При использовании моделей классификации в машинном обучении мы часто используем две метрики для оценки качества модели: F1 Score и Accuracy .
Для обеих метрик чем выше значение, тем лучше модель способна классифицировать наблюдения по классам.
Однако каждый показатель рассчитывается с использованием другой формулы, и у каждого из них есть свои плюсы и минусы.
В следующем примере показано, как рассчитать каждую метрику на практике.
Пример: Расчет очков и точности F1
Предположим, мы используем модель логистической регрессии, чтобы предсказать, попадут ли в НБА 400 разных баскетболистов из колледжей.
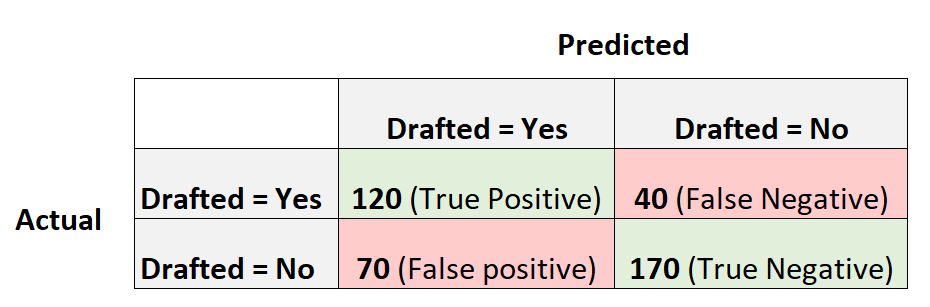
Следующая матрица путаницы суммирует прогнозы, сделанные моделью:
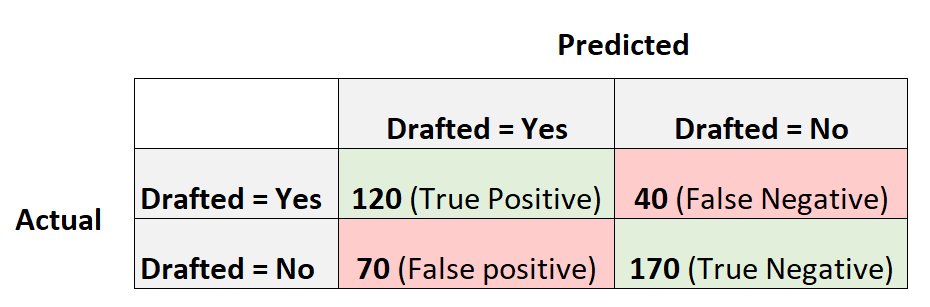
Вот как рассчитать различные показатели для матрицы путаницы:
Точность: исправление положительных прогнозов по отношению к общему количеству положительных прогнозов.
- Точность = истинный положительный результат / (истинный положительный результат + ложный положительный результат)
- Точность = 120 / (120 + 70)
- Точность = 0,63
Напомним: исправление положительных прогнозов по отношению к общему количеству фактических положительных результатов.
- Отзыв = истинно положительный / (истинно положительный + ложноотрицательный)
- Напомним = 120 / (120 + 40)
- Напомним = 0,75
Точность: процент всех правильно классифицированных наблюдений.
- Точность = (истинно положительный + истинно отрицательный) / (общий размер выборки)
- Точность = (120 + 170) / (400)
- Точность = 0,725
Оценка F1: Гармоническое среднее значение точности и отзыва
- Оценка F1 = 2 * (Точность * Отзыв) / (Точность + Отзыв)
- Оценка F1 = 2 * (0,63 * 0,75) / (0,63 + 0,75)
- Оценка F1 = 0,685
Когда использовать F1 Score против точности
Есть плюсы и минусы использования оценки и точности F1.
Точность :
Pro : Легко интерпретировать. Если мы говорим, что модель точна на 90%, мы знаем, что она правильно классифицировала 90% наблюдений.
Против : не учитывает, как распределяются данные. Например, предположим, что 90% всех игроков не попадают в НБА. Если у нас есть модель, которая просто предсказывает, что каждый игрок не будет выбран на драфте, модель будет правильно предсказывать результат для 90% игроков. Это значение кажется высоким, но на самом деле модель не может правильно предсказать любого игрока, который будет выбран на драфте.
Оценка Ф1 :
Pro : учитывает, как распределяются данные. Например, если данные сильно несбалансированы (например, 90% всех игроков не выбираются на драфт, а 10% выбираются), то оценка F1 обеспечит лучшую оценку эффективности модели.
Минусы : сложнее интерпретировать. Оценка F1 представляет собой сочетание точности и полноты модели, что затрудняет ее интерпретацию.
Как правило большого пальца:
Мы часто используем точность , когда классы сбалансированы и нет серьезных недостатков в прогнозировании ложноотрицательных результатов.
Мы часто используем показатель F1 , когда классы несбалансированы, и существует серьезный недостаток предсказания ложноотрицательных результатов.
Например, если мы используем модель логистической регрессии, чтобы предсказать, есть ли у кого-то рак, ложноотрицательные результаты — это действительно плохо (например, предсказание того, что у кого-то нет рака, когда он действительно есть), поэтому оценка F1 будет наказывать модели, которые имеют слишком много ложноотрицательных результатов. больше, чем точность.
Дополнительные ресурсы
Регрессия против классификации: в чем разница?
Введение в логистическую регрессию
Как выполнить логистическую регрессию в R
Как выполнить логистическую регрессию в Python