Логарифмическое значение правдоподобия регрессионной модели — это способ измерить степень соответствия модели. Чем выше значение логарифмической вероятности, тем лучше модель соответствует набору данных.
Значение логарифмического правдоподобия для данной модели может варьироваться от отрицательной бесконечности до положительной бесконечности. Фактическое значение логарифмического правдоподобия для данной модели в большинстве случаев не имеет смысла, но оно полезно для сравнения двух или более моделей .
На практике мы часто подгоняем несколько моделей регрессии к набору данных и выбираем модель с самым высоким значением логарифмического правдоподобия как модель, которая лучше всего соответствует данным.
В следующем примере показано, как на практике интерпретировать значения логарифмического правдоподобия для различных моделей регрессии.
Пример: интерпретация значений логарифмического правдоподобия
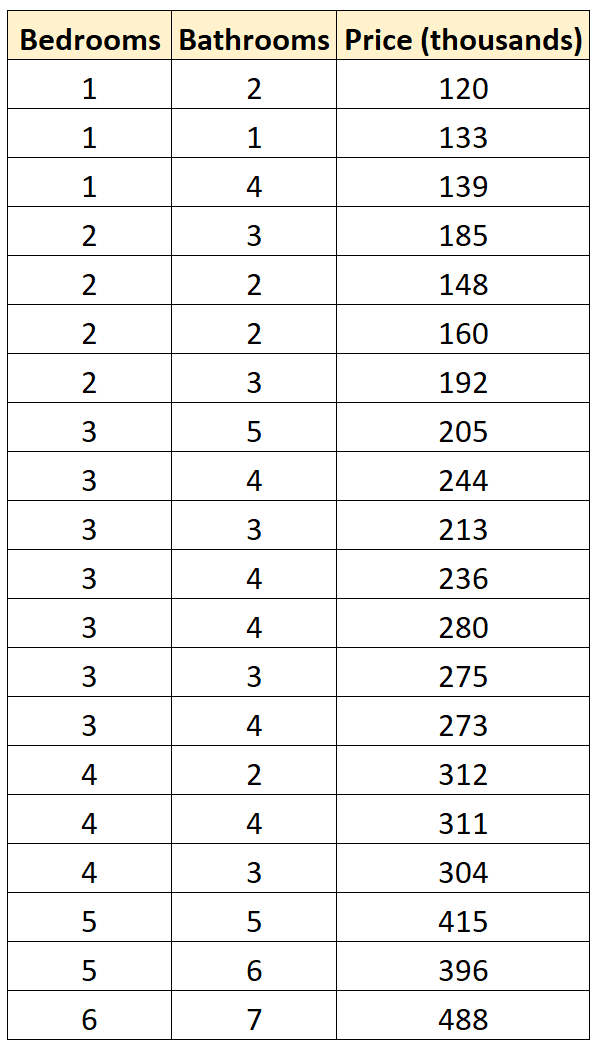
Предположим, у нас есть следующий набор данных, который показывает количество спален, количество ванных комнат и цену продажи 20 разных домов в определенном районе:

Предположим, мы хотим сопоставить следующие две регрессионные модели и определить, какая из них лучше соответствует данным:
Модель 1 : Цена = β 0 + β 1 (количество спален)
Модель 2 : Цена = β 0 + β 1 (количество ванных комнат)
В следующем коде показано, как подобрать каждую модель регрессии и вычислить значение логарифмического правдоподобия каждой модели в R:
#define data
df <- data.frame(beds=c(1, 1, 1, 2, 2, 2, 2, 3, 3, 3,
3, 3, 3, 3, 4, 4, 4, 5, 5, 6),
baths=c(2, 1, 4, 3, 2, 2, 3, 5, 4, 3,
4, 4, 3, 4, 2, 4, 3, 5, 6, 7),
price=c(120, 133, 139, 185, 148, 160, 192, 205, 244, 213,
236, 280, 275, 273, 312, 311, 304, 415, 396, 488))
#fit models
model1 <- lm(price~beds, data=df)
model2 <- lm(price~baths, data=df)
#calculate log-likelihood value of each model
logLik(model1)
'log Lik.' -91.04219 (df=3)
logLik(model2)
'log Lik.' -111.7511 (df=3)
Первая модель имеет более высокое значение логарифмического правдоподобия ( -91,04 ), чем вторая модель ( -111,75 ), что означает, что первая модель лучше подходит для данных.
Предостережения относительно использования значений логарифмического правдоподобия
При вычислении значений логарифмического правдоподобия важно отметить, что добавление в модель дополнительных переменных-предикторов почти всегда увеличивает значение логарифмического правдоподобия, даже если дополнительные переменные-предикторы не являются статистически значимыми.
Это означает, что вы должны сравнивать значения логарифмического правдоподобия между двумя регрессионными моделями только в том случае, если каждая модель имеет одинаковое количество переменных-предикторов.
Чтобы сравнить модели с разным количеством переменных-предикторов, вы можете выполнить тест отношения правдоподобия, чтобы сравнить качество соответствия двух вложенных регрессионных моделей.
Дополнительные ресурсы
Как использовать функцию lm() для подбора линейных моделей в R
Как выполнить тест отношения правдоподобия в R