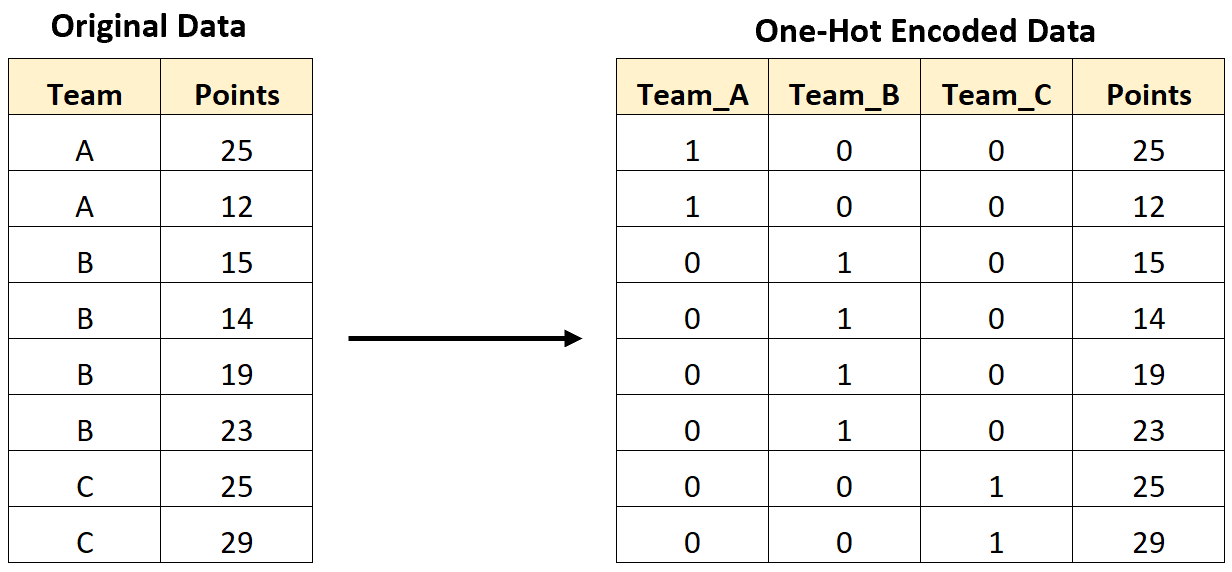
Горячее кодирование используется для преобразования категориальных переменных в формат, который может быть легко использован алгоритмами машинного обучения .
Основная идея горячего кодирования заключается в создании новых переменных, которые принимают значения 0 и 1 для представления исходных категориальных значений.
Например, на следующем изображении показано, как мы можем выполнить однократное кодирование для преобразования категориальной переменной, содержащей названия команд, в новые переменные, содержащие только значения 0 и 1:

В следующем пошаговом примере показано, как выполнить однократное кодирование для этого точного набора данных в Python.
Шаг 1: Создайте данные
Во-первых, давайте создадим следующий DataFrame pandas:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'],
'points': [25, 12, 15, 14, 19, 23, 25, 29]})
#view DataFrame
print(df)
team points
0 A 25
1 A 12
2 B 15
3 B 14
4 B 19
5 B 23
6 C 25
7 C 29
Шаг 2. Выполните горячее кодирование
Затем давайте импортируем функцию OneHotEncoder() из библиотеки sklearn и используем ее для выполнения однократного кодирования переменной «team» в кадре данных pandas:
from sklearn. preprocessing import OneHotEncoder
#creating instance of one-hot-encoder
encoder = OneHotEncoder(handle_unknown='ignore')
#perform one-hot encoding on 'team' column
encoder_df = pd.DataFrame(encoder. fit_transform(df[['team']]). toarray ())
#merge one-hot encoded columns back with original DataFrame
final_df = df.join (encoder_df)
#view final df
print(final_df)
team points 0 1 2
0 A 25 1.0 0.0 0.0
1 A 12 1.0 0.0 0.0
2 B 15 0.0 1.0 0.0
3 B 14 0.0 1.0 0.0
4 B 19 0.0 1.0 0.0
5 B 23 0.0 1.0 0.0
6 C 25 0.0 0.0 1.0
7 C 29 0.0 0.0 1.0
Обратите внимание, что в DataFrame были добавлены три новых столбца, поскольку исходный столбец «команда» содержал три уникальных значения.
Примечание.Полную документацию по функции OneHotEncoder() можно найти здесь .
Шаг 3: Отбросьте исходную категориальную переменную
Наконец, мы можем удалить исходную переменную team из DataFrame, так как она нам больше не нужна:
#drop 'team' column
final_df.drop('team', axis= 1 , inplace= True )
#view final df
print(final_df)
points 0 1 2
0 25 1.0 0.0 0.0
1 12 1.0 0.0 0.0
2 15 0.0 1.0 0.0
3 14 0.0 1.0 0.0
4 19 0.0 1.0 0.0
5 23 0.0 1.0 0.0
6 25 0.0 0.0 1.0
7 29 0.0 0.0 1.0
Связанный: Как удалить столбцы в Pandas (методы 4)
Мы также могли бы переименовать столбцы окончательного DataFrame, чтобы их было легче читать:
#rename columns
final_df.columns = ['points', 'teamA', 'teamB', 'teamC']
#view final df
print(final_df)
points teamA teamB teamC
0 25 1.0 0.0 0.0
1 12 1.0 0.0 0.0
2 15 0.0 1.0 0.0
3 14 0.0 1.0 0.0
4 19 0.0 1.0 0.0
5 23 0.0 1.0 0.0
6 25 0.0 0.0 1.0
7 29 0.0 0.0 1.0
Горячее кодирование завершено, и теперь мы можем передать этот кадр данных pandas в любой алгоритм машинного обучения, который нам нужен.
Дополнительные ресурсы
Как вычислить усеченное среднее в Python
Как выполнить линейную регрессию в Python
Как выполнить логистическую регрессию в Python