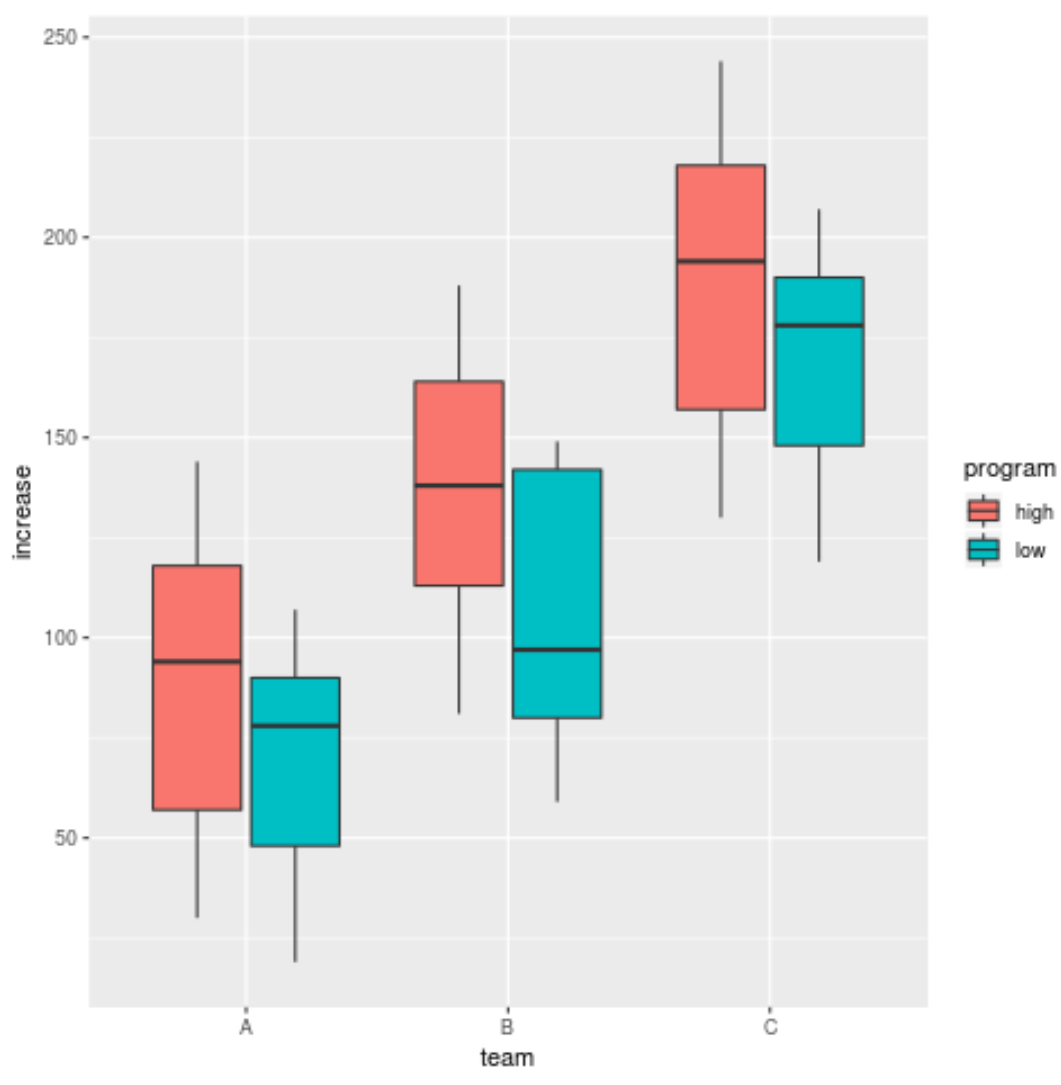
Блочные диаграммы полезны для визуализации пятизначной сводки набора данных, которая включает в себя:
- Минимум
- Первый квартиль
- медиана
- Третий квартиль
- Максимум
Связанный: Нежное введение в Boxplots
К счастью, в R легко создавать диаграммы с помощью библиотеки визуализации ggplot2 .
Это также для создания коробчатых диаграмм, сгруппированных по определенной переменной в наборе данных. Например, предположим, что у нас есть следующий набор данных, отображающий повышение эффективности 150 баскетболистов из трех разных команд на основе двух разных программ тренировок:
#define variables
team=rep(c('A', 'B', 'C'), each =50)
program=rep(c('low', 'high'), each =25)
increase=seq(1:150)+sample(1:100, 100, replace= TRUE )
#create dataset using variables
data=data.frame(team, program, increase)
#view first six rows of dataset
head(data)
team program increase
1 A low 62
2 A low 37
3 A low 49
4 A low 60
5 A low 64
6 A low 105
Мы можем использовать следующий код для создания диаграмм, отображающих повышение эффективности игроков, сгруппированных по командам и заполненных на основе тренировочной программы:
library (ggplot2)
ggplot(data, aes(x=team, y=increase, fill=program)) +
geom_boxplot()
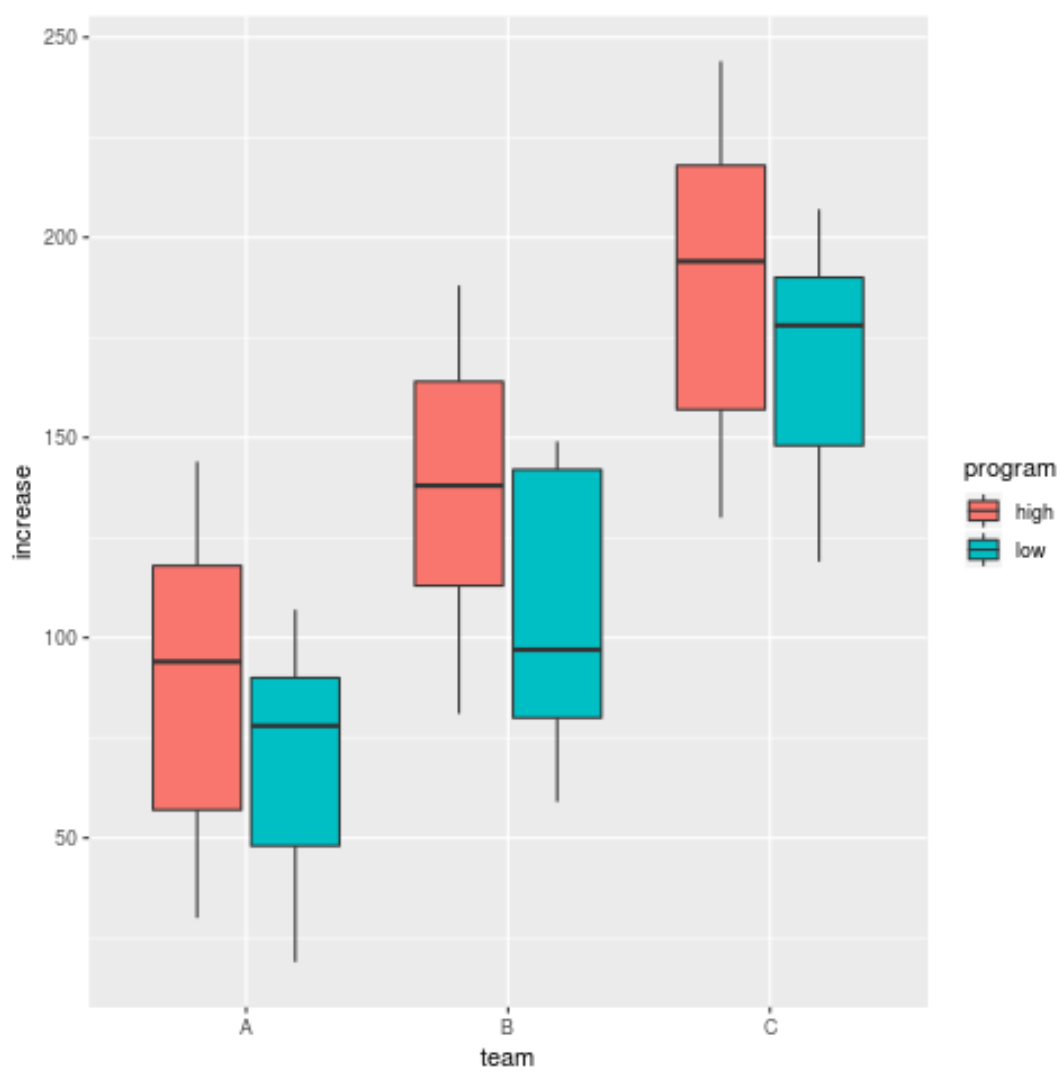
Мы можем использовать аналогичный синтаксис для создания диаграмм, отображающих повышение эффективности игроков, сгруппированных по программе тренировок и заполненных в зависимости от команды:
library (ggplot2)
ggplot(data, aes(x=program, y=increase, fill=team)) +
geom_boxplot()
Аналогичной альтернативой является использование фасетирования , при котором каждая подгруппа отображается на отдельной панели:
library (ggplot2)
ggplot(data, aes(x=team, y=increase, fill=program)) +
geom_boxplot() +
facet_wrap (~program)
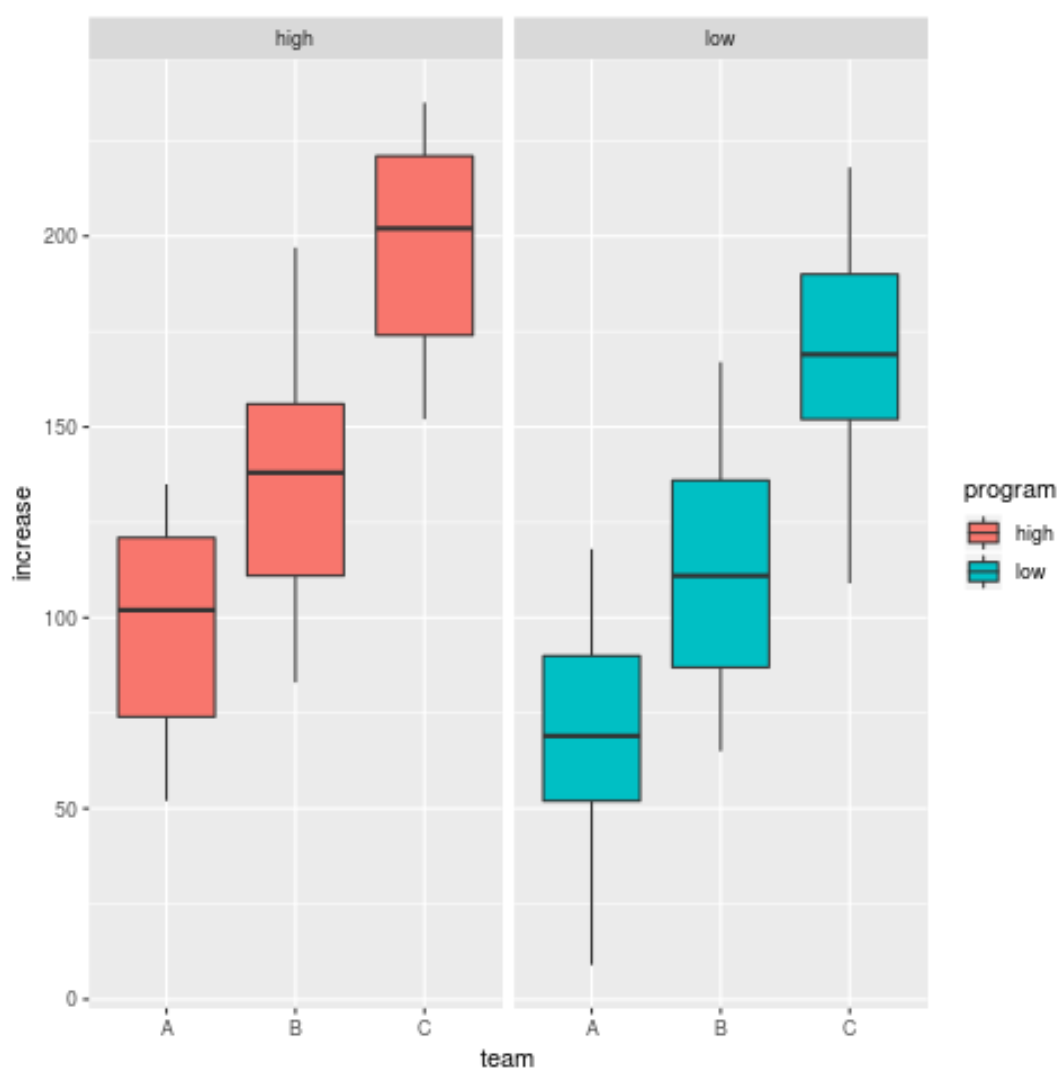
В зависимости от данных, с которыми вы работаете, фасетирование может иметь или не иметь смысла для ваших потребностей в визуализации.
Дополнительные ресурсы
Как удалить выбросы в ящичных диаграммах в R
Как создавать параллельные графики в ggplot2
Полное руководство по лучшим темам ggplot2