Когда мы хотим понять взаимосвязь между одной переменной-предиктором и переменной-ответом, мы часто используем простую линейную регрессию .
Однако, если мы хотим понять взаимосвязь между несколькими переменными-предикторами и переменной ответа, мы можем вместо этого использовать множественную линейную регрессию .
Если у нас есть p переменных-предикторов, то модель множественной линейной регрессии принимает форму:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p X p + ε
куда:
- Y : переменная ответа
- X j : j -я предикторная переменная
- β j : среднее влияние на Y увеличения X j на одну единицу при неизменности всех остальных предикторов.
- ε : Член ошибки
Значения β 0 , β 1 , B 2 , … , β p выбираются методом наименьших квадратов , который минимизирует сумму квадратов невязок (RSS):
RSS = Σ(y i – ŷ i ) 2
куда:
- Σ : греческий символ, означающий сумму
- y i : Фактическое значение отклика для i -го наблюдения
- ŷ i : прогнозируемое значение отклика на основе модели множественной линейной регрессии.
Метод, используемый для нахождения этих оценок коэффициентов, основан на матричной алгебре, и мы не будем здесь подробно останавливаться на нем. К счастью, любой статистический софт может рассчитать эти коэффициенты за вас.
Как интерпретировать вывод множественной линейной регрессии
Предположим, мы подогнали модель множественной линейной регрессии, используя предикторные переменные: количество часов обучения и количество сданных подготовительных экзаменов, а также переменную ответа на экзамене .
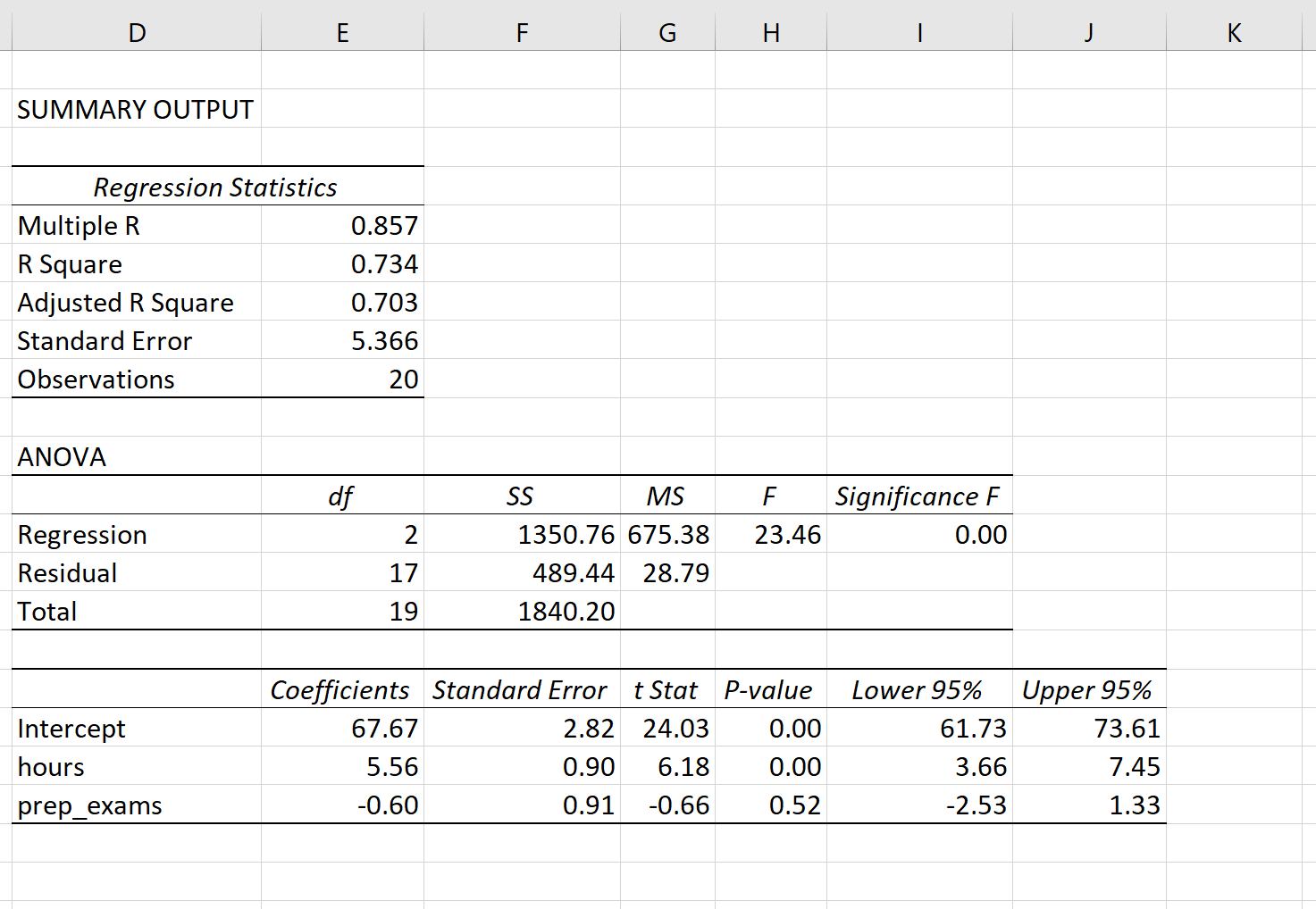
На следующем снимке экрана показано, как могут выглядеть выходные данные множественной линейной регрессии для этой модели:
Примечание. На приведенном ниже снимке экрана показаны выходные данные множественной линейной регрессии для Excel , но числа, показанные в выходных данных, являются типичными для выходных данных регрессии, которые вы увидите с помощью любого статистического программного обеспечения.
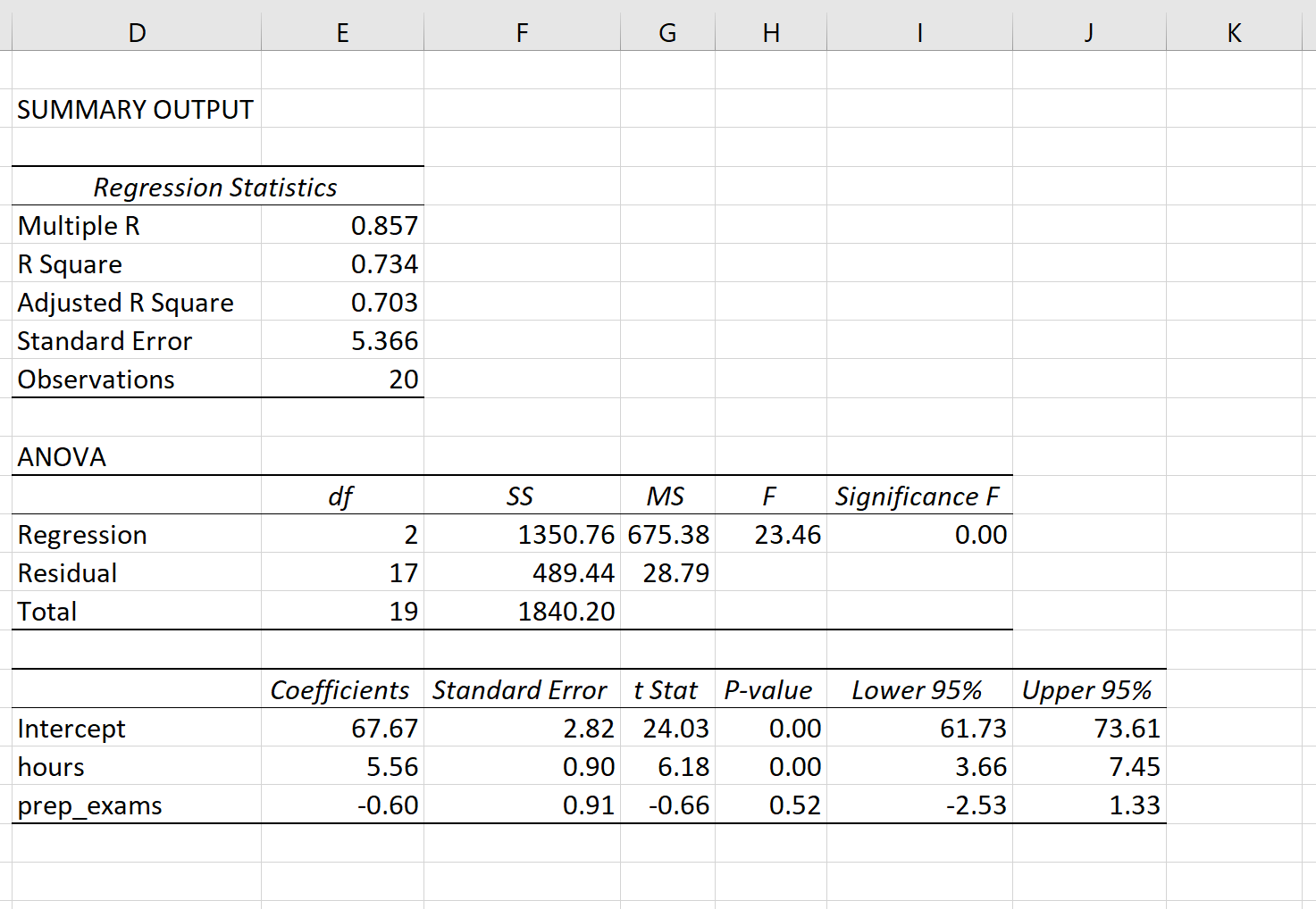
Из выходных данных модели коэффициенты позволяют нам сформировать предполагаемую модель множественной линейной регрессии:
Экзаменационный балл = 67,67 + 5,56*(часы) – 0,60*(подготовительные экзамены)
Способ интерпретации коэффициентов следующий:
- Каждое дополнительное увеличение количества часов обучения на одну единицу связано со средним увеличением экзаменационного балла на 5,56 балла, при условии, что подготовительные экзамены остаются постоянными.
- Каждое дополнительное увеличение количества сданных подготовительных экзаменов на одну единицу связано со средним снижением экзаменационного балла на 0,60 балла при условии, что количество учебных часов остается постоянным.
Мы также можем использовать эту модель, чтобы найти ожидаемый результат экзамена, который студент получит на основе общего количества часов обучения и сданных подготовительных экзаменов. Например, студент, который занимается 4 часа и сдает 1 подготовительный экзамен, должен получить на экзамене 89,31 балла:
Экзаменационный балл = 67,67 + 5,56*(4) -0,60*(1) = 89,31
Вот как интерпретировать остальную часть вывода модели:
- R-квадрат: известен как коэффициент детерминации. Это доля дисперсии переменной отклика, которая может быть объяснена объясняющими переменными. В этом примере 73,4% вариаций в экзаменационных баллах можно объяснить количеством часов обучения и количеством сданных подготовительных экзаменов.
- Стандартная ошибка: это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 5,366 единицы.
- F: это общая статистика F для регрессионной модели, рассчитанная как MS регрессии / остаточная MS.
- Значимость F: это значение p, связанное с общей статистикой F. Он говорит нам, является ли регрессионная модель в целом статистически значимой. Другими словами, он говорит нам, имеют ли объединенные две объясняющие переменные статистически значимую связь с переменной отклика. В этом случае p-значение меньше 0,05, что указывает на то, что объясняющие переменные количество часов обучения и количество сданных подготовительных экзаменов в совокупности имеют статистически значимую связь с экзаменационным баллом.
- Коэффициент P-значения. Отдельные p-значения говорят нам, является ли каждая независимая переменная статистически значимой. Мы можем видеть, что изученные часы статистически значимы (p = 0,00), в то время как пройденные подготовительные экзамены (p = 0,52) не являются статистически значимыми при α = 0,05. Поскольку сданные подготовительные экзамены не являются статистически значимыми, мы можем принять решение удалить их из модели.
Как оценить соответствие модели множественной линейной регрессии
Есть два числа, которые обычно используются для оценки того, насколько хорошо модель множественной линейной регрессии «соответствует» набору данных:
1. R-квадрат: это доля дисперсии переменной отклика , которая может быть объяснена переменными-предикторами.
Значение для R-квадрата может варьироваться от 0 до 1. Значение 0 указывает, что переменная отклика вообще не может быть объяснена предикторной переменной. Значение 1 указывает, что переменная отклика может быть полностью объяснена без ошибок с помощью переменной-предиктора.
Чем выше R-квадрат модели, тем лучше модель может соответствовать данным.
2. Стандартная ошибка: это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. Чем меньше стандартная ошибка, тем лучше модель соответствует данным.
Если мы заинтересованы в прогнозировании с использованием модели регрессии, стандартная ошибка регрессии может быть более полезной метрикой, чем R-квадрат, потому что она дает нам представление о том, насколько точными будут наши прогнозы в единицах измерения.
Для полного объяснения плюсов и минусов использования R-квадрата и стандартной ошибки для оценки соответствия модели ознакомьтесь со следующими статьями:
Предположения множественной линейной регрессии
Существует четыре ключевых предположения, которые множественная линейная регрессия делает в отношении данных:
1. Линейная зависимость. Существует линейная зависимость между независимой переменной x и зависимой переменной y.
2. Независимость: Остатки независимы. В частности, нет корреляции между последовательными остатками в данных временных рядов.
3. Гомоскедастичность: остатки имеют постоянную дисперсию на каждом уровне x.
4. Нормальность: остатки модели нормально распределены.
Для полного объяснения того, как проверить эти предположения, ознакомьтесь с этой статьей .
Множественная линейная регрессия с использованием программного обеспечения
В следующих руководствах представлены пошаговые примеры выполнения множественной линейной регрессии с использованием различных статистических программ:
Как выполнить множественную линейную регрессию в R
Как выполнить множественную линейную регрессию в Python
Как выполнить множественную линейную регрессию в Excel
Как выполнить множественную линейную регрессию в SPSS
Как выполнить множественную линейную регрессию в Stata
Как выполнить линейную регрессию в Google Sheets