Остаточная стандартная ошибка используется для измерения того, насколько хорошо модель регрессии соответствует набору данных.
Проще говоря, он измеряет стандартное отклонение остатков в регрессионной модели.
Он рассчитывается как:
Остаточная стандартная ошибка = √ Σ(y – ŷ) 2 /df
куда:
- y: наблюдаемое значение
- ŷ: Прогнозируемое значение
- df: Степени свободы, рассчитанные как общее количество наблюдений – общее количество параметров модели.
Чем меньше остаточная стандартная ошибка, тем лучше регрессионная модель соответствует набору данных. И наоборот, чем выше остаточная стандартная ошибка, тем хуже регрессионная модель соответствует набору данных.
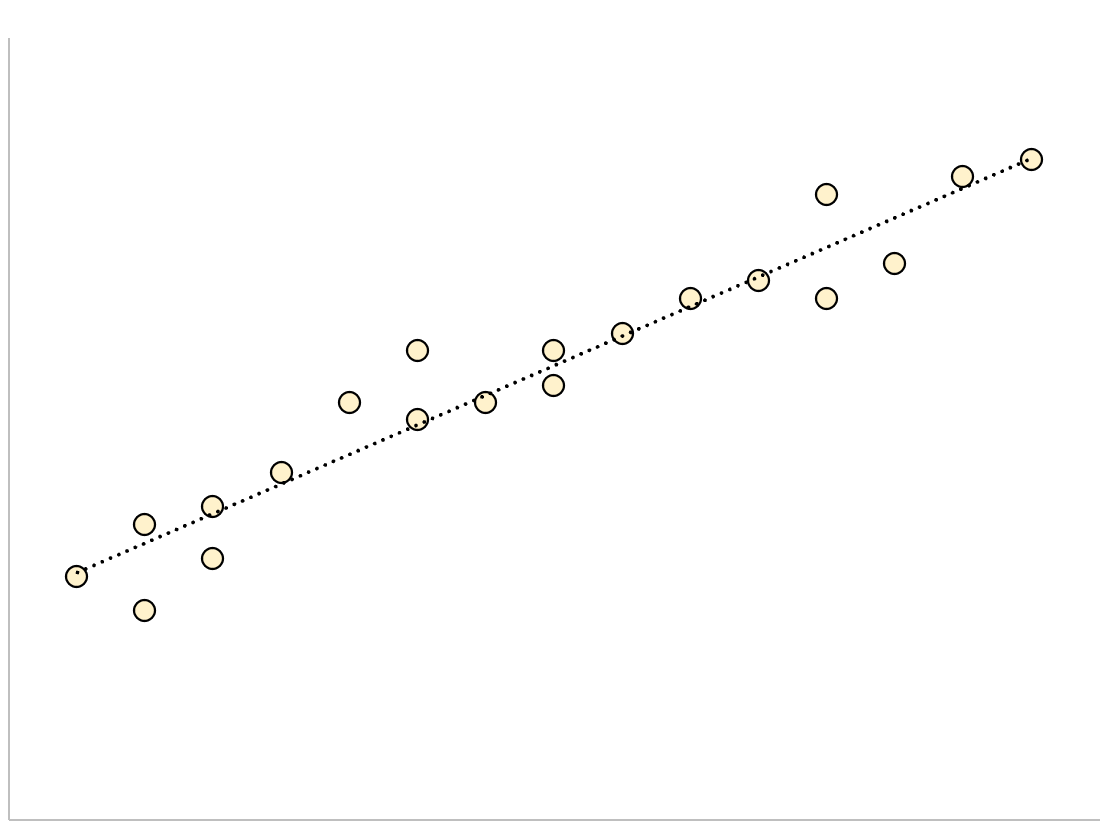
Модель регрессии с небольшой остаточной стандартной ошибкой будет иметь точки данных, которые плотно упакованы вокруг подобранной линии регрессии:
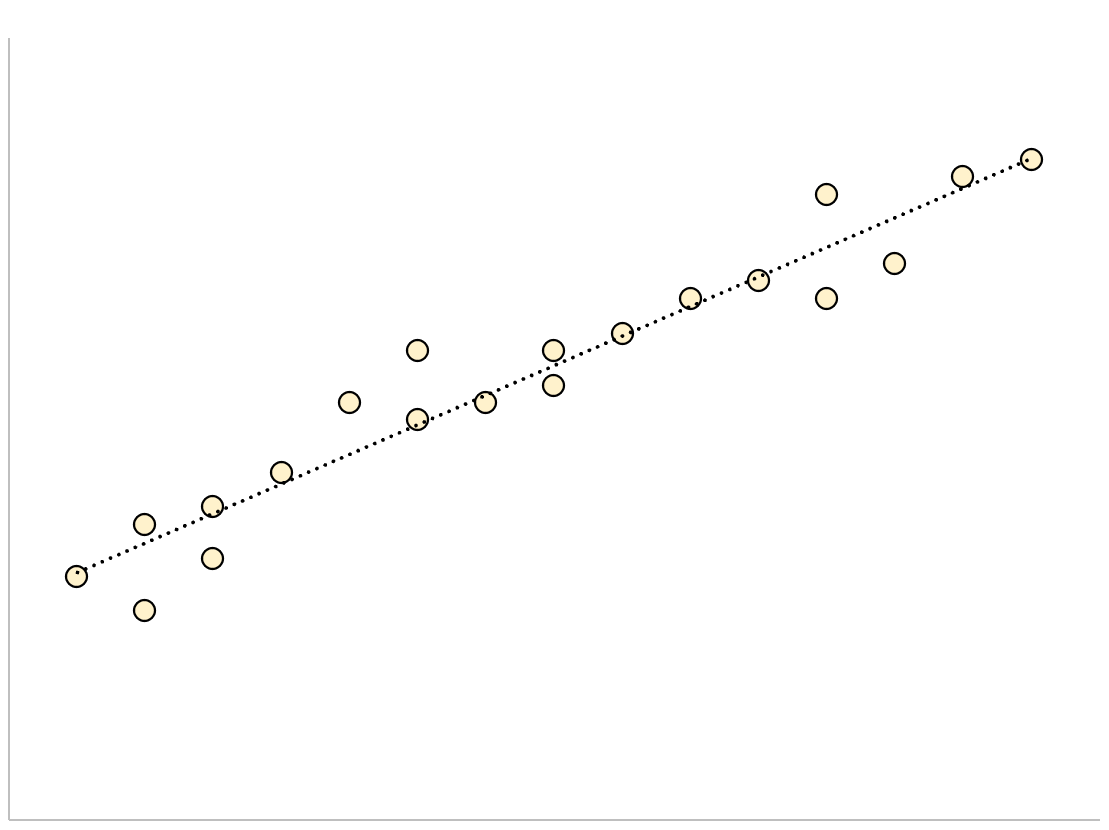
Остатки этой модели (разница между наблюдаемыми значениями и прогнозируемыми значениями) будут малы, что означает, что остаточная стандартная ошибка также будет небольшой.
И наоборот, регрессионная модель с большой остаточной стандартной ошибкой будет иметь точки данных, которые более свободно разбросаны по подобранной линии регрессии:
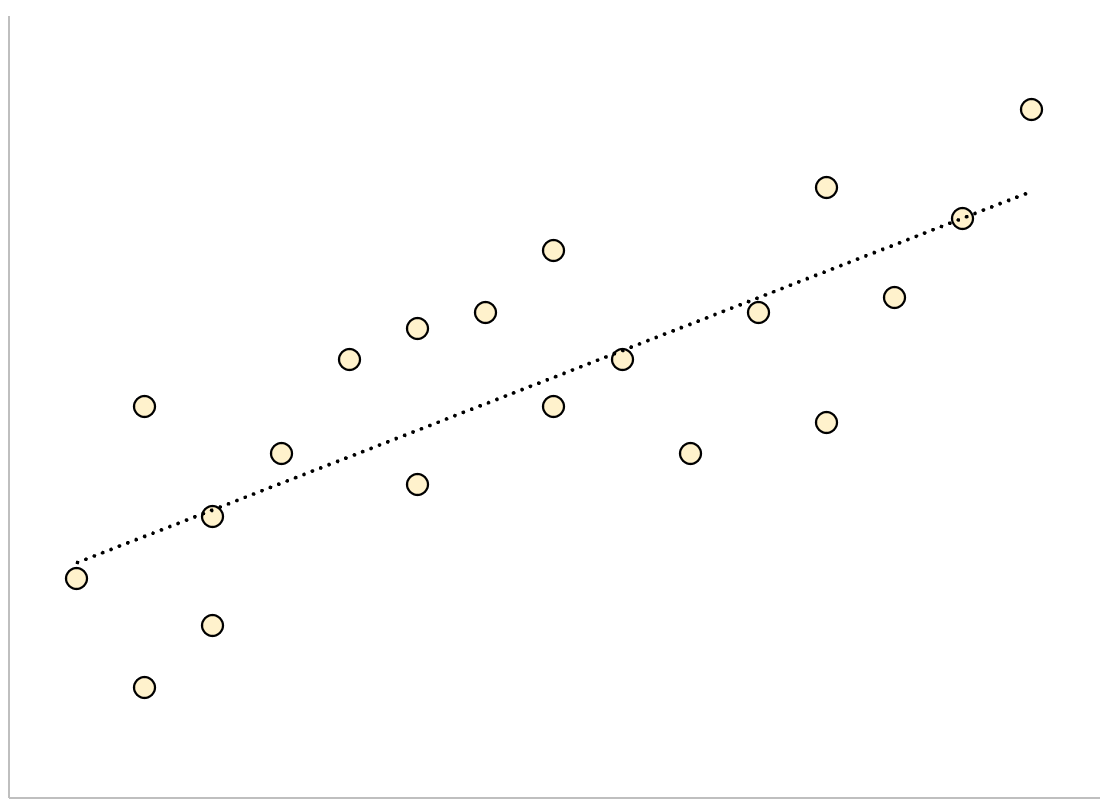
Остатки этой модели будут больше, что означает, что стандартная ошибка невязки также будет больше.
В следующем примере показано, как рассчитать и интерпретировать остаточную стандартную ошибку регрессионной модели в R.
Пример: интерпретация остаточной стандартной ошибки
Предположим, мы хотели бы подогнать следующую модель множественной линейной регрессии:
миль на галлон = β 0 + β 1 (смещение) + β 2 (лошадиные силы)
Эта модель использует переменные-предикторы «объем двигателя» и «лошадиная сила» для прогнозирования количества миль на галлон, которое получает данный автомобиль.
В следующем коде показано, как подогнать эту модель регрессии в R:
#load built-in *mtcars* dataset
data(mtcars)
#fit regression model
model <- lm(mpg~disp+hp, data=mtcars)
#view model summary
summary(model)
Call:
lm(formula = mpg ~ disp + hp, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-4.7945 -2.3036 -0.8246 1.8582 6.9363
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 30.735904 1.331566 23.083 < 2e-16 \*\*\*
disp -0.030346 0.007405 -4.098 0.000306 \*\*\*
hp -0.024840 0.013385 -1.856 0.073679.
---
Signif. codes: 0 '\*\*\*' 0.001 '\*\*' 0.01 '\*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.127 on 29 degrees of freedom
Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309
F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
В нижней части вывода мы видим, что остаточная стандартная ошибка этой модели составляет 3,127 .
Это говорит нам о том, что регрессионная модель предсказывает расход автомобилей на галлон со средней ошибкой около 3,127.
Использование остаточной стандартной ошибки для сравнения моделей
Остаточная стандартная ошибка особенно полезна для сравнения соответствия различных моделей регрессии.
Например, предположим, что мы подогнали две разные регрессионные модели для прогнозирования расхода автомобилей на галлон. Остаточная стандартная ошибка каждой модели выглядит следующим образом:
- Остаточная стандартная ошибка модели 1: 3,127
- Остаточная стандартная ошибка модели 2: 5,657
Поскольку модель 1 имеет меньшую остаточную стандартную ошибку, она лучше соответствует данным, чем модель 2. Таким образом, мы предпочли бы использовать модель 1 для прогнозирования расхода автомобилей на галлон, потому что прогнозы, которые она делает, ближе к наблюдаемым значениям расхода автомобилей на галлон.
Дополнительные ресурсы
Как выполнить простую линейную регрессию в R
Как выполнить множественную линейную регрессию в R
Как создать остаточный график в R