Многие статистические тесты предполагают, что наборы данных обычно распределяются. Однако на практике это часто не так.
Одним из способов решения этой проблемы является преобразование распределения значений в наборе данных с помощью одного из трех преобразований:
1. Преобразование журнала: преобразование переменной ответа из y в log(y) .
2. Преобразование квадратного корня: преобразовать переменную отклика из y в √ y .
3. Преобразование кубического корня: преобразовать переменную ответа из y в y 1/3 .
Выполняя эти преобразования, набор данных обычно становится более нормально распределенным.
В следующих примерах показано, как выполнять эти преобразования в Python.
Преобразование журнала в Python
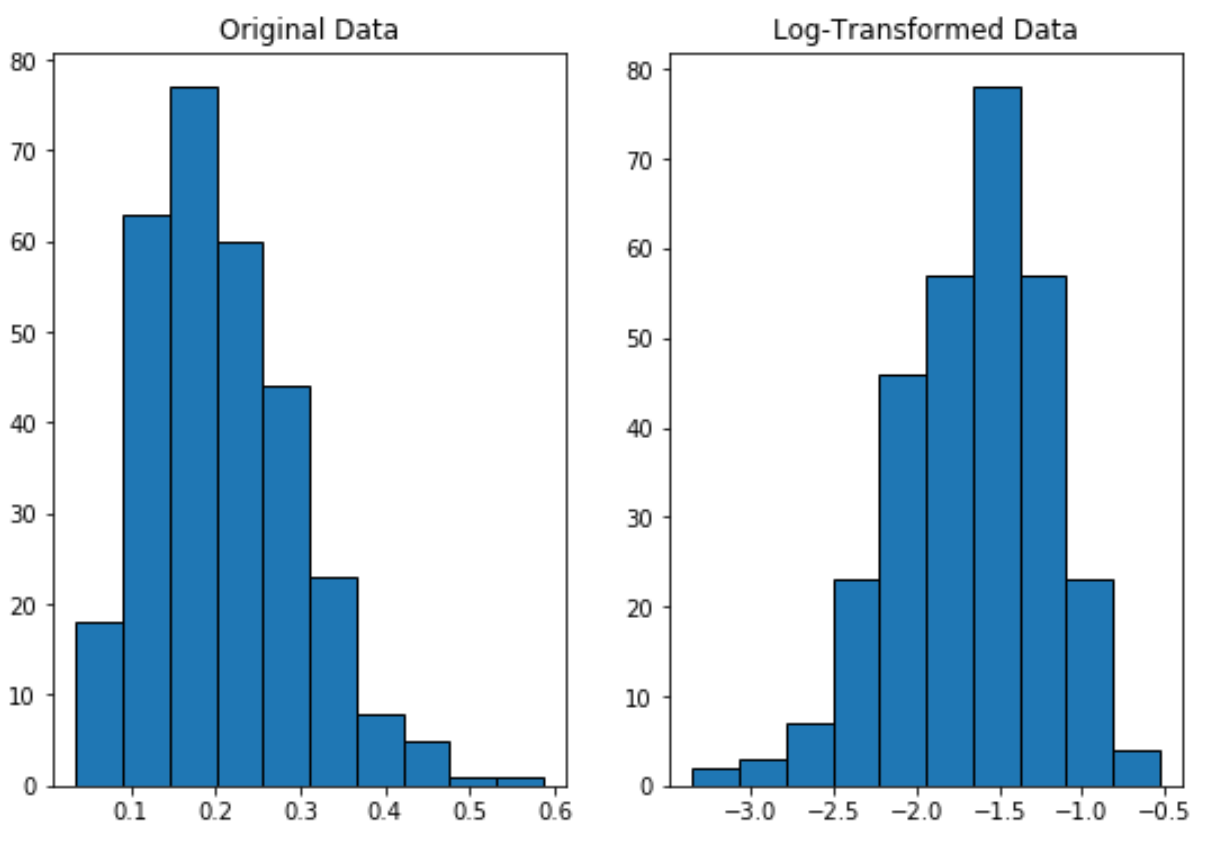
В следующем коде показано, как выполнить логарифмическое преобразование переменной и создать параллельные графики для просмотра исходного распределения и логарифмически преобразованного распределения данных:
import numpy as np
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed (0)
#create beta distributed random variable with 200 values
data = np.random.beta (a= 4 , b= 15 , size= 300 )
#create log-transformed data
data_log = np.log (data)
#define grid of plots
fig, axs = plt.subplots(nrows= 1 , ncols= 2 )
#create histograms
axs[0]. hist (data, edgecolor='black')
axs[1]. hist (data_log, edgecolor='black')
#add title to each histogram
axs[0].set_title('Original Data')
axs[1].set_title('Log-Transformed Data')
Обратите внимание, что дистрибутив с логарифмическим преобразованием распределяется более нормально по сравнению с исходным дистрибутивом.
Это все еще не идеальная «форма колокола», но оно ближе к нормальному распределению, чем исходное распределение.
Преобразование квадратного корня в Python
В следующем коде показано, как выполнить преобразование квадратного корня для переменной и создать параллельные графики для просмотра исходного распределения и распределения данных, преобразованного из квадратного корня:
import numpy as np
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed (0)
#create beta distributed random variable with 200 values
data = np.random.beta (a= 1 , b= 5 , size= 300 )
#create log-transformed data
data_log = np.sqrt (data)
#define grid of plots
fig, axs = plt.subplots(nrows= 1 , ncols= 2 )
#create histograms
axs[0]. hist (data, edgecolor='black')
axs[1]. hist (data_log, edgecolor='black')
#add title to each histogram
axs[0].set_title('Original Data')
axs[1].set_title('Square Root Transformed Data')
Обратите внимание, что данные преобразования квадратного корня распределены более нормально, чем исходные данные.
Преобразование кубического корня в Python
В следующем коде показано, как выполнить преобразование кубического корня для переменной и создать параллельные графики для просмотра исходного распределения и распределения данных, преобразованного в кубический корень:
import numpy as np
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed (0)
#create beta distributed random variable with 200 values
data = np.random.beta (a= 1 , b= 5 , size= 300 )
#create log-transformed data
data_log = np.cbrt (data)
#define grid of plots
fig, axs = plt.subplots(nrows= 1 , ncols= 2 )
#create histograms
axs[0]. hist (data, edgecolor='black')
axs[1]. hist (data_log, edgecolor='black')
#add title to each histogram
axs[0].set_title('Original Data')
axs[1].set_title('Cube Root Transformed Data')
Обратите внимание, что данные, преобразованные с помощью кубического корня, распределяются гораздо более нормально, чем исходные данные.
Дополнительные ресурсы
Как рассчитать Z-показатели в Python
Как нормализовать данные в Python
Что такое предположение о нормальности в статистике?