Квадратичная регрессия — это тип регрессии, который мы можем использовать для количественной оценки связи между переменной-предиктором и переменной ответа, когда истинные отношения являются квадратичными, что может выглядеть как «U» или перевернутая «U» на графике.
То есть, когда переменная-предиктор увеличивается, переменная-отклик также имеет тенденцию к увеличению, но после определенного момента переменная-отклик начинает уменьшаться, поскольку переменная-предиктор продолжает увеличиваться.
В этом руководстве объясняется, как выполнить квадратичную регрессию в Python.
Пример: квадратичная регрессия в Python
Предположим, у нас есть данные о количестве отработанных часов в неделю и сообщаемом уровне счастья (по шкале от 0 до 100) для 16 разных людей:
import numpy as np
import scipy.stats as stats
#add legend
hours = [6, 9, 12, 12, 15, 21, 24, 24, 27, 30, 36, 39, 45, 48, 57, 60]
happ = [12, 18, 30, 42, 48, 78, 90, 96, 96, 90, 84, 78, 66, 54, 36, 24]
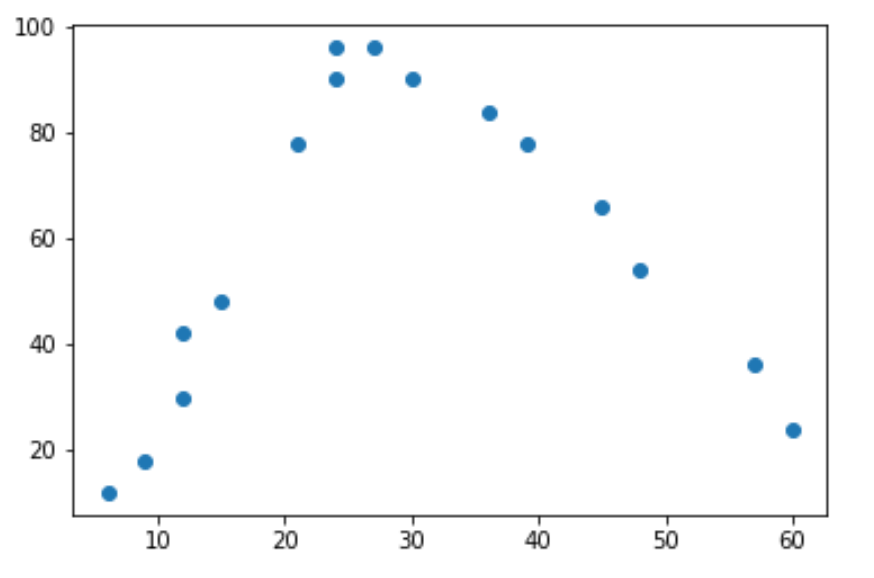
Если мы сделаем простую диаграмму рассеяния этих данных, мы увидим, что связь между двумя переменными имеет форму буквы «U»:
import matplotlib.pyplot as plt
#create scatterplot
plt.scatter(hours, happ)
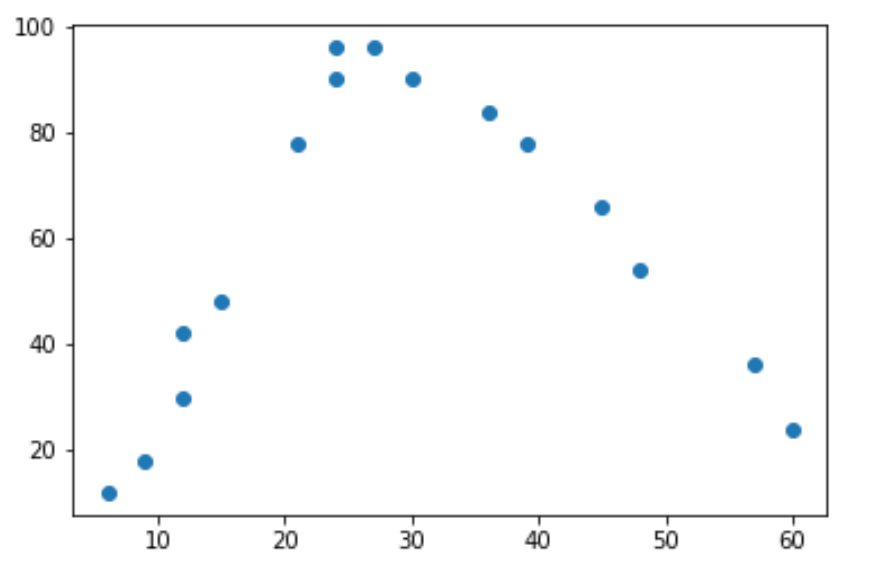
По мере увеличения количества отработанных часов увеличивается и счастье, но как только количество отработанных часов достигает 35 часов в неделю, счастье начинает снижаться.
Из-за этой формы «U» это означает, что квадратичная регрессия, вероятно, является хорошим кандидатом для количественной оценки взаимосвязи между двумя переменными.
Чтобы фактически выполнить квадратичную регрессию, мы можем подобрать модель полиномиальной регрессии со степенью 2, используя функцию numpy.polyfit() :
import numpy as np
#polynomial fit with degree = 2
model = np.poly1d(np.polyfit(hours, happ, 2))
#add fitted polynomial line to scatterplot
polyline = np.linspace(1, 60, 50)
plt.scatter(hours, happ)
plt.plot(polyline, model(polyline))
plt.show()
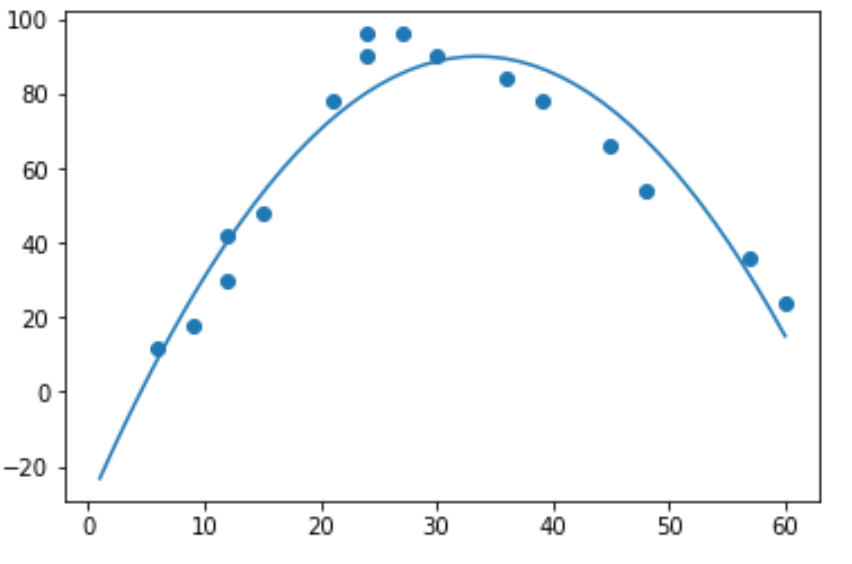
Мы можем получить подобранное уравнение полиномиальной регрессии, напечатав коэффициенты модели:
print(model)
-0.107x 2 + 7.173x - 30.25
Подходящее уравнение квадратичной регрессии:
Счастье = -0,107(час) 2 + 7,173(час) - 30,25
Мы можем использовать это уравнение для расчета ожидаемого уровня счастья человека на основе количества отработанных часов. Например, ожидаемый уровень счастья человека, который работает 30 часов в неделю, составляет:
Счастье = -0,107(30) 2 + 7,173(30) – 30,25 = 88,64 .
Мы также можем написать короткую функцию для получения R-квадрата модели, который представляет собой долю дисперсии переменной отклика, которая может быть объяснена переменными-предикторами.
#define function to calculate r-squared
def polyfit(x, y, degree):
results = {}
coeffs = np.polyfit(x, y, degree)
p = np.poly1d(coeffs)
#calculate r-squared
yhat = p(x)
ybar = np.sum(y)/len(y)
ssreg = np.sum((yhat-ybar)\*\*2)
sstot = np.sum((y - ybar)\*\*2)
results['r_squared'] = ssreg / sstot
return results
#find r-squared of polynomial model with degree = 3
polyfit(hours, happ, 2)
{'r_squared': 0.9092114182131691}
В этом примере R-квадрат модели равен 0,9092.Это означает, что 90,92% вариаций зарегистрированных уровней счастья можно объяснить предикторными переменными.
Дополнительные ресурсы
Как выполнить полиномиальную регрессию в Python
Как выполнить квадратичную регрессию в R
Как выполнить квадратичную регрессию в Excel