Чтобы оценить производительность модели в наборе данных, нам нужно измерить, насколько хорошо прогнозы модели соответствуют наблюдаемым данным.
Для регрессионных моделей наиболее часто используемой метрикой является среднеквадратическая ошибка (MSE), которая рассчитывается как:
MSE = (1/n)*Σ(y i – f(x i )) 2
куда:
- n: общее количество наблюдений
- y i : значение отклика i -го наблюдения
- f(x i ): прогнозируемое значение отклика i -го наблюдения.
Чем ближе прогнозы модели к наблюдениям, тем меньше будет MSE.
Однако нас интересует только тестовая MSE — MSE, когда наша модель применяется к невидимым данным. Это потому, что мы заботимся только о том, как модель будет работать с невидимыми данными, а не с существующими данными.
Например, хорошо, если модель, предсказывающая цены на фондовом рынке, имеет низкое среднеквадратичное отклонение на исторических данных, но мы действительно хотим иметь возможность использовать эту модель для точного прогнозирования будущих данных.
Получается, что тест MSE всегда можно разложить на две части:
(1) Дисперсия: относится к величине, на которую изменилась бы наша функция f , если бы мы оценили ее, используя другой обучающий набор.
(2) Смещение: Относится к ошибке, возникающей при аппроксимации реальной проблемы, которая может быть чрезвычайно сложной, гораздо более простой моделью.
Написано математическими терминами:
СКО теста = Var( f̂( x0)) + [Bias( f̂( x0))] 2 + Var(ε)
СКО теста = дисперсия + погрешность 2 + неустранимая ошибка
Третье слагаемое, неустранимая ошибка, — это ошибка, которую нельзя уменьшить с помощью какой-либо модели просто потому, что всегда существует некоторый шум в отношениях между набором объясняющих переменных и переменной отклика .
Модели с высоким смещением , как правило, имеют низкую дисперсию.Например, модели линейной регрессии, как правило, имеют высокое смещение (предполагает простую линейную связь между независимыми переменными и переменной отклика) и низкую дисперсию (оценки модели не будут сильно меняться от одной выборки к другой).
Однако модели с низким смещением , как правило, имеют высокую дисперсию.Например, сложные нелинейные модели, как правило, имеют низкое смещение (не предполагает определенной связи между независимыми переменными и переменной отклика) с высокой дисперсией (оценки модели могут сильно меняться от одной обучающей выборки к другой).
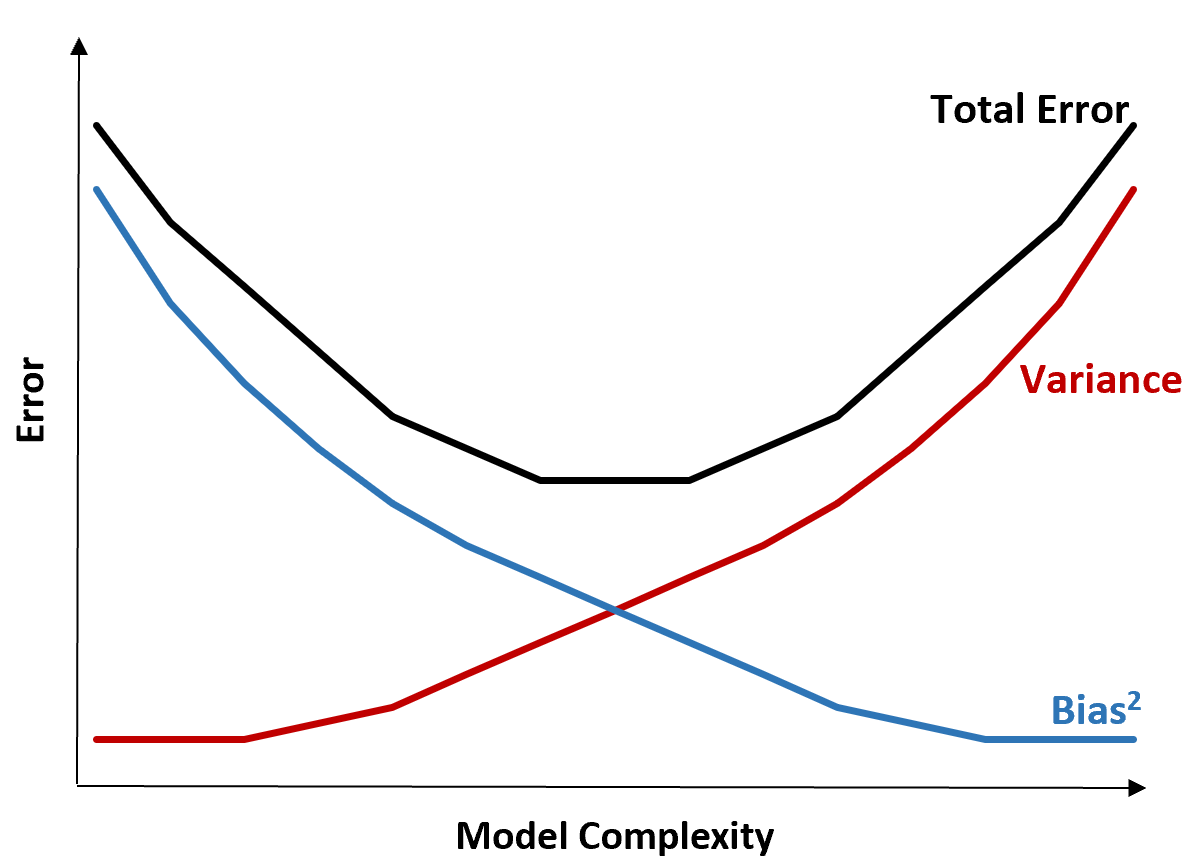
Компромисс смещения и дисперсии
Компромисс между смещением и дисперсией относится к компромиссу, который имеет место, когда мы решаем снизить смещение, что обычно увеличивает дисперсию, или уменьшить дисперсию, что обычно увеличивает смещение.
Следующая диаграмма предлагает способ визуализации этого компромисса:
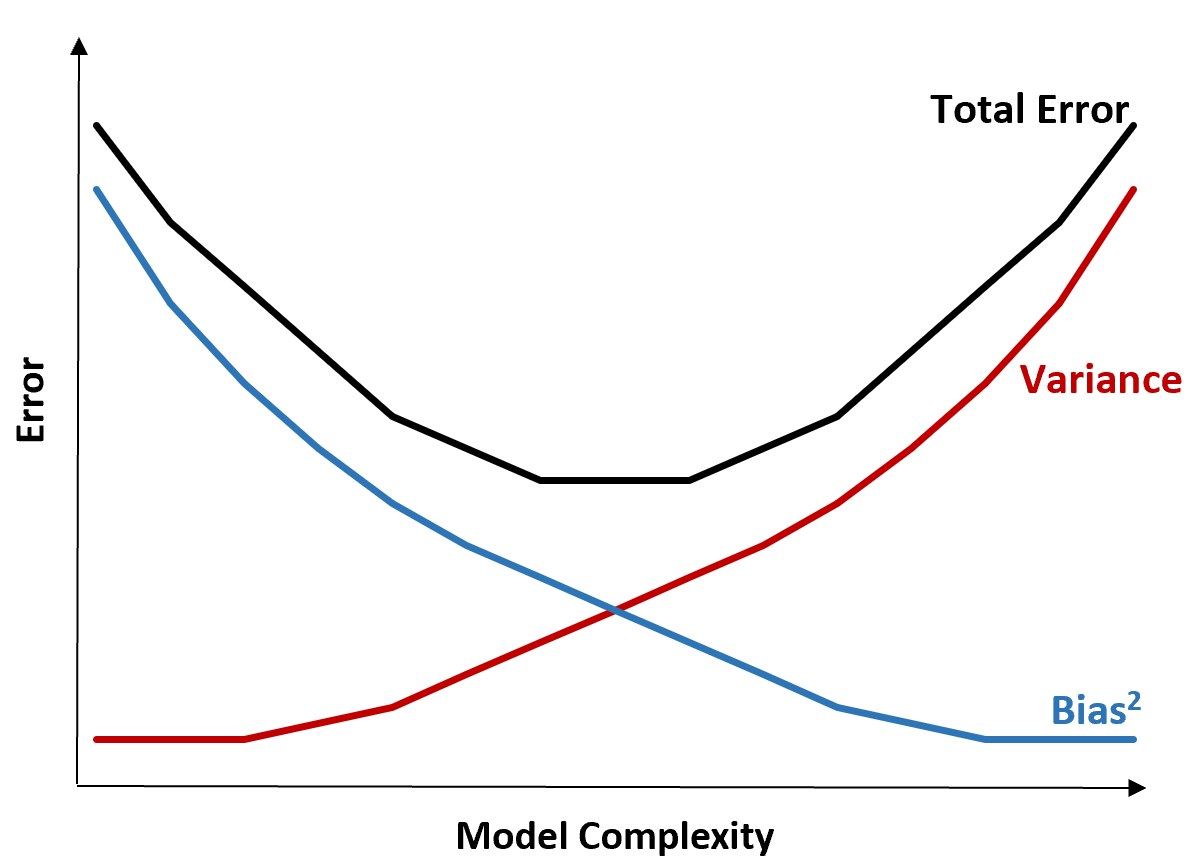
Общая ошибка уменьшается по мере увеличения сложности модели, но только до определенного момента. После определенного момента дисперсия начинает увеличиваться, и общая ошибка также начинает увеличиваться.
На практике нас интересует только минимизация общей ошибки модели, а не обязательно минимизация дисперсии или систематической ошибки. Оказывается, чтобы минимизировать общую ошибку, нужно найти правильный баланс между дисперсией и погрешностью.
Другими словами, нам нужна модель, которая достаточно сложна, чтобы фиксировать истинную связь между независимыми переменными и переменной отклика, но не слишком сложна, чтобы находить шаблоны, которых на самом деле не существует.
Когда модель слишком сложна, она подгоняет данные. Это происходит потому, что слишком сложно найти закономерности в обучающих данных, которые просто вызваны случайностью. Этот тип модели, вероятно, будет плохо работать с невидимыми данными.
Но когда модель слишком проста, она не соответствует данным. Это происходит потому, что предполагается, что истинная связь между объясняющими переменными и переменной отклика более проста, чем она есть на самом деле.
Способ выбора оптимальных моделей в машинном обучении состоит в том, чтобы найти баланс между смещением и дисперсией, чтобы мы могли минимизировать ошибку тестирования модели на будущих невидимых данных.
На практике наиболее распространенным способом минимизации тестовой MSE является использование перекрестной проверки .