Фиктивная переменная — это тип переменной, которую мы создаем в регрессионном анализе, чтобы мы могли представить категориальную переменную как числовую переменную, которая принимает одно из двух значений: ноль или единицу.
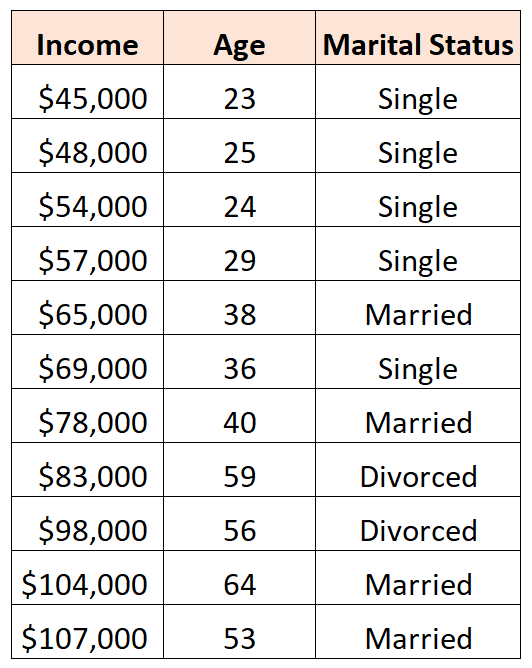
Например, предположим, что у нас есть следующий набор данных, и мы хотели бы использовать возраст и семейное положение для прогнозирования дохода :
Чтобы использовать семейное положение в качестве предиктора в регрессионной модели, мы должны преобразовать его в фиктивную переменную.
Поскольку в настоящее время это категориальная переменная, которая может принимать три разных значения («Холост», «Женат» или «Разведен»), нам нужно создать k -1 = 3-1 = 2 фиктивных переменных.
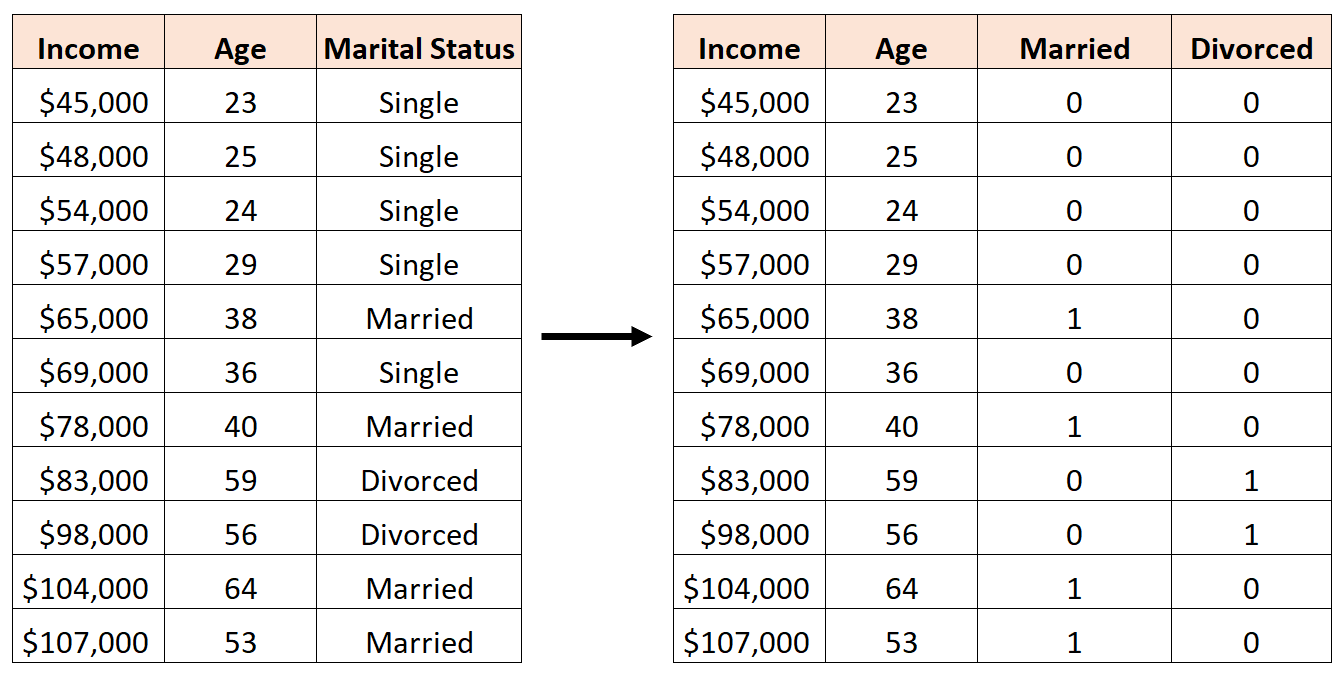
Чтобы создать эту фиктивную переменную, мы можем позволить «Single» быть нашим базовым значением, поскольку оно встречается чаще всего. Таким образом, вот как мы можем преобразовать семейное положение в фиктивные переменные:
В этом руководстве представлен пошаговый пример того, как создать фиктивные переменные для этого точного набора данных в R, а затем выполнить регрессионный анализ, используя эти фиктивные переменные в качестве предикторов.
Шаг 1: Создайте данные
Во-первых, давайте создадим набор данных в R:
#create data frame
df <- data.frame(income=c(45000, 48000, 54000, 57000, 65000, 69000,
78000, 83000, 98000, 104000, 107000),
age=c(23, 25, 24, 29, 38, 36, 40, 59, 56, 64, 53),
status=c('Single', 'Single', 'Single', 'Single',
'Married', 'Single', 'Married', 'Divorced',
'Divorced', 'Married', 'Married'))
#view data frame
df
income age status
1 45000 23 Single
2 48000 25 Single
3 54000 24 Single
4 57000 29 Single
5 65000 38 Married
6 69000 36 Single
7 78000 40 Married
8 83000 59 Divorced
9 98000 56 Divorced
10 104000 64 Married
11 107000 53 Married
Шаг 2: Создайте фиктивные переменные
Затем мы можем использовать функцию ifelse() в R для определения фиктивных переменных, а затем определить окончательный фрейм данных, который мы хотели бы использовать для построения регрессионной модели:
#create dummy variables
married <- ifelse(df$status == 'Married', 1, 0)
divorced <- ifelse(df$status == 'Divorced', 1, 0)
#create data frame to use for regression
df_reg <- data.frame(income = df$income,
age = df$age,
married = married,
divorced = divorced)
#view data frame
df_reg
income age married divorced
1 45000 23 0 0
2 48000 25 0 0
3 54000 24 0 0
4 57000 29 0 0
5 65000 38 1 0
6 69000 36 0 0
7 78000 40 1 0
8 83000 59 0 1
9 98000 56 0 1
10 104000 64 1 0
11 107000 53 1 0
Шаг 3: выполните линейную регрессию
Наконец, мы можем использовать функцию lm() для подбора модели множественной линейной регрессии:
#create regression model
model <- lm (income ~ age + married + divorced, data=df_reg)
#view regression model output
summary(model)
Call:
lm(formula = income ~ age + married + divorced, data = df_reg)
Residuals:
Min 1Q Median 3Q Max
-9707.5 -5033.8 45.3 3390.4 12245.4
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 14276.1 10411.5 1.371 0.21266
age 1471.7 354.4 4.152 0.00428 \*\*
married 2479.7 9431.3 0.263 0.80018
divorced -8397.4 12771.4 -0.658 0.53187
---
Signif. codes: 0 ‘\*\*\*’ 0.001 ‘\*\*’ 0.01 ‘\*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 8391 on 7 degrees of freedom
Multiple R-squared: 0.9008, Adjusted R-squared: 0.8584
F-statistic: 21.2 on 3 and 7 DF, p-value: 0.0006865
Подогнанная линия регрессии оказывается такой:
Доход = 14 276,1 + 1 471,7*(возраст) + 2 479,7*(замужем) – 8 397,4*(разведен)
Мы можем использовать это уравнение, чтобы найти предполагаемый доход для человека в зависимости от его возраста и семейного положения. Например, доход 35-летнего человека, состоящего в браке, оценивается в 68 264 доллара США :
Доход = 14 276,2 + 1 471,7 * (35) + 2 479,7 * (1) - 8 397,4 * (0) = 68 264 доллара США.
Вот как интерпретировать коэффициенты регрессии из таблицы:
- Пересечение: Пересечение представляет собой средний доход одного человека в возрасте 0 лет. Очевидно, что вам не может быть ноль лет, поэтому нет смысла интерпретировать перехват сам по себе в этой конкретной регрессионной модели.
- Возраст: каждый год увеличения возраста связан со средним увеличением дохода на 1471,70 доллара. Поскольку p-значение (0,004) меньше 0,05, возраст является статистически значимым предиктором дохода.
- Женат: Женатый человек в среднем зарабатывает на 2479,70 долларов больше, чем одинокий человек. Поскольку p-значение (0,800) не менее 0,05, эта разница не является статистически значимой.
- Разведен: разведенный человек в среднем зарабатывает на 8 397,40 долларов меньше, чем одинокий человек. Поскольку p-значение (0,532) не менее 0,05, эта разница не является статистически значимой.
Поскольку обе фиктивные переменные не были статистически значимыми, мы могли исключить из модели семейное положение в качестве предиктора, поскольку оно, по-видимому, не добавляет никакой прогностической ценности для дохода.