При использовании моделей классификации в машинном обучении общей метрикой, которую мы используем для оценки качества модели, является F1 Score .
Этот показатель рассчитывается как:
Оценка F1 = 2 * (Точность * Отзыв) / (Точность + Отзыв)
куда:
- Точность : правильные положительные прогнозы по отношению к общему количеству положительных прогнозов.
- Вспомнить : исправить положительные прогнозы по отношению к общему количеству фактических положительных результатов.
Например, предположим, что мы используем модель логистической регрессии, чтобы предсказать, попадут ли 400 разных баскетболистов из колледжа в НБА.
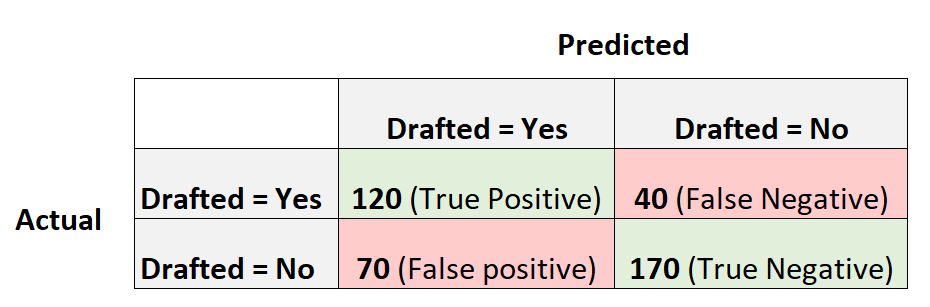
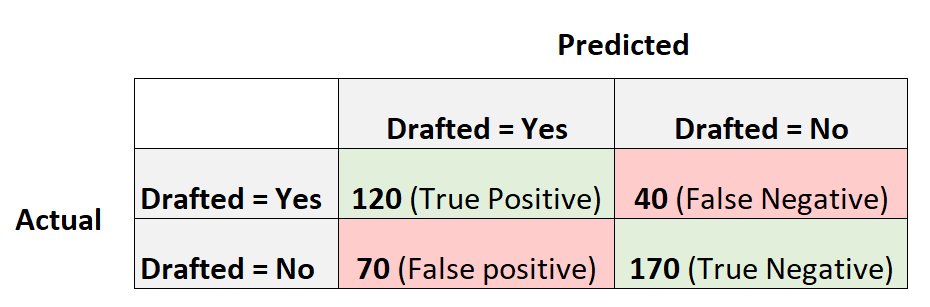
Следующая матрица путаницы суммирует прогнозы, сделанные моделью:
Вот как рассчитать оценку F1 модели:
Точность = истинный положительный результат / (истинный положительный результат + ложный положительный результат) = 120/(120+70) = 0,63157
Отзыв = истинно положительный / (истинно положительный + ложноотрицательный) = 120 / (120 + 40) = 0,75
Оценка F1 = 2 * (0,63157 * 0,75) / (0,63157 + 0,75) =.6857
Что такое хороший результат F1?
У студентов часто возникает вопрос:
Что такое хороший результат F1?
Проще говоря, более высокие баллы F1, как правило, лучше.
Напомним, что оценки F1 могут варьироваться от 0 до 1, где 1 представляет модель, которая идеально классифицирует каждое наблюдение в правильный класс, а 0 представляет модель, которая не может классифицировать какое-либо наблюдение в правильный класс.
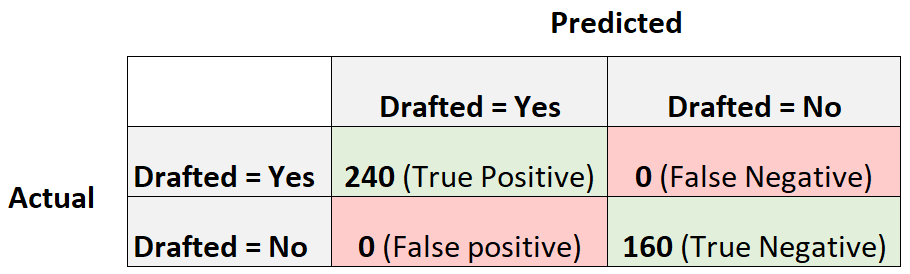
Чтобы проиллюстрировать это, предположим, что у нас есть модель логистической регрессии, которая создает следующую матрицу путаницы:
Вот как рассчитать оценку F1 модели:
Точность = истинный положительный результат / (истинный положительный результат + ложный положительный результат) = 240/(240+0) = 1
Отзыв = Истинно положительный / (Истинно положительный + Ложноотрицательный) = 240 / (240+0) = 1
Оценка F1 = 2 * (1 * 1) / (1 + 1) = 1
Оценка F1 равна единице, потому что она способна идеально классифицировать каждое из 400 наблюдений в класс.
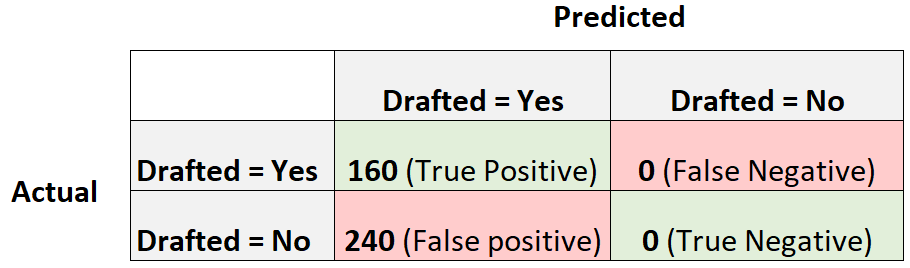
Теперь рассмотрим другую модель логистической регрессии, которая просто предсказывает, что каждый игрок будет выбран на драфте:
Вот как рассчитать оценку F1 модели:
Точность = истинный положительный результат / (истинный положительный результат + ложный положительный результат) = 160/(160+240) = 0,4
Отзыв = Истинно положительный / (Истинно положительный + Ложноотрицательный) = 160 / (160+0) = 1
Оценка F1 = 2 * (0,4 * 1) / (0,4 + 1) = 0,5714
Это будет считаться базовой моделью , с которой мы могли бы сравнить нашу модель логистической регрессии, поскольку она представляет собой модель, которая делает одинаковый прогноз для каждого отдельного наблюдения в наборе данных.
Чем больше наша оценка F1 по сравнению с базовой моделью, тем полезнее наша модель.
Напомним, что наша модель имела оценку F1 0,6857.Это не намного больше, чем 0,5714 , что указывает на то, что наша модель более полезна, чем базовая модель, но ненамного.
О сравнении результатов F1
На практике мы обычно используем следующий процесс, чтобы выбрать «лучшую» модель для задачи классификации:
Шаг 1: Подберите базовую модель, которая делает одинаковый прогноз для каждого наблюдения.
Шаг 2: Сопоставьте несколько разных моделей классификации и рассчитайте балл F1 для каждой модели.
Шаг 3: Выберите модель с наивысшим баллом F1 в качестве «лучшей» модели, убедившись, что она дает более высокий балл F1, чем базовая модель.
Не существует конкретного значения, которое считается «хорошим» результатом F1, поэтому мы обычно выбираем модель классификации, которая дает наивысший балл F1.
Дополнительные ресурсы
Оценка F1 против точности: что использовать?
Как рассчитать счет F1 в R
Как рассчитать счет F1 в Python