В области машинного обучения мы часто строим модели, чтобы иметь возможность делать точные прогнозы относительно какого-либо явления.
Например, предположим, что мы хотим построить регрессионную модель , которая использует предикторную переменную количество часов, потраченных на учебу , чтобы предсказать ответную переменную балла ACT для учащихся средней школы.
Чтобы построить эту модель, мы соберем данные о часах, потраченных на учебу, и соответствующий балл ACT для сотен учащихся в определенном школьном округе.
Затем мы будем использовать эти данные для обучения модели, которая может прогнозировать оценку, которую получит данный учащийся, исходя из общего количества часов обучения.
Чтобы оценить, насколько полезна модель, мы можем измерить, насколько хорошо прогнозы модели соответствуют наблюдаемым данным. Одной из наиболее часто используемых метрик для этого является среднеквадратическая ошибка (MSE), которая рассчитывается как:
MSE = (1/n)*Σ(y i – f(x i )) 2
куда:
- n: общее количество наблюдений
- y i : значение отклика i -го наблюдения
- f(x i ): прогнозируемое значение отклика i -го наблюдения.
Чем ближе прогнозы модели к наблюдениям, тем меньше будет MSE.
Однако одна из самых больших ошибок, допущенных в машинном обучении, — это оптимизация моделей для уменьшения MSE обучения , т. е. насколько точно прогнозы модели совпадают с данными, которые мы использовали для обучения модели.
Когда модель слишком много внимания уделяет снижению MSE обучения, она часто слишком усердно работает, чтобы найти закономерности в обучающих данных, которые просто вызваны случайностью. Затем, когда модель применяется к невидимым данным, она работает плохо.
Это явление известно как переобучение.Это происходит, когда мы слишком близко «приспосабливаем» модель к обучающим данным и, таким образом, в конечном итоге строим модель, которая бесполезна для прогнозирования новых данных.
Пример переобучения
Чтобы понять переоснащение, вернемся к примеру создания регрессионной модели, которая использует часы, потраченные на обучение , для прогнозирования оценки ACT .
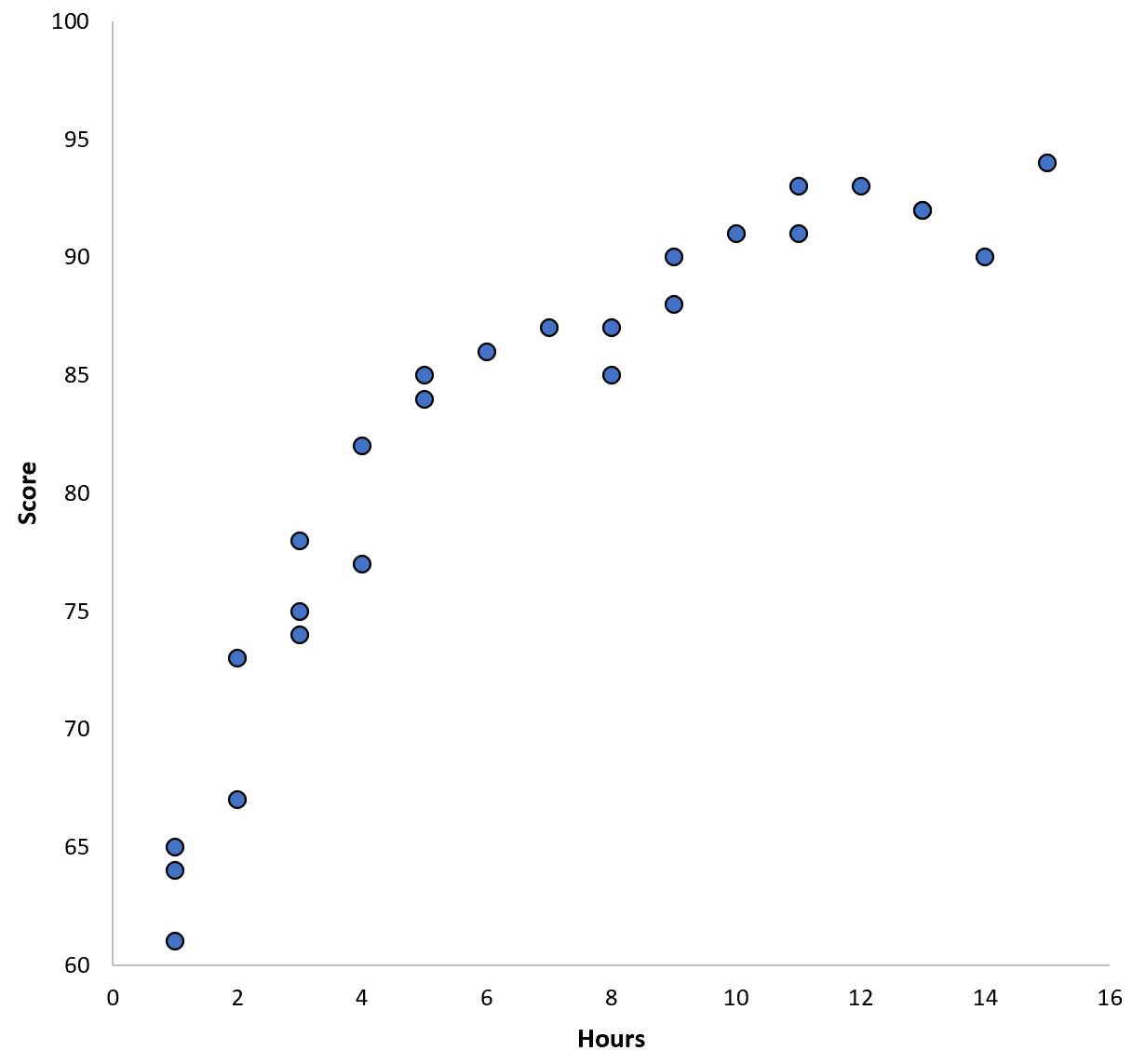
Предположим, мы собираем данные для 100 учащихся в определенном школьном округе и создаем быструю диаграмму рассеяния, чтобы визуализировать взаимосвязь между двумя переменными:
Отношения между двумя переменными кажутся квадратичными, поэтому предположим, что мы подходим к следующей модели квадратичной регрессии:
Оценка = 60,1 + 5,4*(Часы) – 0,2*(Часы) 2
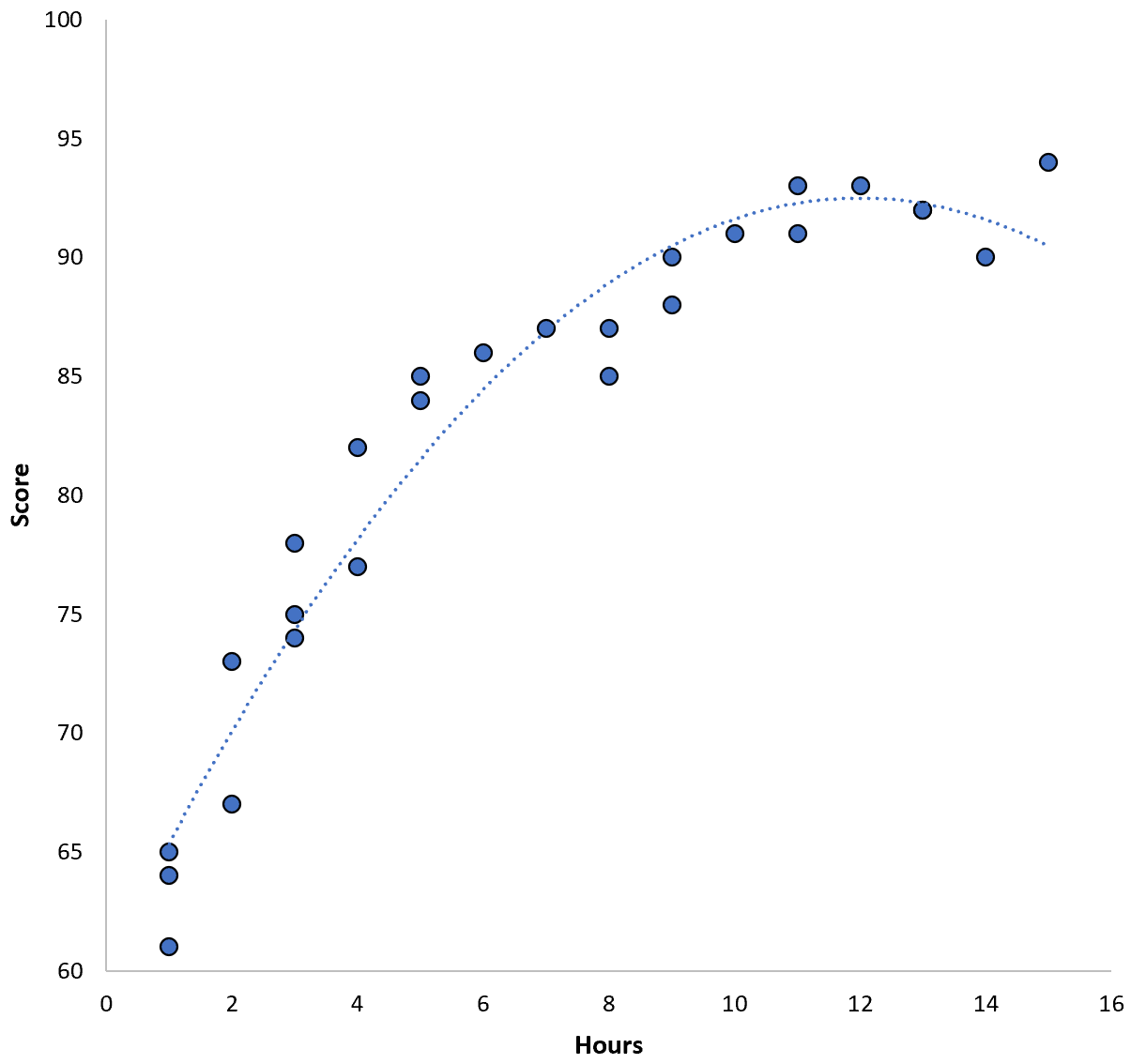
Эта модель имеет среднеквадратичную ошибку обучения (MSE) 3,45.То есть среднеквадратическая разница между прогнозами, сделанными моделью, и фактическими оценками ACT составляет 3,45.
Однако мы могли бы уменьшить эту обучающую MSE, подобрав полиномиальную модель более высокого порядка. Например, предположим, что мы подходим к следующей модели:
Оценка = 64,3 – 7,1*(часы) + 8,1*(часы) 2 – 2,1*(часы) 3 + 0,2*(часы) 4 – 0,1*(часы) 5 + 0,2(часы) 6
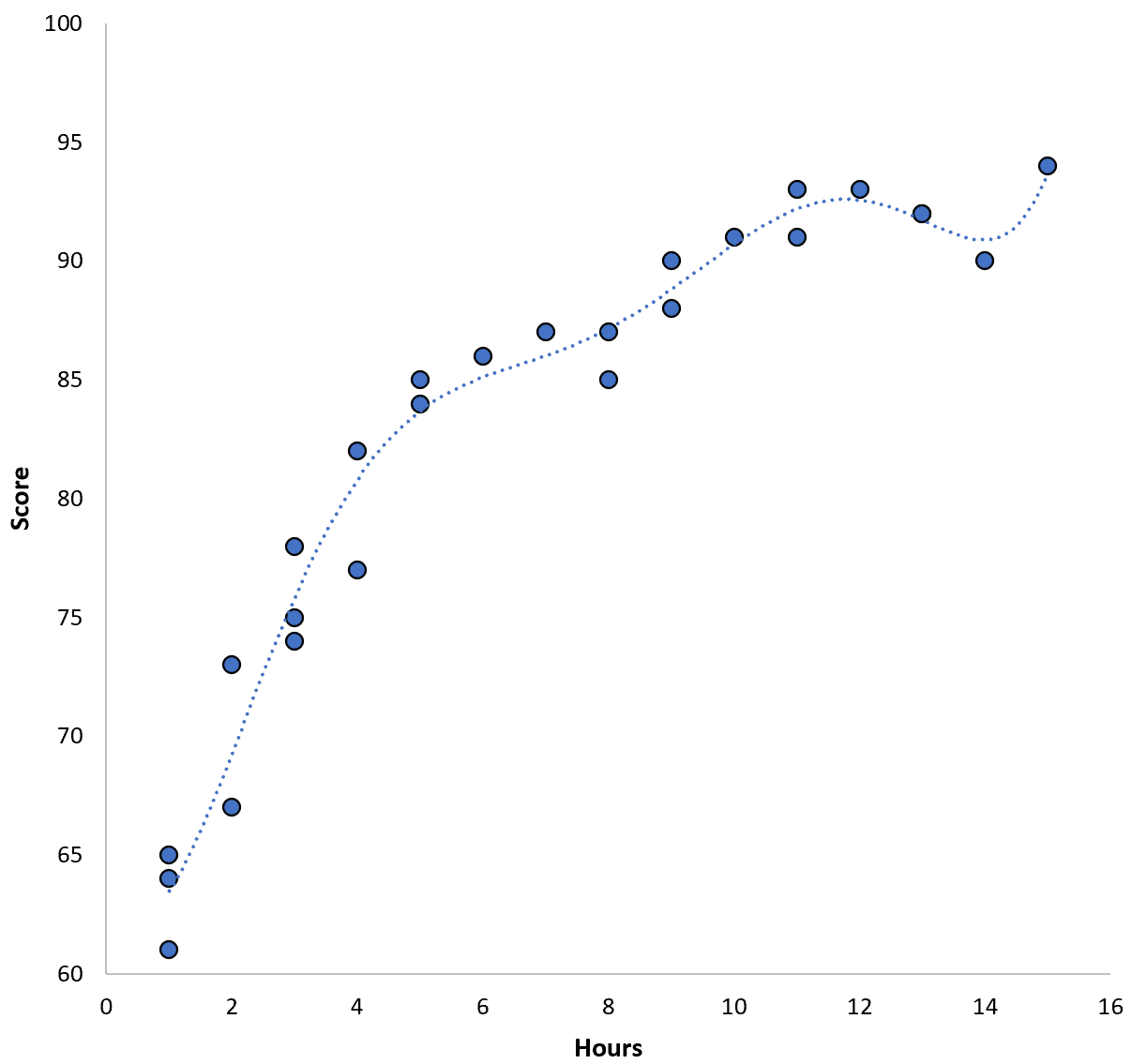
Обратите внимание, как линия регрессии гораздо ближе подходит к фактическим данным, чем предыдущая линия регрессии.
Эта модель имеет среднеквадратичную ошибку обучения (MSE) всего 0,89.То есть среднеквадратическая разница между прогнозами, сделанными моделью, и фактическими оценками ACT составляет 0,89.
Эта обучающая MSE намного меньше, чем у предыдущей модели.
Однако на самом деле нас не волнует обучающая MSE , т. е. насколько точно прогнозы модели совпадают с данными, которые мы использовали для обучения модели. Вместо этого нас в основном волнует тестовая MSE — MSE, когда наша модель применяется к невидимым данным.
Если бы мы применили приведенную выше модель полиномиальной регрессии более высокого порядка к невидимому набору данных, она, вероятно, работала бы хуже, чем более простая модель квадратичной регрессии. То есть это приведет к более высокому тестовому MSE, а это именно то, чего мы не хотим.
Как обнаружить и избежать переобучения
Самый простой способ обнаружить переобучение — выполнить перекрестную проверку. Наиболее часто используемый метод известен как k-кратная перекрестная проверка , и он работает следующим образом:
Шаг 1: Случайным образом разделите набор данных на k групп или «складок» примерно одинакового размера.
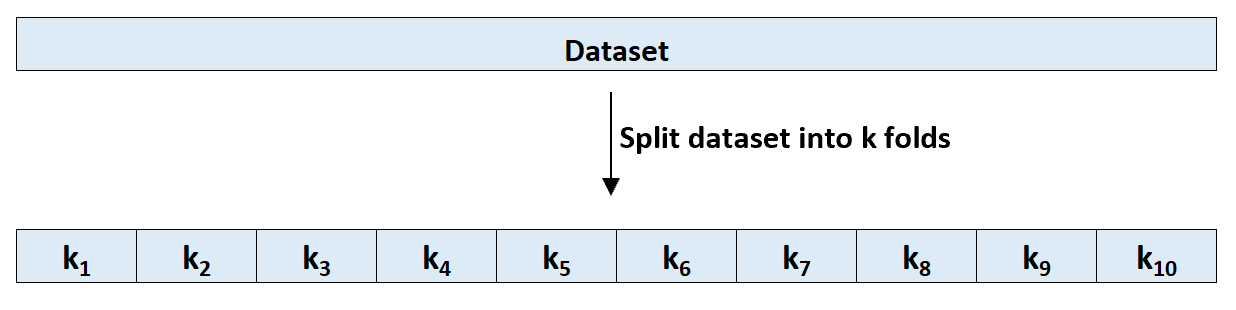
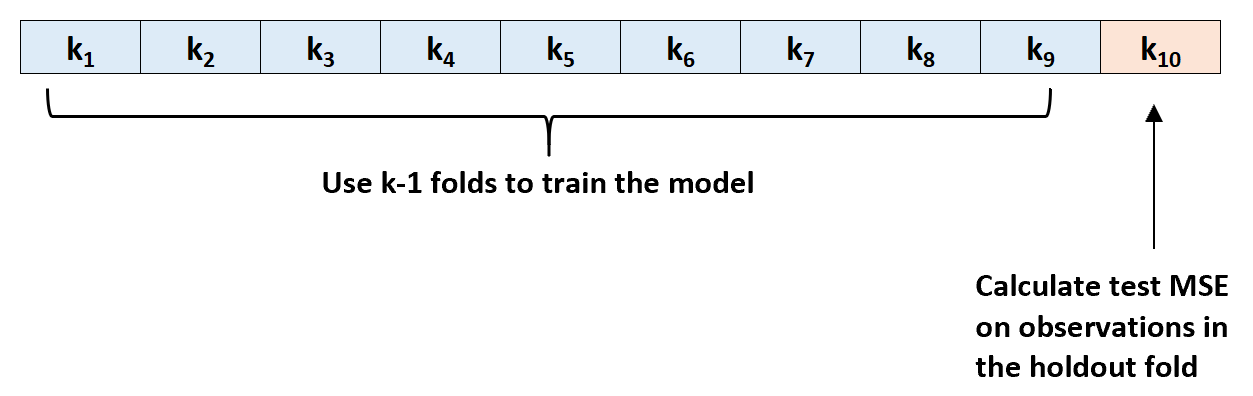
Шаг 2: Выберите один из сгибов в качестве опорного набора. Соедините модель с оставшимися k-1 складками. Рассчитайте тестовую MSE по наблюдениям в протянутой кратности.
Шаг 3: Повторите этот процесс k раз, используя каждый раз другой набор в качестве набора удержания.
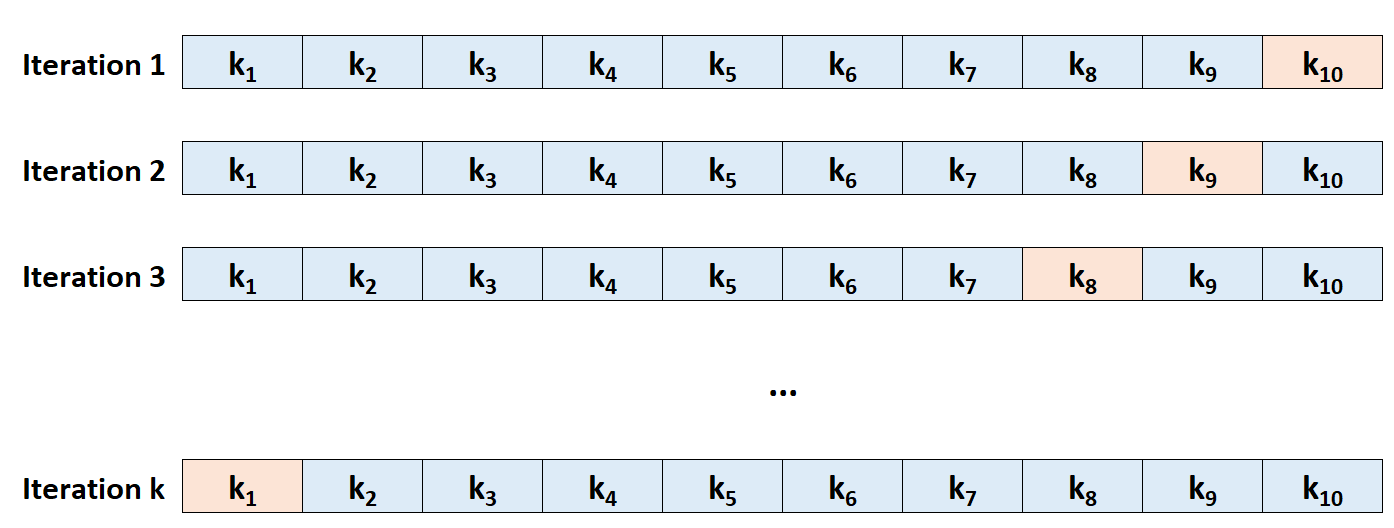
Шаг 4: Рассчитайте общую тестовую MSE как среднее значение k тестовых MSE.
СКО теста = (1/k)*ΣСКО i
куда:
- k: количество складок
- MSE i : проверка MSE на i -й итерации.
Этот тестовый MSE дает нам хорошее представление о том, как данная модель будет работать с невидимыми данными.
На практике мы можем подобрать несколько разных моделей и выполнить k-кратную перекрестную проверку каждой модели, чтобы узнать ее тестовую MSE. Затем мы можем выбрать модель с самой низкой тестовой MSE как лучшую модель для прогнозирования в будущем.
Это гарантирует, что мы выберем модель, которая, вероятно, будет лучше всего работать с будущими данными, в отличие от модели, которая просто минимизирует обучающую MSE и хорошо «соответствует» историческим данным.
Дополнительные ресурсы
Что такое компромисс смещения и дисперсии в машинном обучении?
Введение в перекрестную проверку K-Fold
Регрессия и модели классификации в машинном обучении