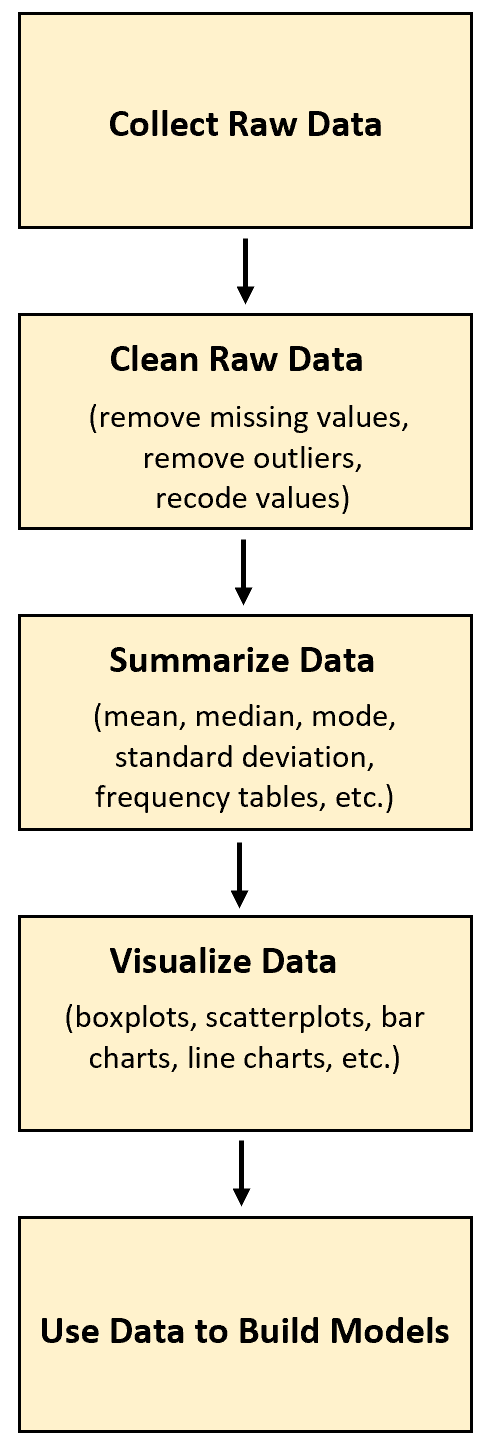
В статистике необработанные данные — это данные, собранные непосредственно из первоисточника и никаким образом не обработанные.
В любом проекте анализа данных первым шагом является сбор необработанных данных. После того, как эти данные собраны, их можно очистить, преобразовать, обобщить и визуализировать.
Весь смысл сбора необработанных данных заключается в том, чтобы в конечном итоге использовать их для лучшего понимания некоторых явлений или использовать их для построения какой-либо прогностической модели.
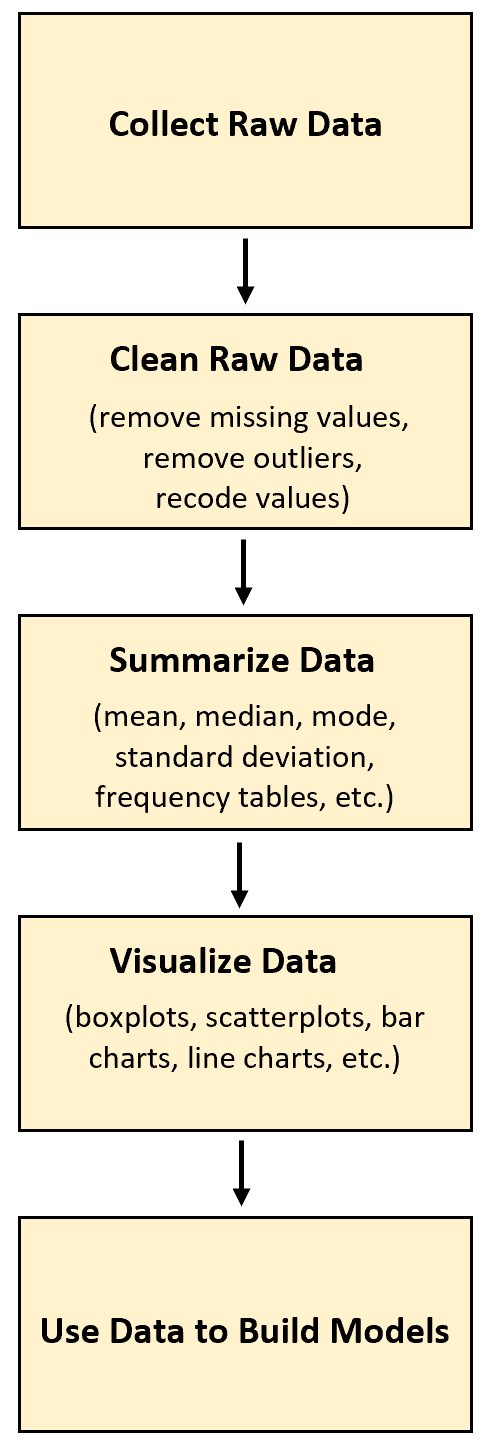
В следующем примере показано, как необработанные данные можно собирать и использовать в реальной жизни.
Пример: сбор и использование необработанных данных
Одной из областей, в которой часто собираются необработанные данные, является спорт. Например, необработанные данные могут быть собраны для различных статистических данных о профессиональных баскетболистах.
Шаг 1: Соберите необработанные данные
Представьте, что баскетбольный скаут собирает следующие необработанные данные для 10 игроков профессиональной баскетбольной команды:
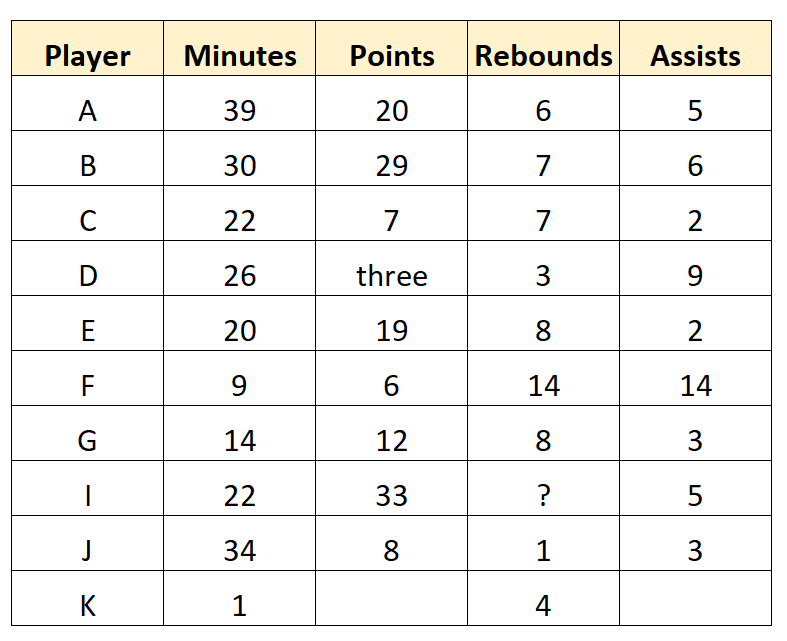
Этот набор данных представляет собой необработанные данные , поскольку они собираются непосредственно разведчиком и не очищались и не обрабатывались каким-либо образом.
Шаг 2: Очистите необработанные данные
Прежде чем использовать эти данные для создания сводных таблиц, диаграмм или чего-либо еще, скаут сначала удалит все отсутствующие значения и очистит все «грязные» значения данных.
Например, мы можем обнаружить в наборе данных несколько значений, которые необходимо преобразовать или удалить:
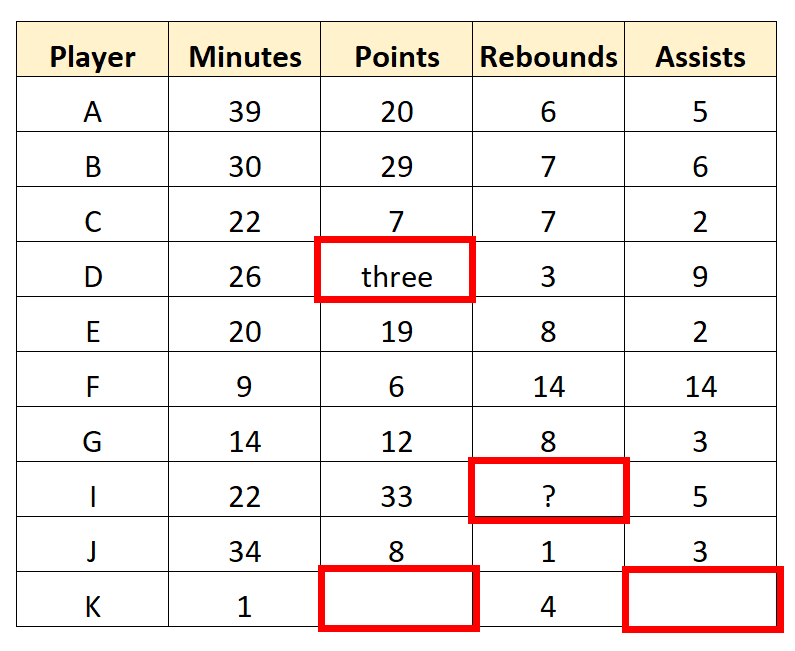
Разведчик может решить полностью удалить последнюю строку, поскольку в ней есть несколько пропущенных значений. Затем он может также очистить значения символов в наборе данных, чтобы получить следующие «чистые» данные:
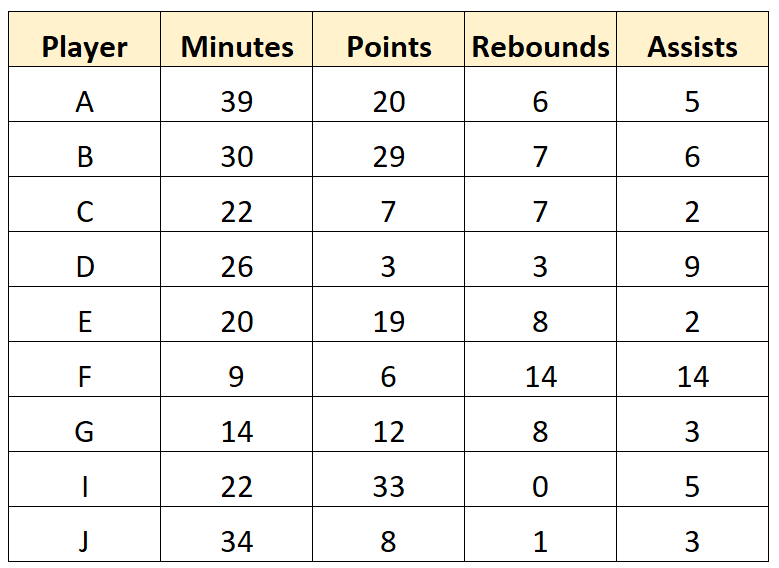
Шаг 3: Суммируйте данные
После очистки данных разведчик может обобщить каждую переменную в наборе данных. Например, он мог рассчитать следующую сводную статистику для переменной «Минуты»:
- Среднее значение : 24 минуты
- Медиана : 22 минуты
- Стандартное отклонение : 9,45 минут
Шаг 4: Визуализируйте данные
Затем разведчик может визуализировать переменные в наборе данных, чтобы лучше понять значения данных.
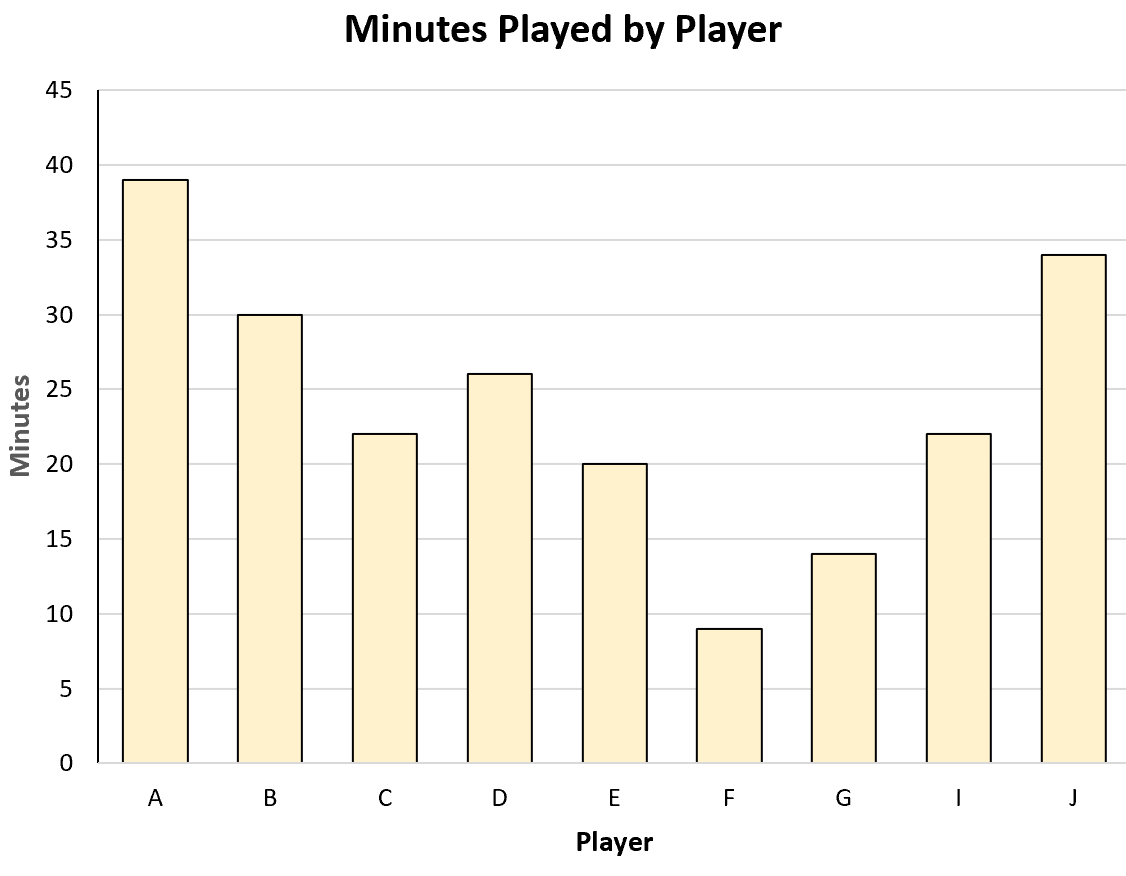
Например, он может создать следующую гистограмму, чтобы визуализировать общее количество минут, сыгранных каждым игроком:
Или он мог построить следующую диаграмму рассеяния, чтобы визуализировать взаимосвязь между сыгранными минутами и набранными очками:
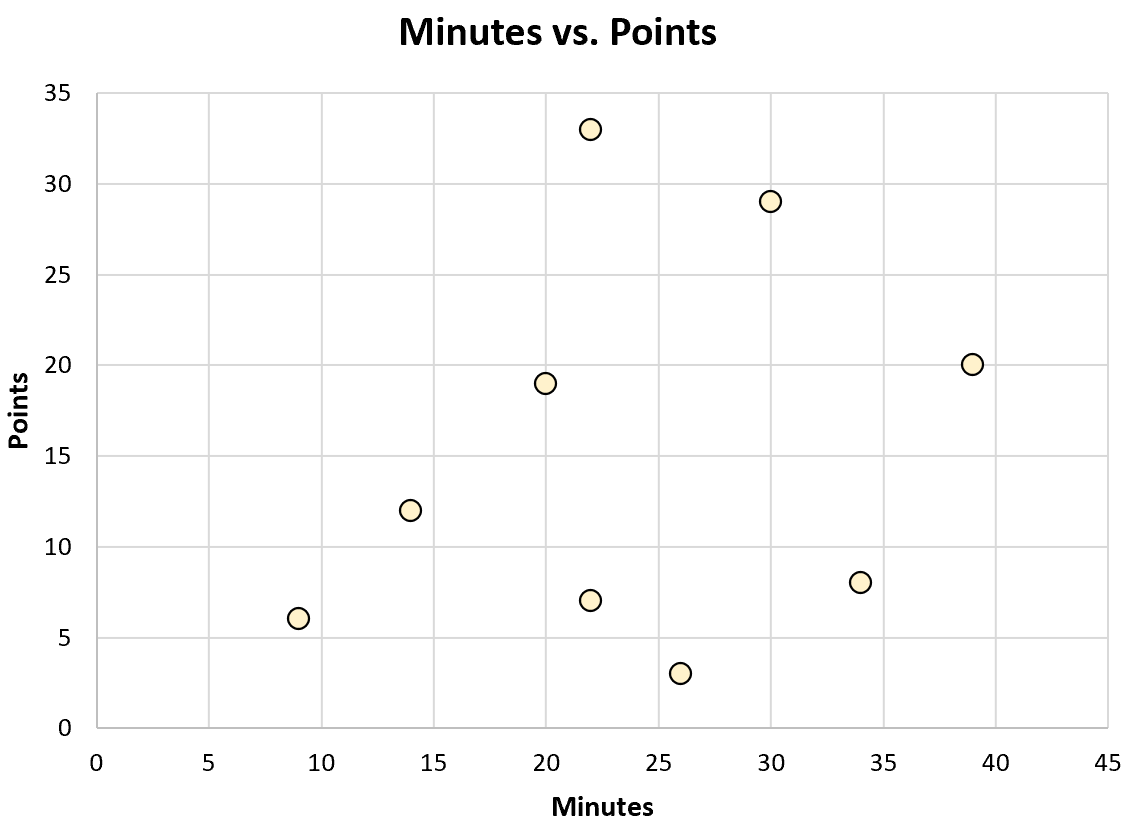
Каждый из этих типов диаграмм может помочь ему понять данные.
Шаг 5: Используйте данные для построения модели
Наконец, после того, как данные были очищены, скаут может принять решение о применении какой-либо прогностической модели.
Например, он может подобрать простую модель линейной регрессии и использовать количество сыгранных минут для прогнозирования общего количества очков, набранных каждым игроком.
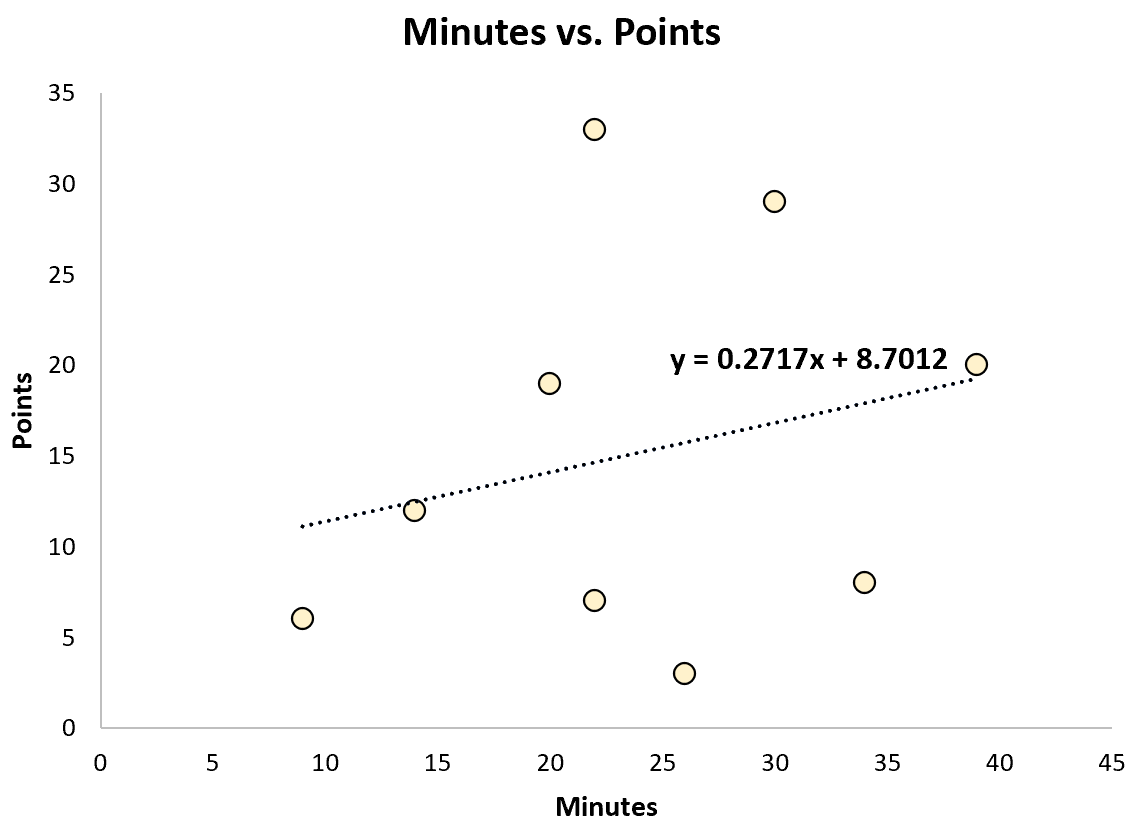
Подходящее уравнение регрессии:
Очки = 8,7012 + 0,2717 * (минуты)
Затем скаут может использовать это уравнение, чтобы предсказать количество очков, которое наберет игрок, исходя из количества сыгранных минут. Например, прогнозируется, что спортсмен, который играет 30 минут, наберет 16,85 балла:
Баллы = 8,7012 + 0,2717 * (30) = 16,85.
Дополнительные ресурсы
Почему важна статистика?
Почему размер выборки важен в статистике?
Что такое наблюдение в статистике?
Что такое табличные данные в статистике?