Вы можете использовать следующий базовый синтаксис для выбора наблюдений в наборе данных в SAS, где определенное значение столбца не равно нулю:
/\*select only rows where var1 is not null\*/
proc sql ;
select \*
from my_data1
where not missing(var1);
quit ;
В следующем примере показано, как использовать этот синтаксис на практике.
Пример: выберите наблюдения, которые не являются нулевыми в SAS
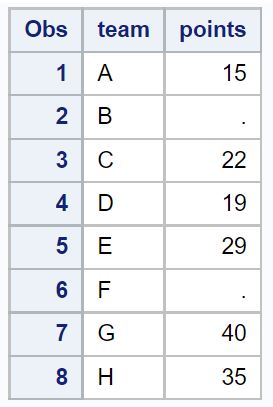
Предположим, у нас есть следующий набор данных в SAS:
/\*create dataset\*/
data my_data1;
input team $ points;
datalines ;
A 15
B .
C 22
D 19
E 29
F .
G 40
H 35
;
run;
/\*view dataset\*/
proc print data =my_data1;
Обратите внимание, что в столбце точек есть некоторые нулевые значения.
Мы можем использовать следующий код, чтобы выбрать все строки, где значение в столбце точек не равно нулю:
/\*select only rows where points is not blank\*/
proc sql ;
select \*
from my_data1
where not missing(points);
quit ;
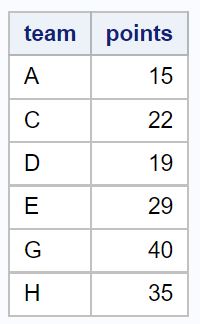
Обратите внимание, что возвращаются только строки, в которых значение в столбце точек не равно нулю.
Обратите внимание, что вы также можете использовать функцию count() в proc sql для подсчета количества наблюдений, где значение в столбце точек не равно нулю:
/\*count rows where points is not blank\*/
proc sql ;
select count(\*)
from my_data1
where not missing(points);
quit ;
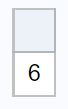
Это говорит нам о том, что 6 наблюдений в наборе данных имеют ненулевое значение в столбце точек .
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в SAS:
Как нормализовать данные в SAS
Как переименовать переменные в SAS
Как удалить дубликаты в SAS
Как заменить пропущенные значения нулем в SAS