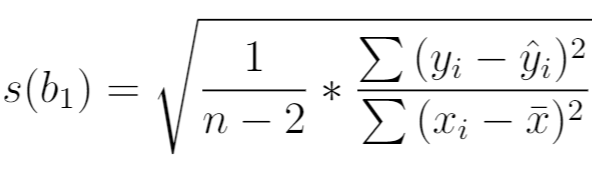
Стандартная ошибка наклона регрессии — это способ измерения «неопределенности» в оценке наклона регрессии.
Он рассчитывается как:
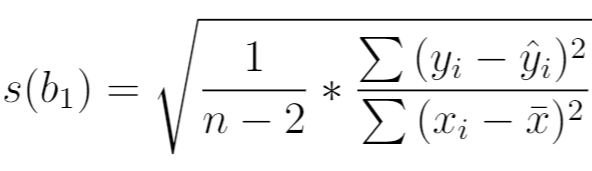
куда:
- n : общий размер выборки
- y i : фактическое значение переменной ответа
- ŷ i : прогнозируемое значение переменной ответа
- x i : фактическое значение переменной-предиктора
- x̄ : среднее значение переменной-предиктора
Чем меньше стандартная ошибка, тем ниже изменчивость оценки коэффициента наклона регрессии.
Стандартная ошибка наклона регрессии будет отображаться в столбце «стандартная ошибка» в выводе регрессии большинства статистических программ:

В следующих примерах показано, как интерпретировать стандартную ошибку наклона регрессии в двух разных сценариях.
Пример 1. Интерпретация малой стандартной ошибки наклона регрессии
Предположим, профессор хочет понять взаимосвязь между количеством часов обучения и итоговой оценкой на экзамене, полученной студентами в его классе.
Он собирает данные по 25 ученикам и создает следующую диаграмму рассеяния:

Существует четкая положительная связь между двумя переменными. По мере увеличения часов обучения экзаменационный балл увеличивается с довольно предсказуемой скоростью.
Затем он подбирает простую модель линейной регрессии, используя часы обучения в качестве переменной-предиктора и итоговый балл экзамена в качестве переменной-ответа.
В следующей таблице показаны результаты регрессии:

Коэффициент для предикторной переменной «изучаемые часы» равен 5,487. Это говорит нам о том, что каждый дополнительный час обучения связан со средним увеличением экзаменационного балла на 5,487 .
Стандартная ошибка составляет 0,419 , что является мерой изменчивости этой оценки наклона регрессии.
Мы можем использовать это значение для расчета t-статистики для предикторной переменной «изучаемые часы»:
- t-статистика = оценка коэффициента / стандартная ошибка
- t-статистика = 5,487 / 0,419
- t-статистика = 13,112
Значение p, соответствующее этой тестовой статистике, равно 0,000, что указывает на то, что «отработанные часы» имеют статистически значимую связь с итоговой оценкой экзамена.
Поскольку стандартная ошибка наклона регрессии была небольшой по сравнению с оценкой коэффициента наклона регрессии, переменная-предиктор была статистически значимой.
Пример 2. Интерпретация большой стандартной ошибки наклона регрессии
Предположим, другой профессор хочет понять взаимосвязь между количеством часов обучения и итоговой оценкой на экзамене, полученной студентами в ее классе.
Она собирает данные по 25 ученикам и создает следующую диаграмму рассеяния:

По-видимому, существует небольшая положительная связь между двумя переменными. По мере увеличения часов обучения экзаменационная оценка обычно увеличивается, но не с предсказуемой скоростью.
Предположим, что затем профессор подбирает простую модель линейной регрессии, используя часы обучения в качестве переменной-предиктора и итоговый балл экзамена в качестве переменной-ответа.
В следующей таблице показаны результаты регрессии:

Коэффициент для предикторной переменной «изучаемые часы» равен 1,7919. Это говорит нам о том, что каждый дополнительный час обучения связан со средним увеличением экзаменационного балла на 1,7919 .
Стандартная ошибка составляет 1,0675 , что является мерой изменчивости этой оценки наклона регрессии.
Мы можем использовать это значение для расчета t-статистики для предикторной переменной «изучаемые часы»:
- t-статистика = оценка коэффициента / стандартная ошибка
- t-статистика = 1,7919/1,0675
- t-статистика = 1,678
Значение p, соответствующее этой тестовой статистике, равно 0,107. Поскольку это p-значение не меньше 0,05, это указывает на то, что «учебные часы» не имеют статистически значимой связи с итоговой оценкой экзамена.
Поскольку стандартная ошибка наклона регрессии была большой по сравнению с оценкой коэффициента наклона регрессии, предикторная переменная не была статистически значимой.
Дополнительные ресурсы
Введение в простую линейную регрессию
Введение в множественную линейную регрессию
Как читать и интерпретировать таблицу регрессии