Когда связь между набором переменных-предикторов и переменной отклика является линейной, мы можем использовать такие методы, как множественная линейная регрессия , для моделирования связи между переменными.
Однако, когда отношения более сложны, нам часто приходится полагаться на нелинейные методы.
Одним из таких методов являются деревья классификации и регрессии (часто сокращенно CART), которые используют набор переменных-предикторов для построения деревьев решений, которые предсказывают значение переменной ответа.
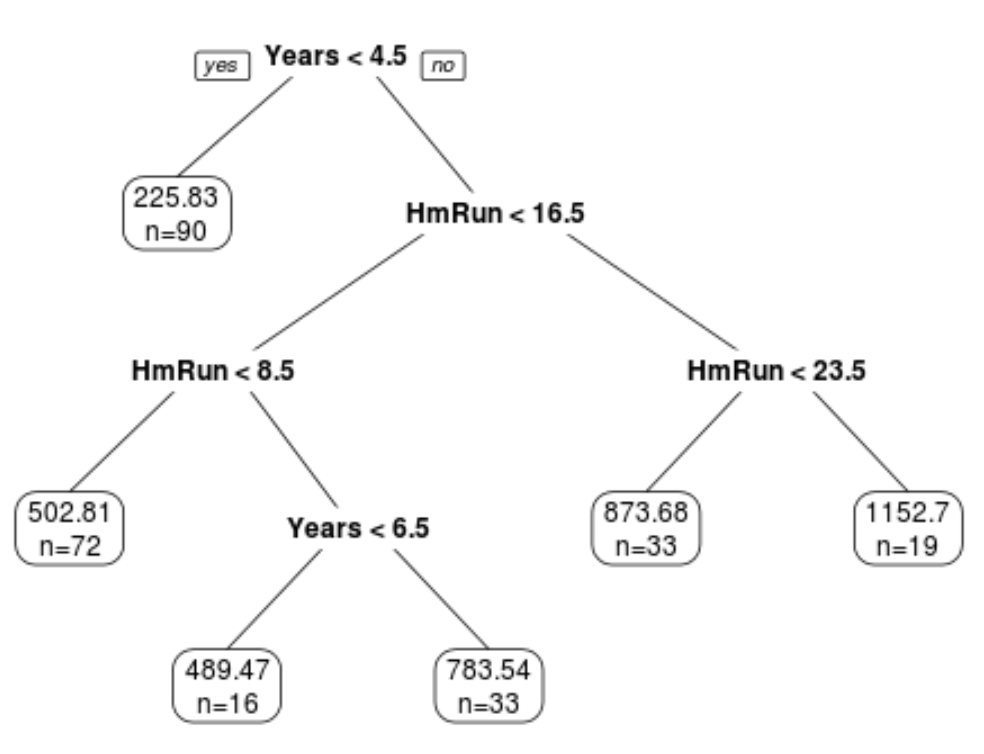
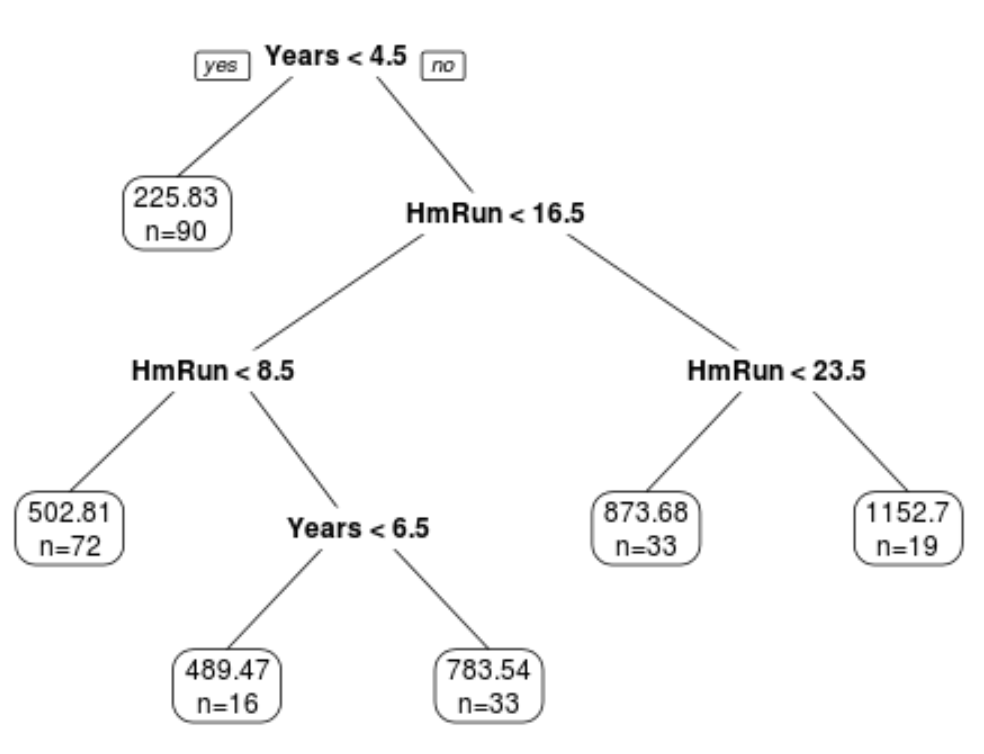
Пример дерева регрессии, которое использует многолетний опыт и средние хоумраны для прогнозирования зарплаты профессионального бейсболиста. Однако недостатком моделей CART является то, что они, как правило, имеют высокую дисперсию.То есть, если мы разделим набор данных на две половины и применим дерево решений к обеим половинам, результаты могут быть совершенно разными.
Один из методов, который мы можем использовать для уменьшения дисперсии моделей CART, известен как бэггинг , иногда называемый агрегацией начальной загрузки .
Что такое Бэггинг?
Когда мы создаем одно дерево решений, мы используем только один обучающий набор данных для построения модели.
Однако при бэггинге используется следующий метод:
1. Возьмите b образцов с начальной загрузкой из исходного набора данных.
- Напомним, что бутстрепная выборка — это выборка исходного набора данных, в которой наблюдения берутся с заменой.
2. Постройте дерево решений для каждого загруженного образца.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
- Для деревьев регрессии мы берем среднее значение прогноза, сделанного B -деревьями.
- Для деревьев классификации мы берем наиболее часто встречающееся предсказание, сделанное B -деревьями.
Бэггинг можно использовать с любым алгоритмом машинного обучения, но он особенно полезен для деревьев решений, потому что они по своей природе имеют высокую дисперсию, а бэггинг может значительно уменьшить дисперсию, что приводит к меньшей ошибке теста.
Чтобы применить пакетирование к деревьям решений, мы глубоко выращиваем B отдельных деревьев, не обрезая их. Это приводит к тому, что отдельные деревья имеют высокую дисперсию, но низкое смещение. Затем, когда мы берем средние прогнозы из этих деревьев, мы можем уменьшить дисперсию.
На практике оптимальная производительность обычно достигается при использовании от 50 до 500 деревьев, но для создания окончательной модели можно использовать тысячи деревьев.
Просто имейте в виду, что установка большего количества деревьев потребует большей вычислительной мощности, что может быть или не быть проблемой в зависимости от размера набора данных.
Оценка ошибки «вне упаковки»
Получается, что мы можем вычислить ошибку теста модели в мешках, не полагаясь на k-кратную перекрестную проверку .
Причина в том, что можно показать, что каждая выборка с начальной загрузкой содержит около 2/3 наблюдений из исходного набора данных. Оставшаяся 1/3 наблюдений, не используемых для подгонки под дерево в мешках, называется наблюдениями вне мешка (OOB) .
Мы можем предсказать значение для i-го наблюдения в исходном наборе данных, взяв среднее значение для каждого дерева, в котором это наблюдение было OOB.
Мы можем использовать этот подход, чтобы сделать прогноз для всех n наблюдений в исходном наборе данных и, таким образом, рассчитать частоту ошибок, которая является достоверной оценкой ошибки теста.
Преимущество использования этого подхода для оценки ошибки теста заключается в том, что он намного быстрее, чем перекрестная проверка в k-кратном порядке, особенно когда набор данных большой.
Понимание важности предикторов
Напомним, что одно из преимуществ деревьев решений заключается в том, что их легко интерпретировать и визуализировать.
Когда вместо этого мы используем пакетирование, мы больше не можем интерпретировать или визуализировать отдельное дерево, поскольку окончательная модель с пакетами является результатом усреднения множества разных деревьев. Мы получаем точность предсказания за счет интерпретируемости.
Тем не менее, мы все еще можем понять важность каждой переменной-предиктора, вычислив общее снижение RSS (остаточную сумму квадратов) из-за разделения по заданному предиктору, усредненное по всем B -деревьям. Чем больше значение, тем важнее предиктор.
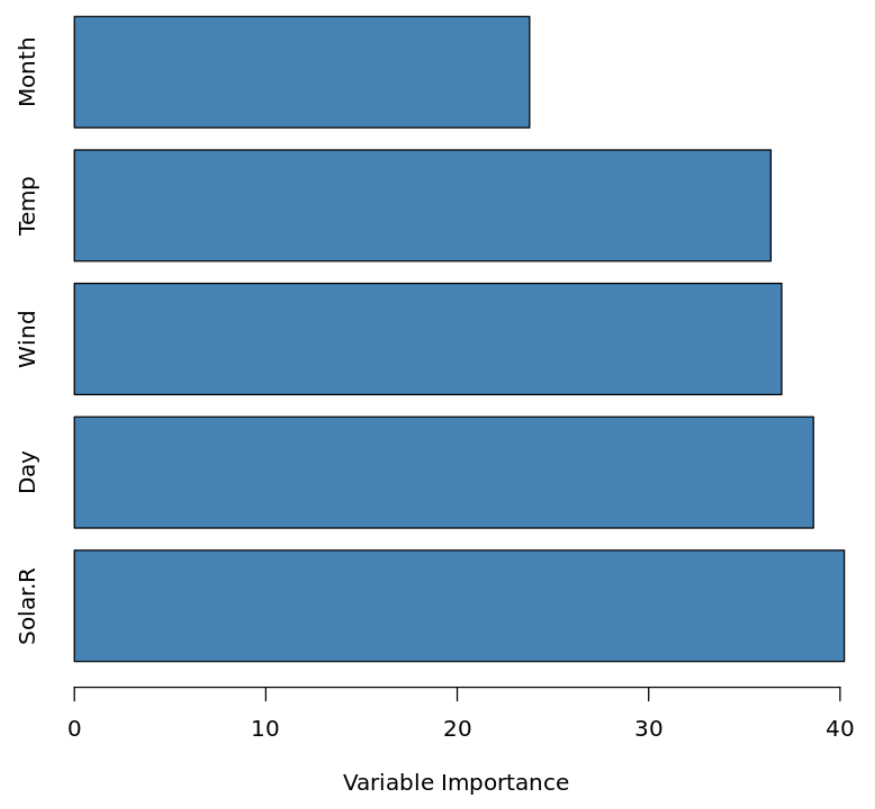
Пример графика переменной важности. Точно так же для моделей классификации мы можем рассчитать общее снижение индекса Джини из-за разделения по заданному предиктору, усредненное по всем B -деревьям. Чем больше значение, тем важнее предиктор.
Таким образом, хотя мы не можем точно интерпретировать окончательную модель с пакетами, мы все же можем получить представление о том, насколько важна каждая предикторная переменная при прогнозировании отклика.
Выходя за рамки мешков
Преимущество бэггинга заключается в том, что он обычно предлагает улучшение частоты ошибок при тестировании по сравнению с одним деревом решений.
Недостатком является то, что прогнозы из коллекции деревьев в мешках могут быть сильно коррелированы, если в наборе данных окажется очень сильный предиктор.
В этом случае большинство или все деревья в мешках будут использовать этот предиктор для первого разбиения, что приведет к деревьям, которые похожи друг на друга и имеют сильно коррелированные прогнозы.
Один из способов обойти эту проблему — вместо этого использовать случайные леса, которые используют метод, аналогичный бэггингу, но могут создавать декоррелированные деревья, что часто приводит к снижению частоты ошибок при тестировании.
Вы можете прочитать простое введение в случайные леса здесь .
Дополнительные ресурсы
Введение в деревья классификации и регрессии
Как выполнить бэггинг в R (шаг за шагом)