Когда мы хотим понять взаимосвязь между одной или несколькими переменными-предикторами и переменной непрерывного отклика, мы часто используем линейную регрессию .
Однако, когда переменная ответа является категориальной, мы можем вместо этого использовать логистическую регрессию .
Логистическая регрессия — это тип алгоритма классификации, потому что он пытается «классифицировать» наблюдения из набора данных по отдельным категориям.
Вот несколько примеров, когда мы можем использовать логистическую регрессию:
- Мы хотим использовать кредитный рейтинг и банковский баланс , чтобы предсказать, не выполнит ли данный клиент дефолт по кредиту. (Переменная ответа = «По умолчанию» или «Нет по умолчанию»)
- Мы хотим использовать среднее количество подборов за игру и среднее количество очков за игру , чтобы предсказать, будет ли данный баскетболист выбран в НБА (переменная ответа = «Выбран» или «Не выбран»).
- Мы хотим использовать квадратные метры и количество ванных комнат , чтобы предсказать, будет ли дом в определенном городе продаваться по цене 200 тысяч долларов или выше. (Переменная ответа = «Да» или «Нет»)
Обратите внимание, что переменная ответа в каждом из этих примеров может принимать только одно из двух значений. Сравните это с линейной регрессией, в которой переменная отклика принимает некоторое непрерывное значение.
Уравнение логистической регрессии
Логистическая регрессия использует метод, известный как оценка максимального правдоподобия (детали здесь не рассматриваются), чтобы найти уравнение следующего вида:
log[p(X) / (1-p(X))] = β 0 + β 1 X 1 + β 2 X 2 + … + β p X p
куда:
- X j : j -я предикторная переменная
- β j : Оценка коэффициента для j -й переменной-предиктора
Формула в правой части уравнения предсказывает логарифмические шансы переменной ответа, принимающей значение 1.
Таким образом, когда мы подбираем модель логистической регрессии, мы можем использовать следующее уравнение для расчета вероятности того, что данное наблюдение примет значение 1:
p(X) = e β 0 + β 1 X 1 + β 2 X 2 + … + β p X p / (1 + e β 0 + β 1 X 1 + β 2 X 2 + … + β p X p )
Затем мы используем некоторый порог вероятности, чтобы классифицировать наблюдение как 1 или 0.
Например, мы можем сказать, что наблюдения с вероятностью больше или равной 0,5 будут классифицироваться как «1», а все остальные наблюдения будут классифицироваться как «0».
Как интерпретировать вывод логистической регрессии
Предположим, мы используем модель логистической регрессии, чтобы предсказать, попадет ли конкретный баскетболист в НБА, основываясь на его среднем количестве подборов за игру и среднем количестве очков за игру.
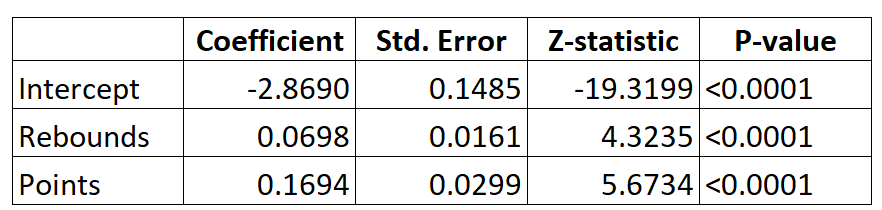
Вот результат для модели логистической регрессии:
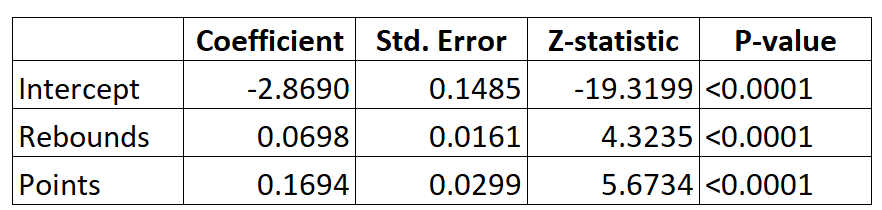
Используя коэффициенты, мы можем вычислить вероятность того, что любой данный игрок попадет в НБА, исходя из его среднего количества подборов и очков за игру, используя следующую формулу:
P (драфт) = e -2,8690 + 0,0698 * (реб) + 0,1694 * (балл) / (1 + e -2,8690 + 0,0698 * (реб) + 0,1694 * (балл) )
Например, предположим, что данный игрок набирает в среднем 8 подборов за игру и 15 очков за игру. Согласно модели, вероятность того, что этот игрок попадет в НБА, составляет 0,557 .
P (черновик) = e -2,8690 + 0,0698 * (8) + 0,1694 * (15) / (1 + e -2,8690 + 0,0698 * (8) + 0,1694 * (15) ) = 0,557
Поскольку эта вероятность больше 0,5, можно предположить, что этот игрок будет выбран на драфте.
Сравните это с игроком, который в среднем делает только 3 подбора и 7 очков за игру. Вероятность того, что этот игрок попадет в НБА, равна 0,186 .
P (черновик) = e -2,8690 + 0,0698 * (3) + 0,1694 * (7) / (1 + e -2,8690 + 0,0698 * (3) + 0,1694 * (7) ) = 0,186
Поскольку эта вероятность меньше 0,5, можно предположить, что этот игрок не будет выбран на драфте.
Предположения логистической регрессии
Логистическая регрессия использует следующие предположения:
1. Переменная ответа является двоичной. Предполагается, что переменная отклика может принимать только два возможных результата.
2. Наблюдения независимы. Предполагается, что наблюдения в наборе данных независимы друг от друга. То есть наблюдения не должны исходить из повторных измерений одного и того же человека или каким-либо образом быть связаны друг с другом.
3. Между переменными-предикторами нет сильной мультиколлинеарности.Предполагается, что ни одна из предикторных переменных не сильно коррелирует друг с другом.
4. Крайних выбросов нет. Предполагается, что в наборе данных нет экстремальных выбросов или влиятельных наблюдений.
5. Между предикторными переменными и логитом переменной отклика существует линейная зависимость.Это предположение можно проверить с помощью теста Бокса-Тидвелла.
6. Размер выборки достаточно велик. Как правило, у вас должно быть как минимум 10 случаев с наименее частым исходом для каждой независимой переменной. Например, если у вас есть 3 объясняющие переменные и ожидаемая вероятность наименее частого исхода равна 0,20, тогда размер выборки должен быть не менее (10*3)/0,20 = 150.
Ознакомьтесь с этим постом для подробного объяснения того, как проверить эти предположения.