Набор данных радужной оболочки — это встроенный в R набор данных, который содержит измерения 4 различных атрибутов (в сантиметрах) для 50 цветов 3 разных видов.
В этом руководстве объясняется, как исследовать и обобщать набор данных в R на примере набора данных радужной оболочки глаза.
Связанный: Полное руководство по набору данных mtcars в R
Загрузите набор данных Iris
Поскольку набор данных iris является встроенным набором данных в R, мы можем загрузить его с помощью следующей команды:
data(iris)
Мы можем взглянуть на первые шесть строк набора данных, используя функцию head() :
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Суммируйте набор данных Iris
Мы можем использовать функцию summary() , чтобы быстро суммировать каждую переменную в наборе данных:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median :5.800 Median :3.000 Median :4.350 Median :1.300
Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
Max.:7.900 Max.:4.400 Max.:6.900 Max.:2.500
Species
setosa :50
versicolor:50
virginica :50
Для каждой из числовых переменных мы можем увидеть следующую информацию:
- Мин : минимальное значение.
- 1st Qu : значение первого квартиля (25-й процентиль).
- Медиана : среднее значение.
- Среднее : среднее значение.
- 3- й Qu : значение третьего квартиля (75-й процентиль).
- Макс : максимальное значение.
Для единственной категориальной переменной в наборе данных (виды) мы видим подсчет частоты каждого значения:
- setosa : этот вид встречается 50 раз.
- versicolor : этот вид встречается 50 раз.
- virginica : этот вид встречается 50 раз.
Мы можем использовать функцию dim() для получения размеров набора данных с точки зрения количества строк и количества столбцов:
#display rows and columns
dim(iris)
[1] 150 5
Мы видим, что набор данных имеет 150 строк и 5 столбцов.
Мы также можем использовать функцию names() для отображения имен столбцов фрейма данных:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Визуализируйте набор данных Iris
Мы также можем создать несколько графиков для визуализации значений в наборе данных.
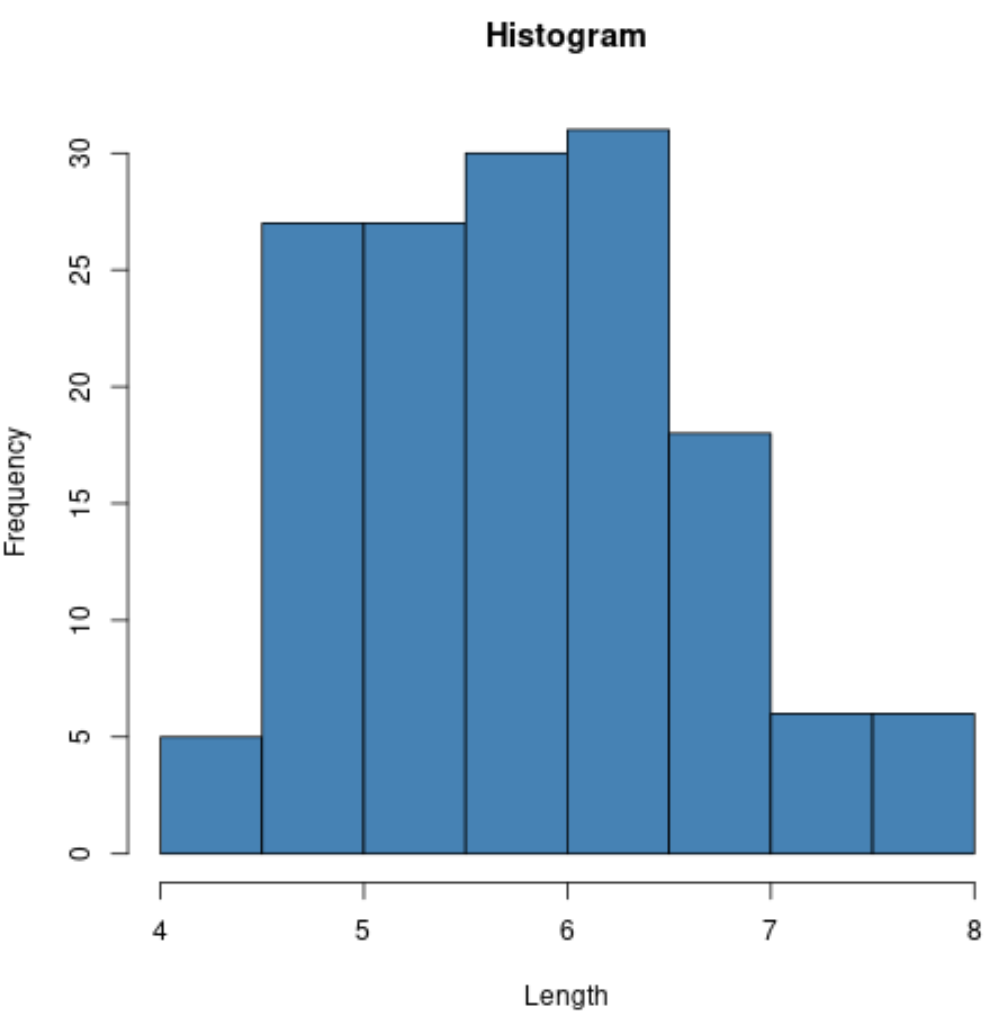
Например, мы можем использовать функцию hist() для создания гистограммы значений определенной переменной:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col='steelblue',
main='Histogram',
xlab='Length',
ylab='Frequency')

Мы также можем использовать функцию plot() для создания диаграммы рассеяния любой попарной комбинации переменных:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col='steelblue',
main='Scatterplot',
xlab='Sepal Width',
ylab='Sepal Length',
pch= 19 )

Мы также можем использовать функцию boxplot() для создания диаграммы по группам:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main='Sepal Length by Species',
xlab='Species',
ylab='Sepal Length',
col='steelblue',
border='black')

По оси X отображаются три вида, а по оси Y — распределение значений длины чашелистиков для каждого вида.
Этот тип графика позволяет нам быстро увидеть, что длина чашелистиков имеет тенденцию быть наибольшей у видов virginica и наименьшей у видов setosa.
Дополнительные ресурсы
В следующих руководствах объясняется, как суммировать наборы данных в R:
Самый простой способ создания сводных таблиц в R
Как рассчитать сводку из пяти чисел в R