Линейная регрессия — это полезный статистический метод, который мы можем использовать для понимания взаимосвязи между двумя переменными, x и y. Однако, прежде чем мы проведем линейную регрессию, мы должны сначала убедиться, что выполняются четыре предположения:
1. Линейная зависимость. Существует линейная зависимость между независимой переменной x и зависимой переменной y.
2. Независимость: Остатки независимы. В частности, нет корреляции между последовательными остатками в данных временных рядов.
3. Гомоскедастичность: остатки имеют постоянную дисперсию на каждом уровне x.
4. Нормальность: остатки модели нормально распределены.
Если одно или несколько из этих предположений нарушаются, то результаты нашей линейной регрессии могут быть ненадежными или даже вводящими в заблуждение.
В этом посте мы даем объяснение для каждого предположения, как определить, выполняется ли предположение, и что делать, если предположение нарушается.
Допущение 1: линейная зависимость
Объяснение
Первое предположение линейной регрессии состоит в том, что существует линейная связь между независимой переменной x и независимой переменной y.
Как определить, выполняется ли это предположение
Самый простой способ определить, выполняется ли это предположение, — построить график разброса значений x и y. Это позволяет визуально увидеть, существует ли линейная зависимость между двумя переменными. Если кажется, что точки на графике могут располагаться вдоль прямой линии, то между двумя переменными существует некоторая линейная связь, и это предположение выполняется.
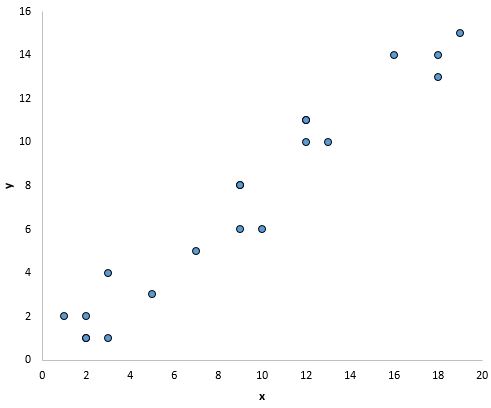
Например, точки на графике ниже выглядят так, как будто они лежат примерно на прямой линии, что указывает на линейную зависимость между x и y:
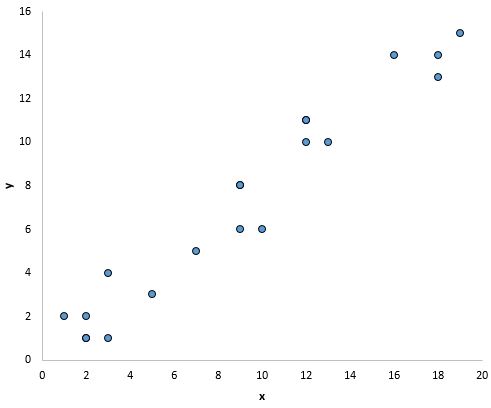
Однако на графике ниже не наблюдается линейной зависимости между x и y:
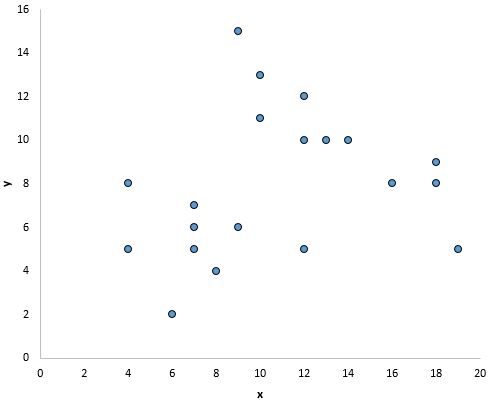
И на этом графике существует четкая связь между x и y, но не линейная зависимость :
Что делать, если это предположение нарушается
Если вы создадите точечную диаграмму значений x и y и увидите, что между двумя переменными нет линейной зависимости, у вас есть пара вариантов:
1. Примените нелинейное преобразование к независимой и/или зависимой переменной. Общие примеры включают логарифм, квадратный корень или обратную величину независимой и/или зависимой переменной.
2. Добавьте в модель еще одну независимую переменную. Например, если график зависимости x от y имеет параболическую форму, может иметь смысл добавить в модель X 2 в качестве дополнительной независимой переменной.
Предположение 2: Независимость
Объяснение
Следующее предположение линейной регрессии состоит в том, что остатки независимы. Это в основном актуально при работе с данными временных рядов. В идеале мы не хотим, чтобы между последовательными остатками была закономерность. Например, остатки не должны постоянно увеличиваться с течением времени.
Как определить, выполняется ли это предположение
Самый простой способ проверить, выполняется ли это предположение, — посмотреть на график остаточных временных рядов, который представляет собой график зависимости остатков от времени. В идеале, большая часть остаточных автокорреляций должна находиться в пределах 95% доверительных интервалов около нуля, которые расположены примерно на +/- 2 от квадратного корня из n , где n — размер выборки. Вы также можете формально проверить, выполняется ли это предположение, используя тест Дарбина-Ватсона .
Что делать, если это предположение нарушается
В зависимости от характера нарушения этого предположения у вас есть несколько вариантов:
- Для положительной последовательной корреляции рассмотрите возможность добавления в модель лагов зависимой и/или независимой переменной.
- Для отрицательной последовательной корреляции убедитесь, что ни одна из ваших переменных не является сверхдифференциальной .
- Для сезонной корреляции рассмотрите возможность добавления в модель сезонных фиктивных переменных.
Допущение 3: гомоскедастичность
Объяснение
Следующее предположение линейной регрессии состоит в том, что остатки имеют постоянную дисперсию на каждом уровне x. Это известно как гомоскедастичность.Когда это не так, говорят, что остатки страдают от гетероскедастичности .
Когда в регрессионном анализе присутствует гетероскедастичность, его результатам становится трудно доверять. В частности, гетероскедастичность увеличивает дисперсию оценок коэффициента регрессии, но регрессионная модель этого не учитывает. Это повышает вероятность того, что регрессионная модель объявит термин в модели статистически значимым, хотя на самом деле это не так.
Как определить, выполняется ли это предположение
Самый простой способ обнаружить гетероскедастичность — создать график зависимости подходящего значения от остатка .
После того, как вы подгоните линию регрессии к набору данных, вы можете создать диаграмму рассеяния, которая показывает подобранные значения модели в сравнении с остатками этих подобранных значений. На приведенной ниже диаграмме рассеяния показано типичное подобранное значение по сравнению с остаточным графиком , на котором присутствует гетероскедастичность.

Обратите внимание, как остатки становятся намного более разбросанными по мере того, как подобранные значения становятся больше. Эта форма «конуса» — классический признак гетероскедастичности:

Что делать, если это предположение нарушается
Существует три распространенных способа исправить гетероскедастичность:
1. Преобразуйте зависимую переменную. Одним из распространенных преобразований является просто получение журнала зависимой переменной. Например, если мы используем численность населения (независимая переменная) для прогнозирования количества цветочных магазинов в городе (зависимая переменная), вместо этого мы можем попытаться использовать численность населения для прогнозирования логарифма количества цветочных магазинов в городе. Использование журнала зависимой переменной, а не исходной зависимой переменной, часто приводит к исчезновению гетероскедастичности.
2. Переопределите зависимую переменную. Одним из распространенных способов переопределения зависимой переменной является использование скорости , а не необработанного значения. Например, вместо использования численности населения для прогнозирования количества цветочных магазинов в городе мы можем вместо этого использовать численность населения для прогнозирования количества цветочных магазинов на душу населения. В большинстве случаев это снижает изменчивость, которая естественным образом возникает среди больших групп населения, поскольку мы измеряем количество цветочных магазинов на человека, а не простое количество цветочных магазинов.
3. Используйте взвешенную регрессию. Другой способ исправить гетероскедастичность — использовать взвешенную регрессию. Этот тип регрессии присваивает вес каждой точке данных на основе дисперсии ее подобранного значения. По сути, это дает небольшие веса точкам данных с более высокой дисперсией, что уменьшает их квадраты невязок. Когда используются правильные веса, это может устранить проблему гетероскедастичности.
Допущение 4: нормальность
Объяснение
Следующее предположение линейной регрессии состоит в том, что остатки нормально распределены.
Как определить, выполняется ли это предположение
Есть два распространенных способа проверить, выполняется ли это предположение:
1. Проверьте предположение визуально, используя графики QQ .
График QQ, сокращение от графика квантилей-квантилей, представляет собой тип графика, который мы можем использовать, чтобы определить, следуют ли остатки модели нормальному распределению. Если точки на графике примерно образуют прямую диагональную линию, то предположение о нормальности выполнено.
На следующем графике QQ показан пример остатков, которые примерно соответствуют нормальному распределению:

Однако на приведенном ниже графике QQ показан пример, когда остатки явно отклоняются от прямой диагональной линии, что указывает на то, что они не следуют нормальному распределению:

2. Вы также можете проверить предположение о нормальности, используя формальные статистические тесты, такие как Шапиро-Уилк, Колмогоров-Смиронов, Жарк-Барре или Д'Агостино-Пирсон. Однако имейте в виду, что эти тесты чувствительны к большим размерам выборки, то есть они часто заключают, что остатки не являются нормальными, когда размер вашей выборки велик. Вот почему часто бывает проще просто использовать графические методы, такие как график QQ, чтобы проверить это предположение.
Что делать, если это предположение нарушается
Если предположение о нормальности нарушается, у вас есть несколько вариантов:
- Во-первых, убедитесь, что любые выбросы не оказывают сильного влияния на распределение. Если присутствуют выбросы, убедитесь, что они являются реальными значениями и не являются ошибками ввода данных.
- Далее можно применить нелинейное преобразование к независимой и/или зависимой переменной. Общие примеры включают логарифм, квадратный корень или обратную величину независимой и/или зависимой переменной.
Дальнейшее чтение:
Введение в простую линейную регрессию
Понимание гетероскедастичности в регрессионном анализе
Как создать и интерпретировать график QQ в R