Предположим, мы проводим опрос, в ходе которого опрашиваем 15 домохозяйств, сколько домашних животных у них дома. Результаты приведены ниже:
1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 7, 8
Один из способов обобщить эти результаты — создать частотное распределение , которое говорит нам, как часто разные значения встречаются в наборе данных.
Часто мы используем сгруппированные частотные распределения , в которых мы создаем группы значений, а затем суммируем, сколько наблюдений из набора данных попадает в эти группы.
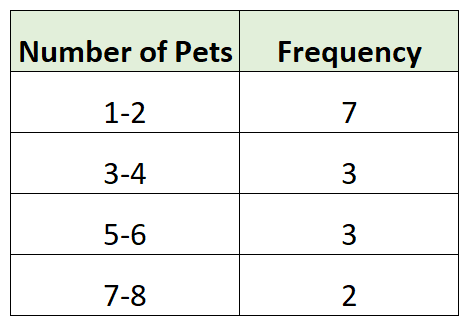
Вот пример сгруппированного частотного распределения для данных нашего опроса:
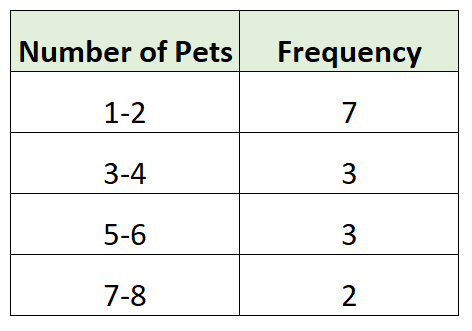
Сначала мы создали группы размером 2, затем подсчитали, сколько отдельных наблюдений из набора данных попало в каждую группу. Например:
- 7 семей имели 1 или 2 домашних животных
- В 3 семьях было 3 или 4 домашних животных
- В 3 семьях было 5 или 6 домашних животных.
- В 2 семьях было 7 или 8 домашних животных.
Другой тип частотного распределения, который мы могли бы создать, — это несгруппированное частотное распределение , которое отображает частоту каждого отдельного значения данных, а не группы значений данных.
Вот пример несгруппированного частотного распределения для данных нашего опроса:
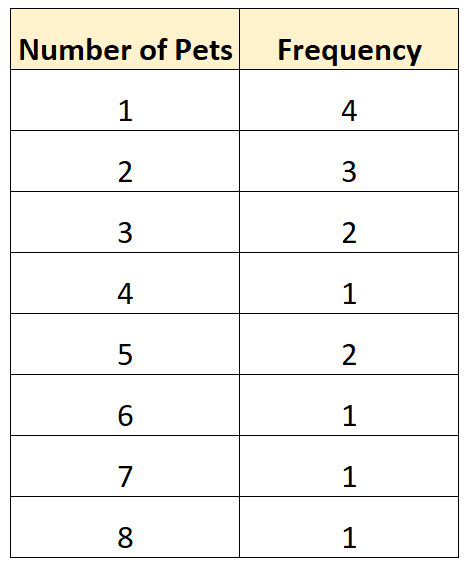
Этот тип частотного распределения позволяет нам напрямую видеть, как часто в нашем наборе данных встречались разные значения. Например:
- 4 семьи имели 1 домашнее животное
- 3 семьи имели 2 домашних животных
- 2 семьи имели 3 домашних животных
- В 1 семье было 4 питомца
И так далее.
Когда использовать несгруппированные частотные распределения
Несгруппированные частотные распределения могут быть полезны, когда вы хотите увидеть, как часто каждое отдельное значение встречается в наборе данных.
Обратите внимание, что разгруппированные частотные распределения лучше всего работают с небольшими наборами данных, в которых есть только несколько уникальных значений.
Например, в данных нашего предыдущего опроса было только 8 уникальных значений, поэтому имело смысл создать негруппированное частотное распределение.
Однако, если бы у нас был набор данных с сотнями или тысячами уникальных значений, негруппированное частотное распределение было бы невероятно длинным и из него было бы трудно собрать информацию.
Для больших наборов данных имеет смысл построить сгруппированные частотные распределения.
Как визуализировать несгруппированные частотные распределения
Самый простой способ визуализировать значения в несгруппированном распределении частот — создать многоугольник частот , который отображает частоты каждого отдельного значения в простой диаграмме.
Вот как будет выглядеть полигон частот для наших выборочных данных:
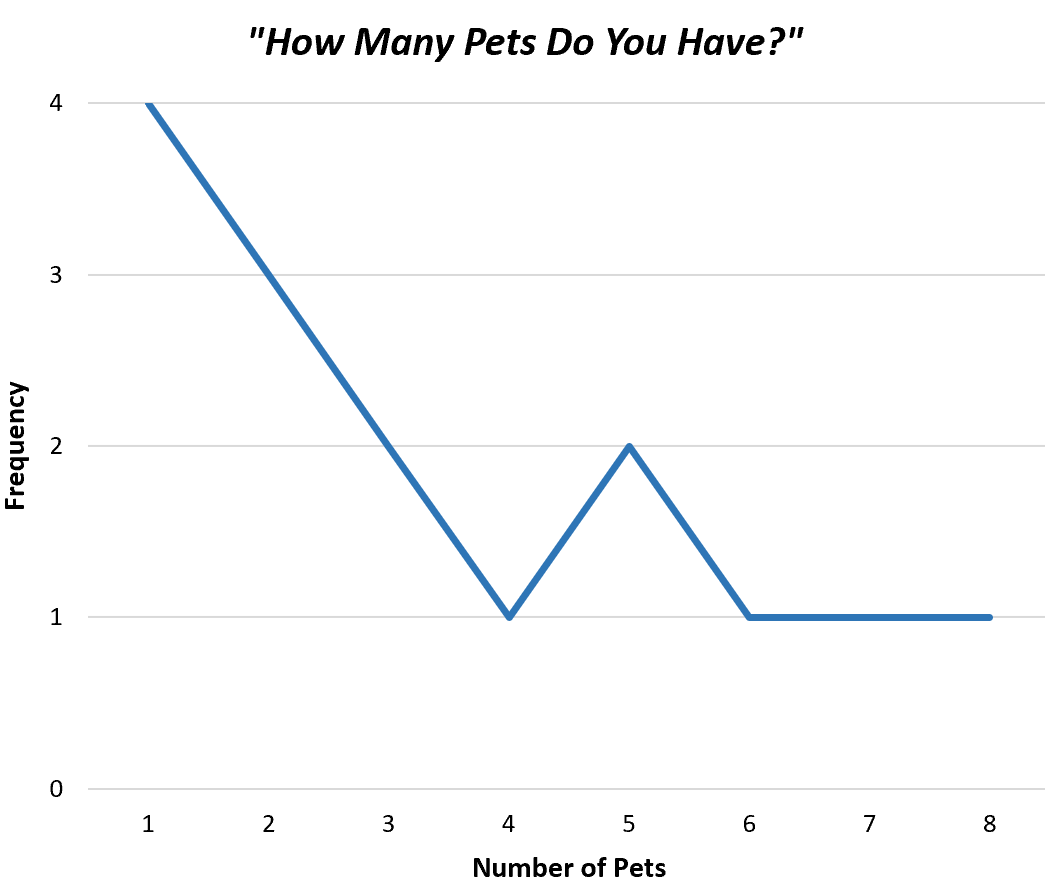
Это помогает нам быстро понять, как часто каждое значение встречается в наборе данных.
В качестве альтернативы мы могли бы создать гистограмму для отображения тех же данных, используя столбцы, а не одну линию:
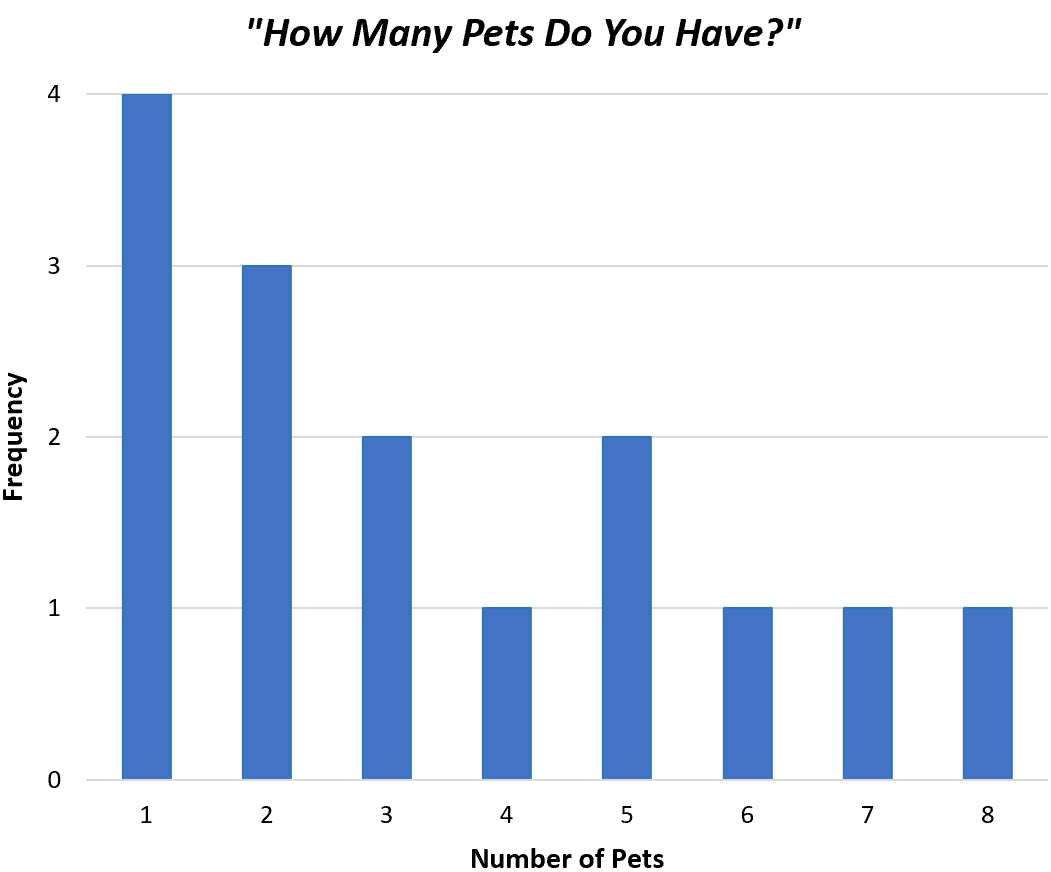
Обе диаграммы позволяют нам быстро понять распределение значений в нашем наборе данных.