В области статистики можно выделить два основных направления:
- Описательная статистика
- Выведенный статистика
В этом руководстве объясняется разница между двумя ветвями и почему каждая из них полезна в определенных ситуациях.
Описательная статистика
В двух словах, описательная статистика предназначена для описания фрагмента необработанных данных с использованием сводной статистики, графиков и таблиц.
Описательная статистика полезна, потому что она позволяет гораздо быстрее и проще понять группу данных по сравнению с простым просмотром строк и строк необработанных значений данных.
Например, предположим, что у нас есть набор необработанных данных, показывающих результаты тестов 1000 учащихся в определенной школе. Нас может заинтересовать средний балл теста вместе с распределением тестов.
Используя описательную статистику, мы могли бы найти средний балл и построить график, который поможет нам визуализировать распределение баллов.
Это позволяет нам гораздо легче понять результаты тестов студентов по сравнению с простым просмотром необработанных данных.
Общие формы описательной статистики
Существуют три распространенные формы описательной статистики:
1. Сводная статистика. Это статистические данные, которые суммируют данные с использованием одного числа. Существует два популярных типа сводной статистики:
- Меры центральной тенденции : эти числа описывают, где расположен центр набора данных. Примеры включают среднееи медиана .
- Меры дисперсии : эти числа описывают, насколько разбросаны значения в наборе данных. Примеры включают размах , межквартильный размах , стандартное отклонение и дисперсию .
2. Графики.Графики помогают нам визуализировать данные. Общие типы графиков, используемых для визуализации данных, включают в себя коробчатые диаграммы , гистограммы , диаграммы ствола и листьев и диаграммы рассеяния .
3. Таблицы.Таблицы могут помочь нам понять, как распределяются данные. Одним из распространенных типов таблиц является таблица частот , которая сообщает нам, сколько значений данных попадает в определенные диапазоны.
Пример использования описательной статистики
Следующий пример иллюстрирует, как мы можем использовать описательную статистику в реальном мире.
Предположим, что 1000 учеников одной школы сдают один и тот же тест. Нас интересует распределение результатов тестов, поэтому мы используем следующую описательную статистику:
1. Сводная статистика
Среднее значение: 82,13.Это говорит нам о том, что средний балл теста среди всех 1000 студентов составляет 82,13.
Медиана: 84. Это говорит нам о том, что половина всех учащихся набрала больше 84 баллов, а половина — меньше 84.
Максимум: 100. Минимум: 45. Это говорит нам о том, что максимальный балл, который получил любой учащийся, составлял 100, а минимальный балл был 45. Диапазон , который говорит нам о разнице между максимальным и минимальным значением, составляет 55.
2. Графики
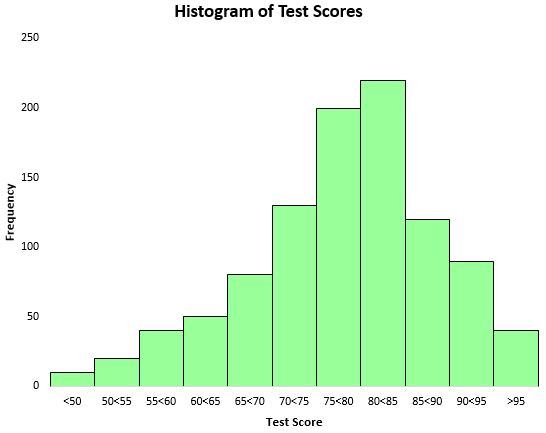
Чтобы визуализировать распределение результатов тестов, мы можем создать гистограмму — тип диаграммы, в которой для представления частот используются прямоугольные столбцы.
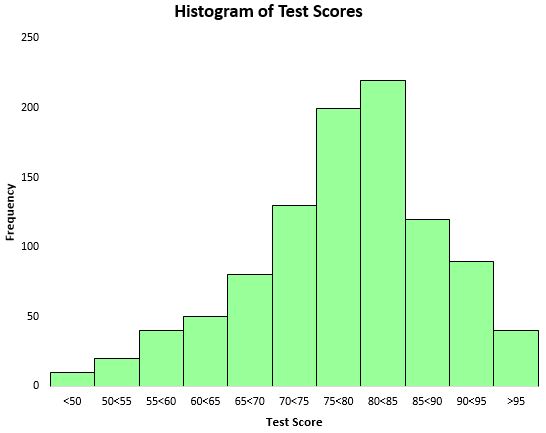
Основываясь на этой гистограмме, мы видим, что распределение результатов тестов имеет примерно колоколообразную форму. Большинство студентов набрали от 70 до 90 баллов, очень немногие набрали больше 95 баллов, а меньше 50 баллов.
3. Таблицы
Еще один простой способ получить представление о распределении баллов — составить таблицу частот. Например, в следующей таблице частот показано, какой процент учащихся набрал баллы между различными диапазонами:
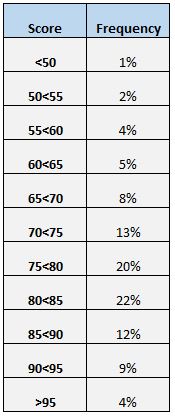
Мы видим, что только 4% всех студентов набрали больше 95 баллов. Мы также можем увидеть, что (12% + 9% + 4% = ) 25% всех студентов набрали 85 баллов или выше.
Таблица частот особенно полезна, если мы хотим знать, какой процент значений данных находится выше или ниже определенного значения. Например, предположим, что школа считает «приемлемой» тестовой оценкой любую оценку выше 75.
Глядя на таблицу частот, мы можем легко увидеть, что (20% + 22% + 12% + 9% + 4% =) 67% учащихся получили приемлемый результат теста.
Выведенный статистика
В двух словах, логическая статистика использует небольшую выборку данных, чтобы сделать выводы о большей совокупности, из которой была взята выборка.
Например, нам может быть интересно понять политические предпочтения миллионов людей в стране.
Однако на самом деле опрос каждого человека в стране занял бы слишком много времени и был бы слишком дорогим. Таким образом, вместо этого мы возьмем небольшой опрос, скажем, 1000 американцев, и используем результаты опроса, чтобы сделать выводы о населении в целом.
Это вся предпосылка статистики вывода — мы хотим ответить на какой-то вопрос о населении, поэтому мы получаем данные для небольшой выборки этой совокупности и используем данные из выборки, чтобы делать выводы о населении.
Важность репрезентативной выборки
Чтобы быть уверенными в нашей способности использовать выборку для получения выводов о совокупности, нам необходимо убедиться, что у нас есть репрезентативная выборка , то есть выборка, в которой характеристики индивидуумов в выборке точно соответствуют характеристикам. всего населения.
В идеале мы хотим, чтобы наша выборка была похожа на «мини-версию» нашей популяции. Таким образом, если мы хотим сделать выводы о совокупности учащихся, состоящей из 50% девочек и 50% мальчиков, наша выборка не будет репрезентативной, если она будет включать 90% мальчиков и только 10% девочек.
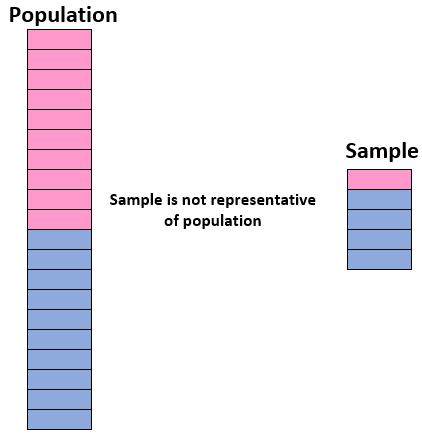
Если наша выборка не похожа на общую совокупность, то мы не можем с уверенностью обобщить результаты выборки на общую совокупность.
Как получить репрезентативный образец
Чтобы максимизировать шансы получить репрезентативную выборку, вам нужно сосредоточиться на двух вещах:
1. Убедитесь, что вы используете метод случайной выборки.
Существует несколько различных методов случайной выборки , которые можно использовать для получения репрезентативной выборки, в том числе:
- Простая случайная выборка
- Систематическая случайная выборка
- Кластерная случайная выборка
- Стратифицированная случайная выборка
Методы случайной выборки, как правило, дают репрезентативные выборки, поскольку каждый член совокупности имеет равные шансы быть включенным в выборку.
2. Убедитесь, что размер вашей выборки достаточно велик .
Наряду с использованием соответствующего метода выборки важно убедиться, что выборка достаточно велика, чтобы у вас было достаточно данных для обобщения на большую совокупность.
Чтобы определить, насколько большой должна быть ваша выборка, вы должны учитывать размер изучаемой вами популяции, уровень достоверности, который вы хотели бы использовать, и погрешность, которую вы считаете приемлемой.
К счастью, вы можете использовать онлайн-калькуляторы, чтобы подставить эти значения и посмотреть, насколько большой должна быть ваша выборка.
Общие формы логической статистики
Существует три распространенных формы логической статистики:
1. Проверка гипотез.
Часто нас интересуют ответы на такие вопросы о населении, как:
- Процент людей в Огайо, поддерживающих кандидата А, выше 50%?
- Равна ли средняя высота определенного растения 14 дюймам?
- Есть ли разница между средним ростом учеников школы А и школы Б?
Чтобы ответить на эти вопросы, мы можем выполнить тест гипотезы , который позволяет нам использовать данные из выборки, чтобы делать выводы о популяциях.
2. Доверительные интервалы .
Иногда мы заинтересованы в оценке некоторого значения для населения. Например, нас может интересовать средняя высота определенного вида растений в Австралии.
Вместо того, чтобы ходить и измерять каждое растение в стране, мы могли бы собрать небольшую выборку растений и измерить каждое из них. Затем мы можем использовать среднюю высоту растений в выборке для оценки средней высоты популяции.
Однако наша выборка вряд ли даст точную оценку населения. К счастью, мы можем учесть эту неопределенность, создавдоверительный интервал , который обеспечивает диапазон значений, в которые, как мы уверены, попадает истинный параметр совокупности.
Например, мы можем получить 95% доверительный интервал [13,2, 14,8], который говорит о том, что мы на 95% уверены, что истинная средняя высота этого вида растений составляет от 13,2 до 14,8 дюймов.
3. Регрессия .
Иногда нам интересно понять взаимосвязь между двумя переменными в популяции.
Например, предположим, что мы хотим знать, связаны ли часы, потраченные на учебу в неделю , с результатами тестов.Чтобы ответить на этот вопрос, мы могли бы применить технику, известную как регрессионный анализ .
Таким образом, мы можем наблюдать за количеством часов обучения вместе с результатами тестов для 100 студентов и выполнять регрессионный анализ, чтобы увидеть, существует ли значительная связь между двумя переменными.
Если p-значение регрессии окажется значимым , то можно сделать вывод о наличии значимой связи между этими двумя переменными в общей совокупности студентов.
Разница между описательной и логической статистикой
Таким образом, разницу между описательной и логической статистикой можно описать следующим образом:
Описательная статистика использует сводную статистику, графики и таблицы для описания набора данных.
Это полезно для того, чтобы помочь нам быстро и легко понять набор данных, не перебирая все отдельные значения данных.
Логическая статистика использует выборки, чтобы делать выводы о больших группах населения.
В зависимости от вопроса, на который вы хотите ответить о совокупности, вы можете решить использовать один или несколько из следующих методов: проверки гипотез, доверительные интервалы и регрессионный анализ.
Если вы решите использовать один из этих методов, имейте в виду, что ваша выборка должна быть репрезентативной для вашей популяции , иначе выводы, которые вы сделаете, будут ненадежными.