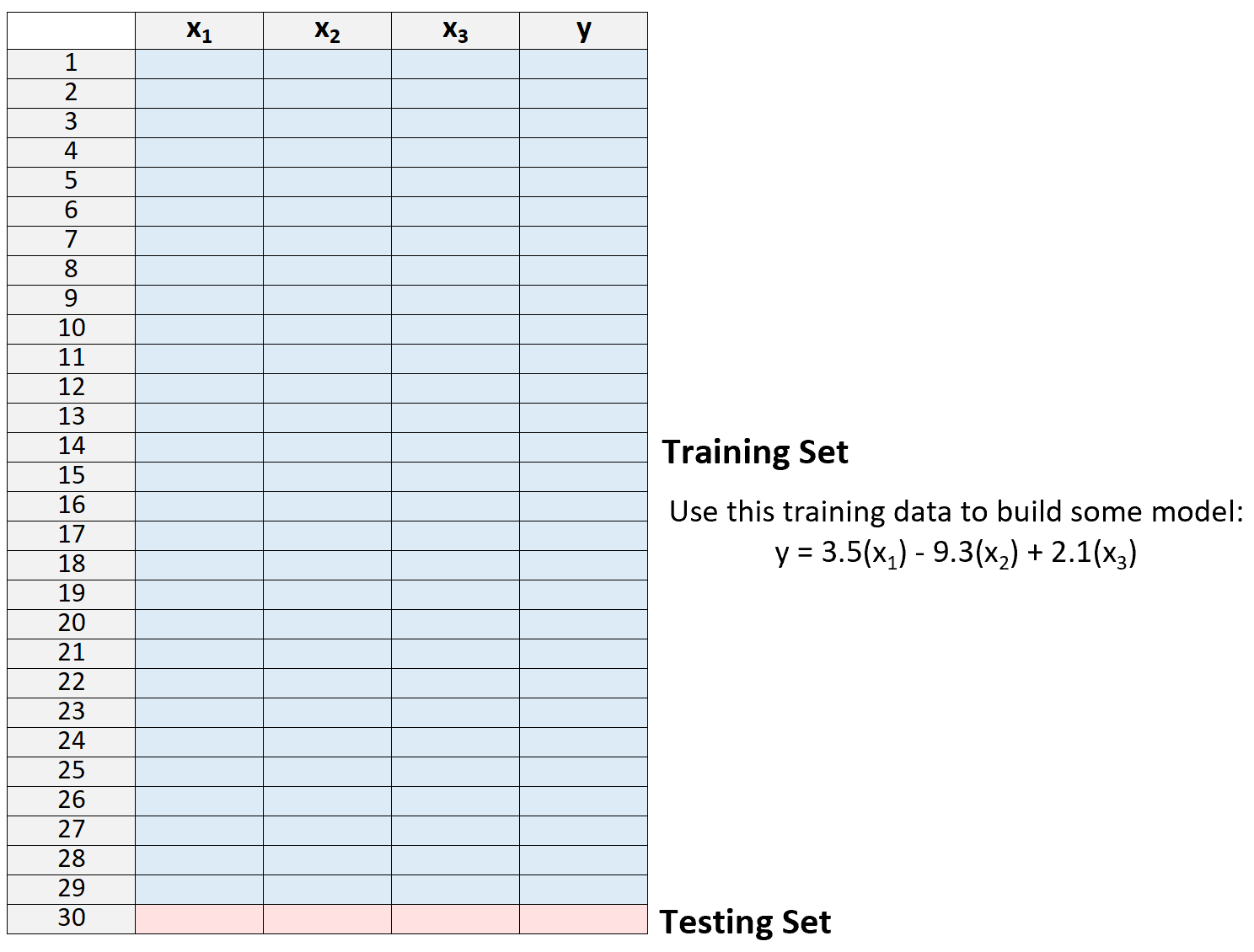
3. Используйте модель, чтобы предсказать значение отклика одного наблюдения, не включенного в модель, и вычислить MSE.
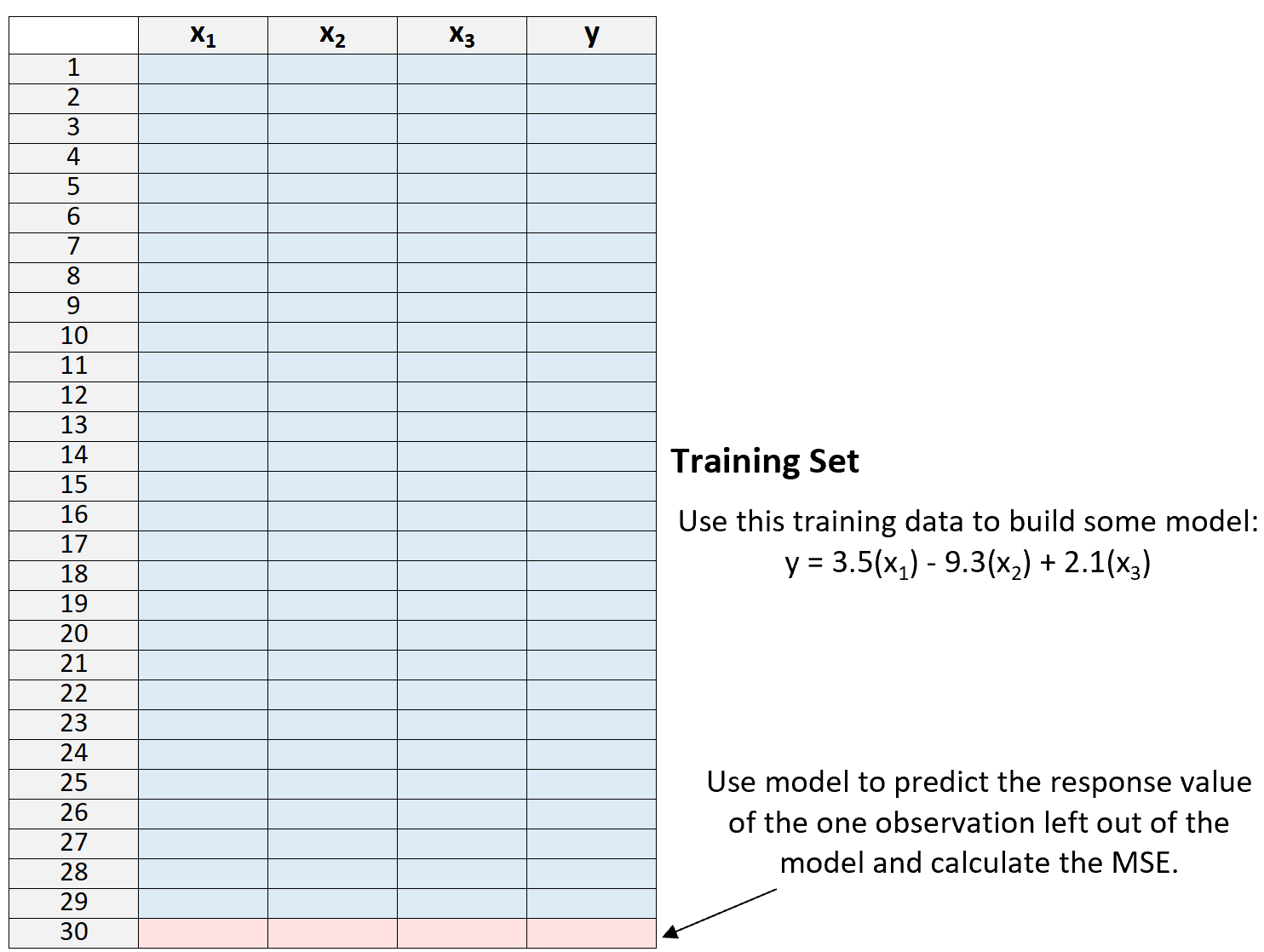
4. Повторите процесс n раз.
Наконец, мы повторяем этот процесс n раз (где n — общее количество наблюдений в наборе данных), каждый раз исключая разные наблюдения из обучающего набора.
Затем мы вычисляем тестовую MSE как среднее значение всех тестовых MSE:
СКО теста = (1/n)*ΣСКО i
куда:
- n: общее количество наблюдений в наборе данных.
- MSEi: тестовая MSE во время i -го времени подгонки модели.
Плюсы и минусы LOOCV
Перекрестная проверка с исключением одного предлагает следующие плюсы :
- Он обеспечивает гораздо менее предвзятую меру тестовой MSE по сравнению с использованием одного тестового набора, потому что мы неоднократно подгоняем модель к набору данных, который содержит n-1 наблюдений.
- Он имеет тенденцию не переоценивать тест MSE по сравнению с использованием одного набора тестов.
Однако перекрестная проверка с исключением одного имеет следующие недостатки:
- Это может занять много времени, если n велико.
- Это также может занять много времени, если модель особенно сложна и требует много времени, чтобы соответствовать набору данных.
- Это может быть дорого в вычислительном отношении.
К счастью, современные вычисления стали настолько эффективными в большинстве областей, что LOOCV является гораздо более разумным методом для использования по сравнению с тем, что было много лет назад.
Обратите внимание, что LOOCV можно использовать как в настройках регрессии, так и в настройках классификации.Для задач регрессии он вычисляет тестовую MSE как среднеквадратичную разницу между прогнозами и наблюдениями, тогда как в задачах классификации он вычисляет тестовую MSE как процент правильно классифицированных наблюдений во время n повторных подборов модели.
Как выполнить LOOCV в R и Python
В следующих руководствах представлены пошаговые примеры выполнения LOOCV для заданной модели в R и Python.
Перекрестная проверка с исключением одного в R
Перекрестная проверка с исключением одного в Python