Когда взаимосвязь между набором переменных-предикторов и переменной отклика очень сложна, мы часто используем нелинейные методы для моделирования взаимосвязи между ними.
Одним из таких методов являются деревья классификации и регрессии (часто сокращенно CART), которые используют набор переменных-предикторов для построения деревьев решений, которые предсказывают значение переменной ответа.
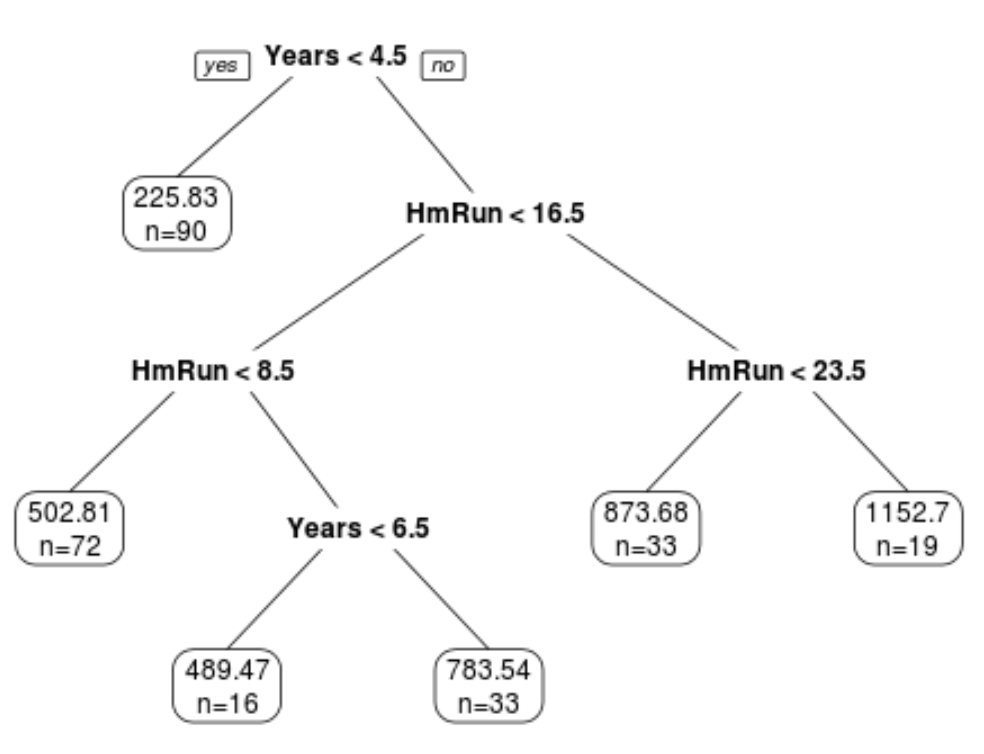
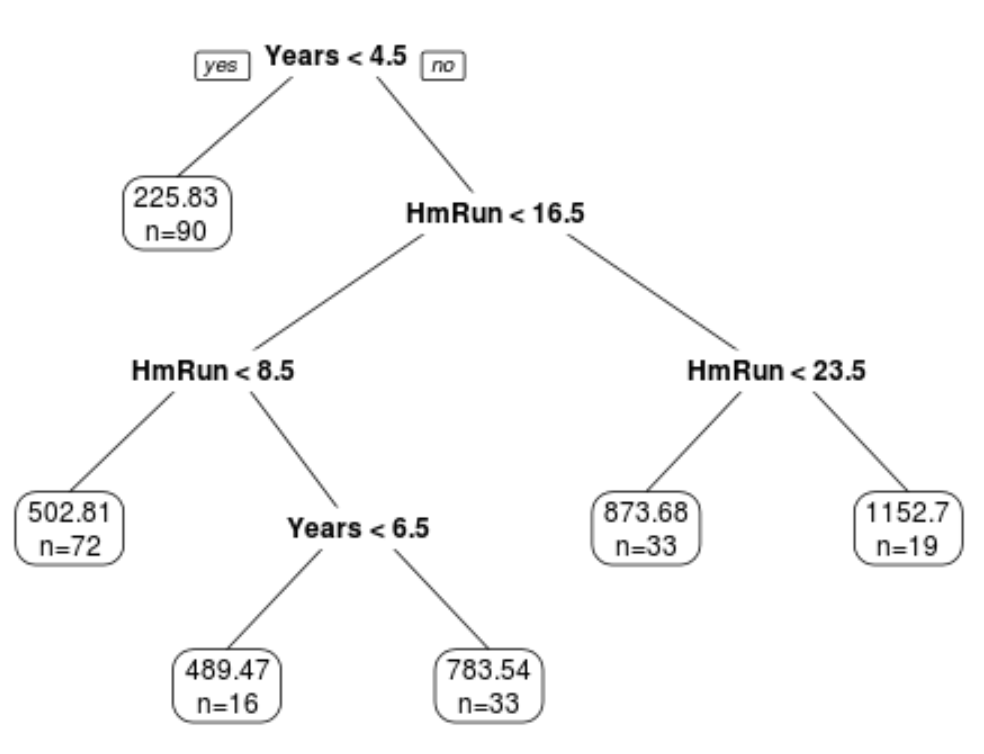
Пример дерева регрессии, которое использует многолетний опыт и средние хоумраны для прогнозирования зарплаты профессионального бейсболиста. Преимущество деревьев решений заключается в том, что их легко интерпретировать и визуализировать. Недостатком является то, что они, как правило, страдают от высокой дисперсии.То есть, если мы разделим набор данных на две половины и применим дерево решений к обеим половинам, результаты могут быть совершенно разными.
Один из способов уменьшить дисперсию деревьев решений — использовать метод, известный как бэггинг , который работает следующим образом:
1. Возьмите b образцов с начальной загрузкой из исходного набора данных.
2. Постройте дерево решений для каждого загруженного образца.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
Преимущество этого подхода заключается в том, что модель с пакетами обычно предлагает улучшение частоты ошибок при тестировании по сравнению с одним деревом решений.
Недостатком является то, что прогнозы из коллекции деревьев в мешках могут быть сильно коррелированы, если в наборе данных окажется очень сильный предиктор. В этом случае большинство или все деревья в мешках будут использовать этот предиктор для первого разбиения, что приведет к деревьям, которые похожи друг на друга и имеют сильно коррелированные прогнозы.
Таким образом, когда мы усредняем прогнозы каждого дерева, чтобы получить окончательную модель с пакетами, возможно, что эта модель на самом деле не сильно уменьшает дисперсию по сравнению с одним деревом решений.
Один из способов обойти эту проблему — использовать метод, известный как случайный лес .
Что такое случайные леса?
Подобно бэггингу, случайные леса также берут b бутстрепных выборок из исходного набора данных.
Однако при построении дерева решений для каждой выборки с начальной загрузкой каждый раз, когда рассматривается разделение дерева, только случайная выборка из m предикторов рассматривается как кандидаты на разделение из полного набора p предикторов.
Итак, вот полный метод, который случайные леса используют для построения модели:
1. Возьмите b образцов с начальной загрузкой из исходного набора данных.
2. Постройте дерево решений для каждого загруженного образца.
- При построении дерева каждый раз, когда рассматривается разделение, только случайная выборка из m предикторов рассматривается как кандидаты на разделение из полного набора p предикторов.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
При использовании этого метода коллекция деревьев в случайном лесу декоррелирована по сравнению с деревьями, полученными путем упаковки в мешки.
Таким образом, когда мы берем средние прогнозы каждого дерева, чтобы получить окончательную модель, она, как правило, имеет меньшую изменчивость и приводит к более низкой частоте ошибок теста по сравнению с моделью с пакетами.
При использовании случайных лесов мы обычно рассматриваем m = √ p предикторов как кандидатов на разделение каждый раз, когда мы разделяем дерево решений.
Например, если у нас есть p = 16 полных предикторов в наборе данных, то мы обычно рассматриваем только m = √16 = 4 предиктора в качестве потенциальных кандидатов на разделение при каждом разделении.
Техническое примечание:
Интересно отметить, что если мы выбираем m = p (т. е. мы рассматриваем все предикторы как кандидатов на разделение при каждом разделении), то это эквивалентно простому использованию упаковки.
Оценка ошибки «вне упаковки»
Как и в случае с бэггингом, мы можем рассчитать ошибку теста модели случайного леса, используя оценку вне пакета .
Можно показать, что каждая загруженная выборка содержит около 2/3 наблюдений из исходного набора данных. Оставшаяся 1/3 наблюдений, не использованных для подгонки под дерево, называется наблюдениями вне пакета (OOB) .
Мы можем предсказать значение для i-го наблюдения в исходном наборе данных, взяв среднее значение для каждого дерева, в котором это наблюдение было OOB.
Мы можем использовать этот подход, чтобы сделать прогноз для всех n наблюдений в исходном наборе данных и, таким образом, рассчитать частоту ошибок, которая является достоверной оценкой ошибки теста.
Преимущество использования этого подхода для оценки ошибки теста заключается в том, что он намного быстрее, чем k-кратная перекрестная проверка , особенно при большом наборе данных.
Плюсы и минусы случайных лесов
Случайные леса предлагают следующие преимущества :
- В большинстве случаев случайные леса обеспечивают повышение точности по сравнению с моделями с пакетами и особенно по сравнению с одиночными деревьями решений.
- Случайные леса устойчивы к выбросам.
- Для использования случайных лесов предварительная обработка не требуется.
Однако случайные леса имеют следующие потенциальные недостатки:
- Их трудно интерпретировать.
- Они могут быть ресурсоемкими (т.е. медленными) для построения больших наборов данных.
На практике специалисты по данным обычно используют случайные леса, чтобы максимизировать точность прогнозов, поэтому тот факт, что их нелегко интерпретировать, обычно не является проблемой.