Хи-квадрат критерий согласия используется для определения того, следует ли категориальная переменная гипотетическому распределению.
В этом учебном пособии объясняется, как выполнить критерий согласия хи-квадрат в Stata.
Пример: критерий согласия хи-квадрат в Stata
Чтобы проиллюстрировать, как выполнить этот тест, мы будем использовать набор данных под названием nlsw88 , который содержит информацию о статистике труда женщин в США в 1988 году.
Выполните следующие шаги, чтобы выполнить тест Хи-квадрат согласия, чтобы определить, является ли истинное распределение расы в этом наборе данных следующим: 70% белых, 20% черных, 10% других.
Шаг 1: Загрузите и просмотрите необработанные данные.
Сначала мы загрузим данные, введя следующую команду:
sysuse nlsw88
Мы можем просмотреть необработанные данные, введя следующую команду:
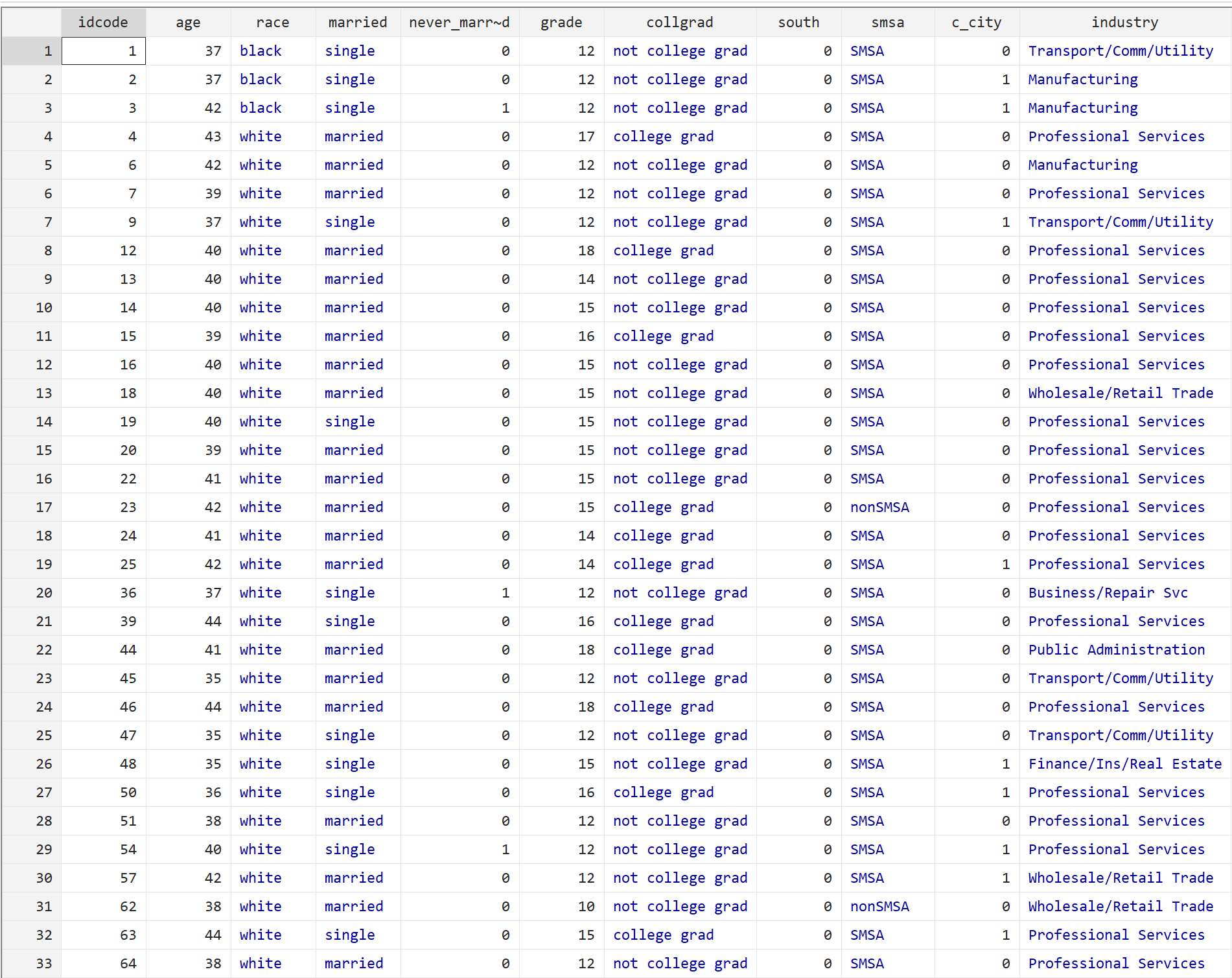
бр
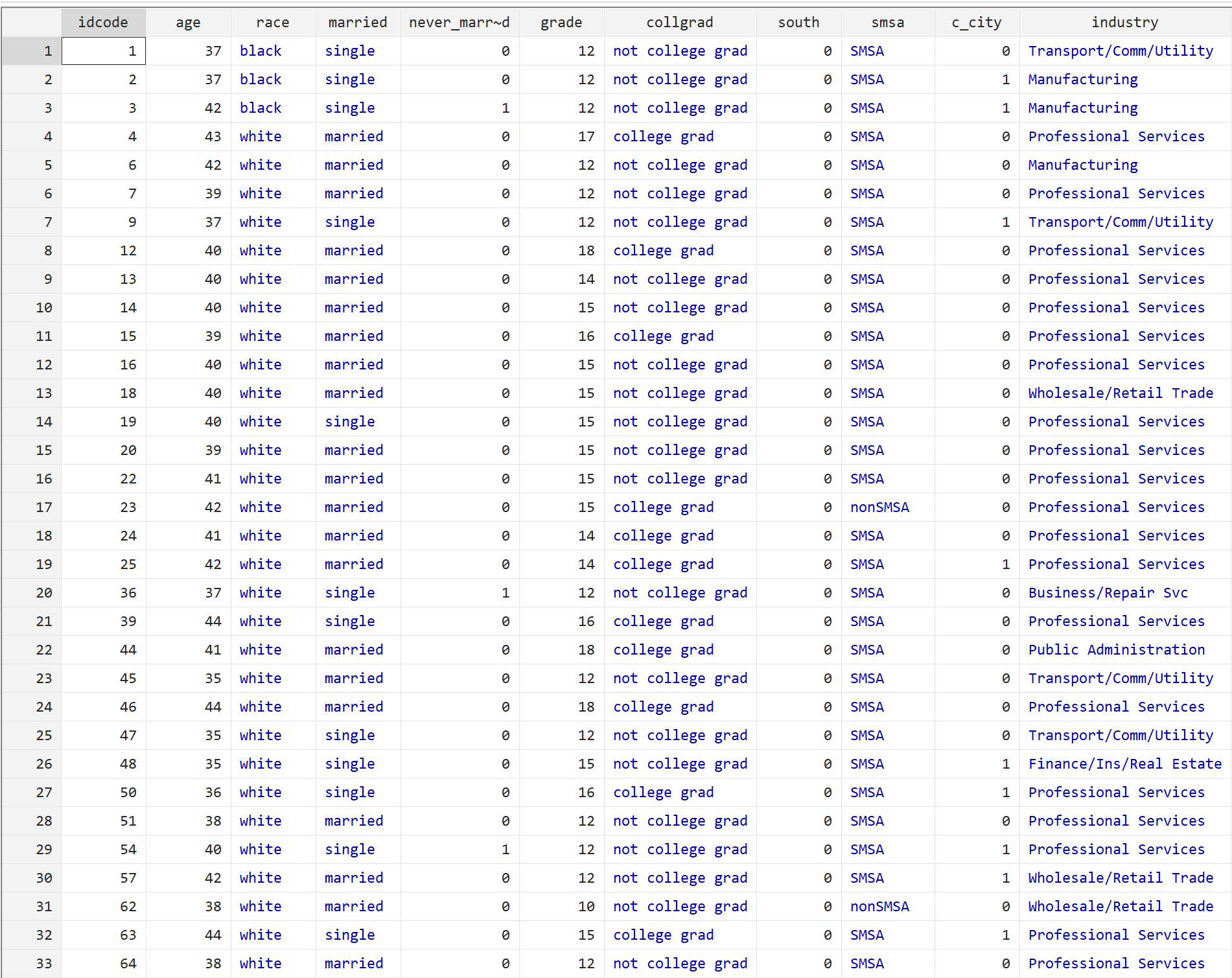
Каждая строка отображает информацию о человеке, включая его возраст, расу, семейное положение, уровень образования и множество других факторов.
Шаг 2: Загрузите пакет качества подгонки.
Чтобы выполнить тест на пригодность, нам нужно установить пакет csgof.Мы можем сделать это, введя следующую команду:
найти ксгоф
Появится новое окно. Нажмите на ссылку csgof с https://stats.idre.ucla.edu/stat/stata/ado/analysis .
Появится еще одно окно. Щелкните ссылку с надписью « Нажмите здесь, чтобы установить» .
Установка пакета займет всего несколько секунд.
Шаг 3: Проведите тест на пригодность.
После установки пакета мы можем выполнить тест на соответствие данным, чтобы определить, является ли истинное распределение расы следующим: 70% белых, 20% черных, 10% других.
Мы будем использовать следующий синтаксис для выполнения теста:
csgof variable_of_interest, experc (list_of_expected_percentages)
Вот точный синтаксис, который мы будем использовать в нашем случае:
csgof раса, опыт(70, 20, 10)

Вот как интерпретировать вывод:
Поле сводки: в этом поле показаны ожидаемый процент, ожидаемая частота и наблюдаемая частота для каждой гонки. Например:
- Ожидаемый процент белых людей составлял 70%. Это тот процент, который мы указали.
- Ожидаемая частота белых особей составила 1572,2. Это рассчитано с использованием того факта, что в наборе данных было 2246 человек, поэтому 70% этого числа составляет 1572,2.
- Наблюдаемая частота белых особей составила 1637 человек. Это фактическое количество белых людей в наборе данных.
Chisq(2): это статистика теста хи-квадрат для теста согласия. Получается 218,13.
p: это значение p, связанное со статистикой теста хи-квадрат. Получается 0. Поскольку это меньше 0,05, мы не можем отвергнуть нулевую гипотезу о том, что истинное расовое распределение составляет 70% белых, 20% черных, 10% других. У нас есть достаточно доказательств, чтобы заключить, что истинное распределение рас отличается от этого гипотетического распределения.