Многие статистические тесты предполагают , что наборы данных обычно распределяются.
Есть четыре распространенных способа проверить это предположение в Python:
1. (Визуальный метод) Создайте гистограмму.
- Если гистограмма имеет форму колокола, то считается, что данные распределены нормально.
2. (Визуальный метод) Создайте график QQ.
- Если точки на графике примерно совпадают с прямой диагональной линией, предполагается, что данные распределены нормально.
3. (Формальный статистический тест) Выполните тест Шапиро-Уилка.
- Если p-значение теста больше, чем α = 0,05, то предполагается, что данные распределены нормально.
4. (Формальный статистический тест) Выполните тест Колмогорова-Смирнова.
- Если p-значение теста больше, чем α = 0,05, то предполагается, что данные распределены нормально.
В следующих примерах показано, как использовать каждый из этих методов на практике.
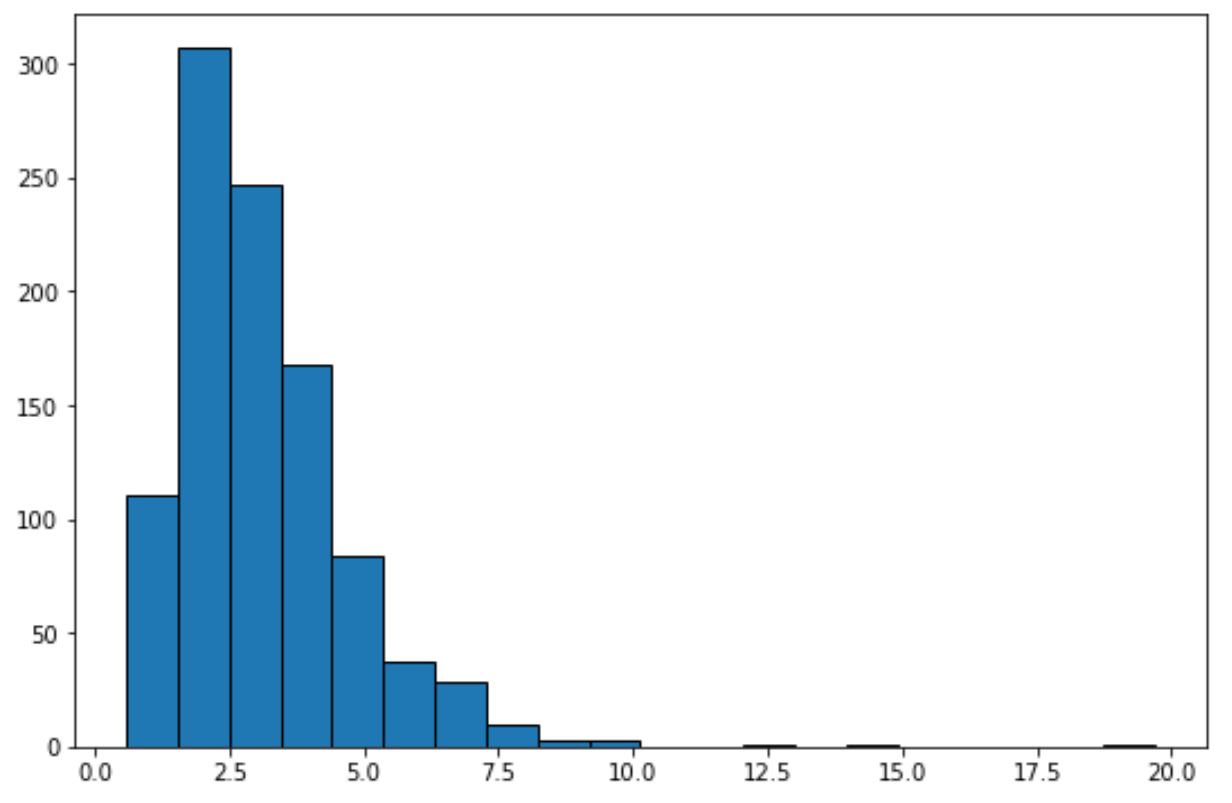
Способ 1: создание гистограммы
В следующем коде показано, как создать гистограмму для набора данных с логарифмически-нормальным распределением :
import math
import numpy as np
from scipy. stats import lognorm
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale=math. exp (1), size=1000)
#create histogram to visualize values in dataset
plt.hist (lognorm_dataset, edgecolor='black', bins=20)

Просто взглянув на эту гистограмму, мы можем сказать, что набор данных не имеет «колокольчатой формы» и не имеет нормального распределения.
Способ 2: создать график QQ
В следующем коде показано, как создать график QQ для набора данных, который соответствует логарифмически нормальному распределению:
import math
import numpy as np
from scipy. stats import lognorm
import statsmodels.api as sm
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale=math. exp (1), size=1000)
#create Q-Q plot with 45-degree line added to plot
fig = sm. qqplot (lognorm_dataset, line='45')
plt.show()

Если точки на графике ложатся примерно на прямую диагональную линию, мы обычно предполагаем, что набор данных имеет нормальное распределение.
Однако точки на этом графике явно не попадают на красную линию, поэтому мы не можем предположить, что этот набор данных имеет нормальное распределение.
Это должно иметь смысл, учитывая, что мы сгенерировали данные с использованием логарифмически-нормальной функции распределения.
Метод 3: выполнить тест Шапиро-Уилка
В следующем коде показано, как выполнить алгоритм Шапиро-Уилка для набора данных, который соответствует логарифмически нормальному распределению:
import math
import numpy as np
from scipy.stats import shapiro
from scipy. stats import lognorm
#make this example reproducible
np.random.seed (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale=math. exp (1), size=1000)
#perform Shapiro-Wilk test for normality
shapiro(lognorm_dataset)
ShapiroResult(statistic=0.8573324680328369, pvalue=3.880663073872444e-29)
Из вывода мы видим, что тестовая статистика равна 0,857 , а соответствующее значение p равно 3,88e-29 (чрезвычайно близко к нулю).
Поскольку p-значение меньше 0,05, мы отвергаем нулевую гипотезу теста Шапиро-Уилка.
Это означает, что у нас есть достаточно доказательств, чтобы сказать, что данные выборки не получены из нормального распределения.
Метод 4: выполнить тест Колмогорова-Смирнова
В следующем коде показано, как выполнить тест Колмогорова-Смирнова для набора данных, который соответствует логарифмически нормальному распределению:
import math
import numpy as np
from scipy.stats import kstest
from scipy. stats import lognorm
#make this example reproducible
np.random.seed (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale=math. exp (1), size=1000)
#perform Kolmogorov-Smirnov test for normality
kstest(lognorm_dataset, 'norm')
KstestResult(statistic=0.84125708308077, pvalue=0.0)
Из вывода мы видим, что статистика теста равна 0,841 , а соответствующее значение p равно 0,0 .
Поскольку p-значение меньше 0,05, мы отвергаем нулевую гипотезу теста Колмогорова-Смирнова.
Это означает, что у нас есть достаточно доказательств, чтобы сказать, что данные выборки не получены из нормального распределения.
Как обращаться с ненормальными данными
Если данный набор данных не имеет нормального распределения, мы часто можем выполнить одно из следующих преобразований, чтобы сделать его более нормально распределенным:
1. Преобразование журнала: преобразование значений из x в log(x) .
2. Преобразование квадратного корня: преобразование значений из x в √ x .
3. Преобразование кубического корня: преобразование значений от x до x 1/3 .
Выполняя эти преобразования, набор данных обычно становится более нормально распределенным.
Прочтите этот учебник , чтобы узнать, как выполнять эти преобразования в Python.