Когда мы создаем дерево решений для данного набора данных, мы используем только один обучающий набор данных для построения модели.
Однако недостатком использования одного дерева решений является высокая дисперсия.То есть, если мы разделим набор данных на две половины и применим дерево решений к обеим половинам, результаты могут быть совершенно разными.
Один метод, который мы можем использовать для уменьшения дисперсии одного дерева решений, известен как бэггинг , иногда называемый агрегированием начальной загрузки .
Бэггинг работает следующим образом:
1. Возьмите b образцов с начальной загрузкой из исходного набора данных.
2. Постройте дерево решений для каждого загруженного образца.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
Построив сотни или даже тысячи отдельных деревьев решений и взяв средние прогнозы из всех деревьев, мы часто получаем подогнанную модель с пакетами, которая дает гораздо более низкую частоту ошибок теста по сравнению с одним деревом решений.
В этом руководстве представлен пошаговый пример создания модели в пакете в R.
Шаг 1: Загрузите необходимые пакеты
Во-первых, мы загрузим необходимые пакеты для этого примера:
library(dplyr) #for data wrangling
library (e1071) #for calculating variable importance
library (caret) #for general model fitting
library (rpart) #for fitting decision trees
library (ipred) #for fitting bagged decision trees
Шаг 2: Установите модель в мешках
В этом примере мы будем использовать встроенный набор данных R под названием airquality , который содержит измерения качества воздуха в Нью-Йорке за 153 отдельных дня.
#view structure of airquality dataset
str(airquality)
'data.frame': 153 obs. of 6 variables:
$ Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
$ Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ...
$ Wind : num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...
$ Temp : int 67 72 74 62 56 66 65 59 61 69 ...
$ Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 5 6 7 8 9 10 ...
В следующем коде показано, как подогнать модель в пакете в R с помощью функции bagging () из библиотеки ipred .
#make this example reproducible
set.seed(1)
#fit the bagged model
bag <- bagging(
formula = Ozone ~ .,
data = airquality,
nbagg = 150 ,
coob = TRUE ,
control = rpart. control (minsplit = 2 , cp = 0 )
)
#display fitted bagged model
bag
Bagging regression trees with 150 bootstrap replications
Call: bagging.data.frame(formula = Ozone ~ ., data = airquality, nbagg = 150,
coob = TRUE, control = rpart.control(minsplit = 2, cp = 0))
Out-of-bag estimate of root mean squared error: 17.4973
Обратите внимание, что мы решили использовать 150 самозагруженных выборок для построения модели с пакетами, и мы указали для coob значение TRUE , чтобы получить расчетную ошибку вне пакета.
Мы также использовали следующие спецификации в функции rpart.control() :
- minsplit = 2: это говорит модели, что для разделения требуется только 2 наблюдения в узле.
- ср = 0.Это параметр сложности. Установив его на 0, мы не требуем, чтобы модель могла улучшить общую подгонку на любую величину, чтобы выполнить разделение.
По сути, эти два аргумента позволяют отдельным деревьям расти очень глубоко, что приводит к деревьям с высокой дисперсией, но с низким смещением. Затем, когда мы применяем бэггинг, мы можем уменьшить дисперсию окончательной модели, сохраняя при этом низкое смещение.
Из выходных данных модели мы видим, что среднеквадратичное отклонение, оцененное вне пакета, составляет 17,4973.Это средняя разница между прогнозируемым значением озона и фактически наблюдаемым значением.
Шаг 3. Визуализируйте важность предикторов
Хотя модели с пакетами, как правило, обеспечивают более точные прогнозы по сравнению с отдельными деревьями решений, трудно интерпретировать и визуализировать результаты подобранных моделей с пакетами.
Однако мы можем визуализировать важность переменных-предикторов, рассчитав общее снижение RSS (остаточную сумму квадратов) из-за разделения по заданному предиктору, усредненное по всем деревьям. Чем больше значение, тем важнее предиктор.
В следующем коде показано, как создать график важности переменных для подобранной модели в мешках, используя функцию varImp() из библиотеки Caret :
#calculate variable importance
VI <- data.frame(var= names (airquality[,-1]), imp= varImp (bag))
#sort variable importance descending
VI_plot <- VI[ order (VI$Overall, decreasing= TRUE ),]
#visualize variable importance with horizontal bar plot
barplot(VI_plot$Overall,
names.arg= rownames (VI_plot),
horiz= TRUE ,
col='steelblue',
xlab='Variable Importance')
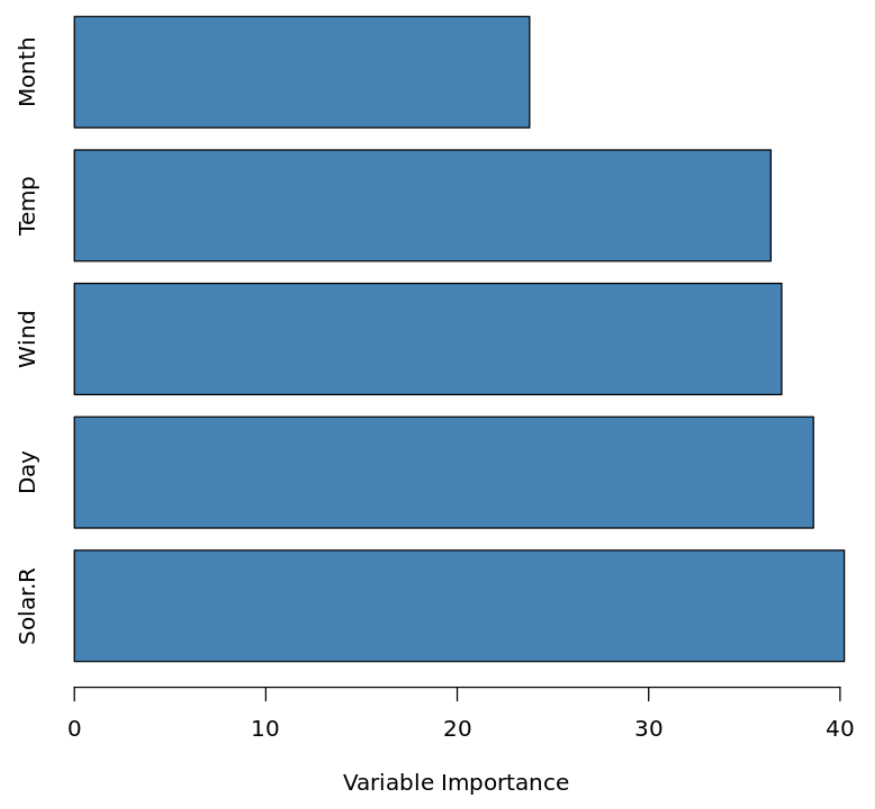
Мы видим, что Solar.R является самой важной предикторной переменной в модели, а Month — наименее важной.
Шаг 4: Используйте модель для прогнозирования
Наконец, мы можем использовать подобранную модель с мешками, чтобы делать прогнозы на основе новых наблюдений.
#define new observation
new <- data.frame(Solar.R=150, Wind=8, Temp=70, Month=5, Day=5)
#use fitted bagged model to predict Ozone value of new observation
predict(bag, newdata=new)
24.4866666666667
Основываясь на значениях переменных-предикторов, подобранная модель с мешками предсказывает, что значение озона будет 24,487 в этот конкретный день.
Полный код R, использованный в этом примере, можно найти здесь .