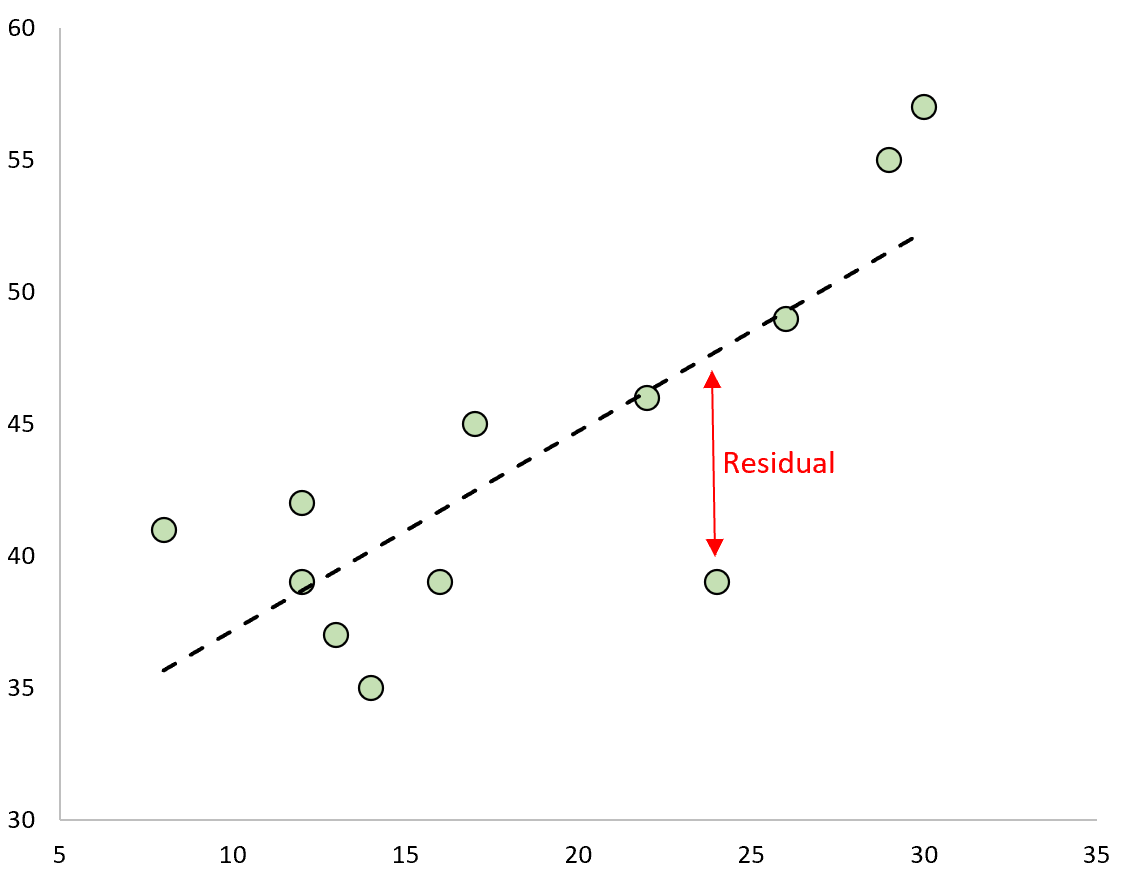
Остаток — это разница между наблюдаемым значением и прогнозируемым значением в регрессионной модели .
Он рассчитывается как:
Остаток = наблюдаемое значение – прогнозируемое значение
Если мы нанесем наблюдаемые значения и наложим подобранную линию регрессии, остатки для каждого наблюдения будут вертикальным расстоянием между наблюдением и линией регрессии:
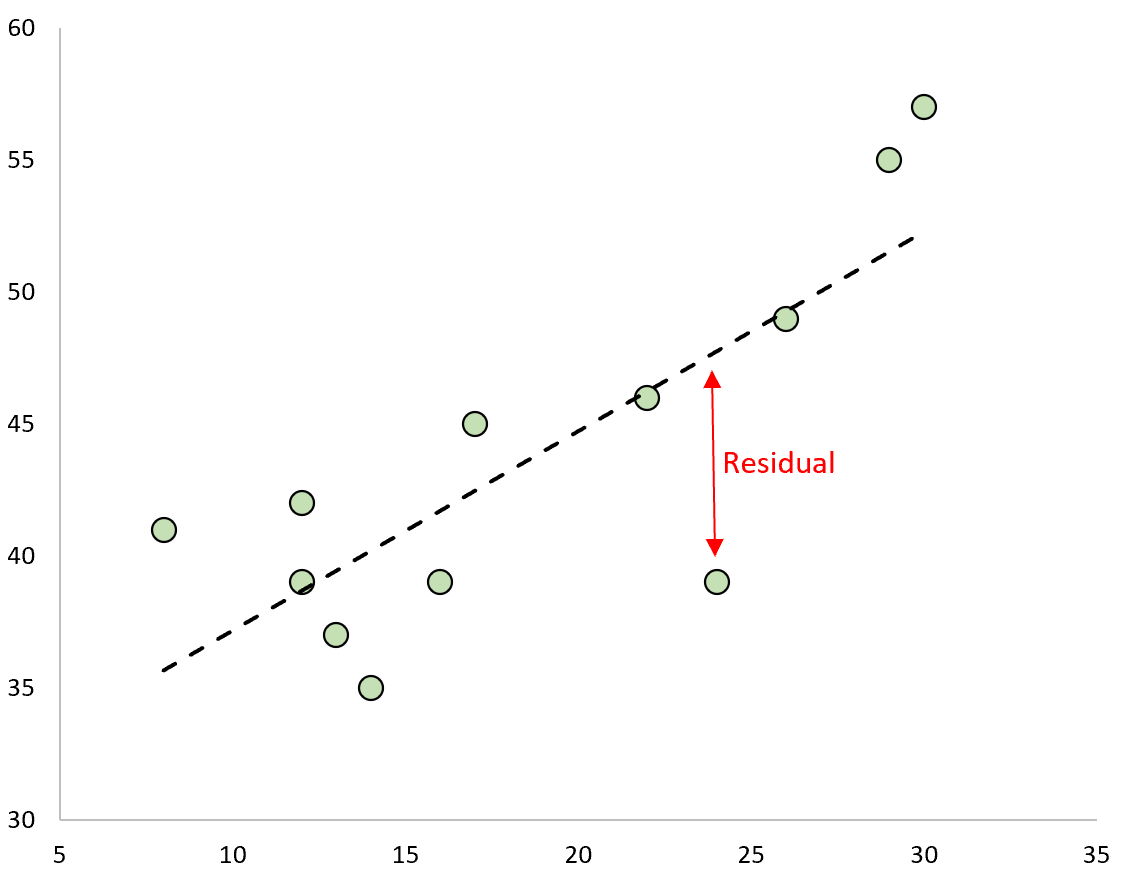
Один тип остатка, который мы часто используем для выявления выбросов в регрессионной модели, известен как стандартизированный остаток .
Он рассчитывается как:
r i = e i / s(e i ) = e i / RSE√ 1-h ii
куда:
- e i : i -й остаток
- RSE: остаточная стандартная ошибка модели.
- h ii : рычаг i -го наблюдения
На практике мы часто считаем выбросом любой стандартизированный остаток с абсолютным значением больше 3.
Это не обязательно означает, что мы удалим эти наблюдения из модели, но мы должны, по крайней мере, исследовать их дальше, чтобы убедиться, что они не являются результатом ошибки ввода данных или какого-либо другого странного события.
Примечание. Иногда стандартизированные остатки также называют «внутренними студенческими остатками».
Пример. Как рассчитать стандартизованные остатки
Предположим, у нас есть следующий набор данных с 12 общими наблюдениями:
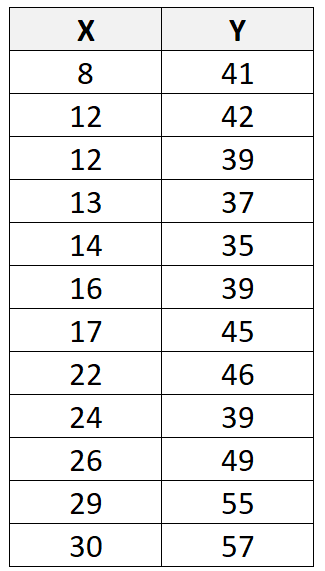
Если мы используем какое-либо статистическое программное обеспечение (например, R , Excel , Python , Stata и т. д.), чтобы подогнать линию линейной регрессии к этому набору данных, мы обнаружим, что линия наилучшего соответствия оказывается:
у = 29,63 + 0,7553х
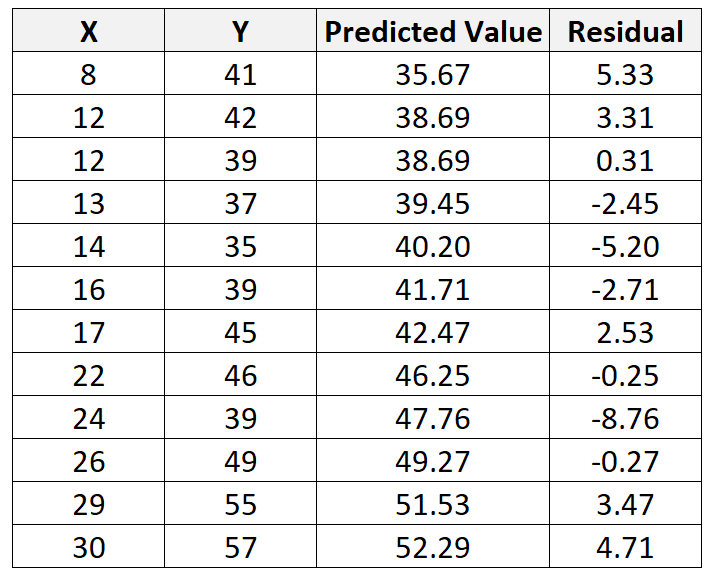
Используя эту строку, мы можем вычислить прогнозируемое значение для каждого значения Y на основе значения X. Например, прогнозируемое значение первого наблюдения будет следующим:
у = 29,63 + 0,7553 * (8) = 35,67
Затем мы можем рассчитать остаток для этого наблюдения как:
Остаток = наблюдаемое значение – прогнозируемое значение = 41 – 35,67 = 5,33
Мы можем повторить этот процесс, чтобы найти невязку для каждого отдельного наблюдения:
Мы также можем использовать статистическое программное обеспечение, чтобы найти, что остаточная стандартная ошибка модели составляет 4,44 .
И, хотя это выходит за рамки этого руководства, мы можем использовать программное обеспечение, чтобы найти статистику кредитного плеча (h ii ) для каждого наблюдения:
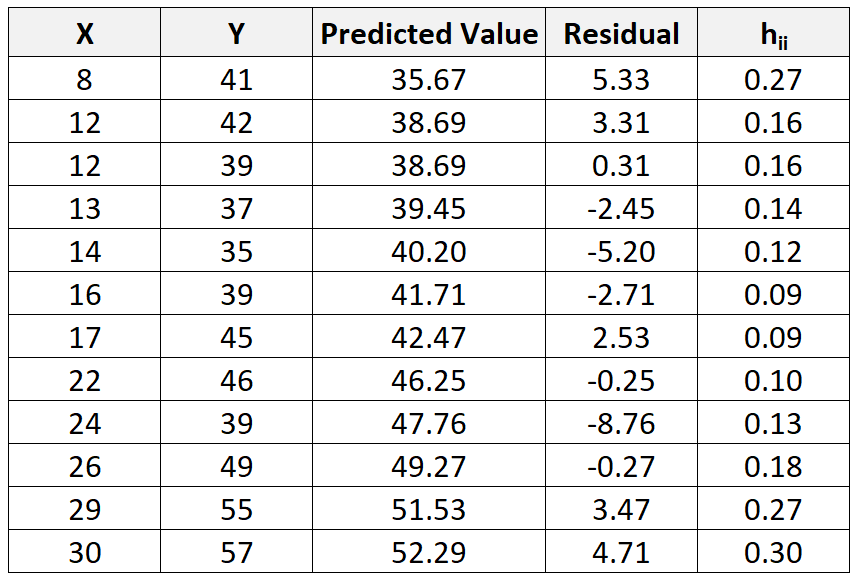
Затем мы можем использовать следующую формулу для расчета стандартизованного остатка для каждого наблюдения:
r i = e i / RSE √ 1-h ii
Например, стандартизированный остаток для первого наблюдения рассчитывается как:
г я = 5,33 / 4,44 √ 1-0,27 = 1,404
Мы можем повторить этот процесс, чтобы найти стандартизованную невязку для каждого наблюдения:
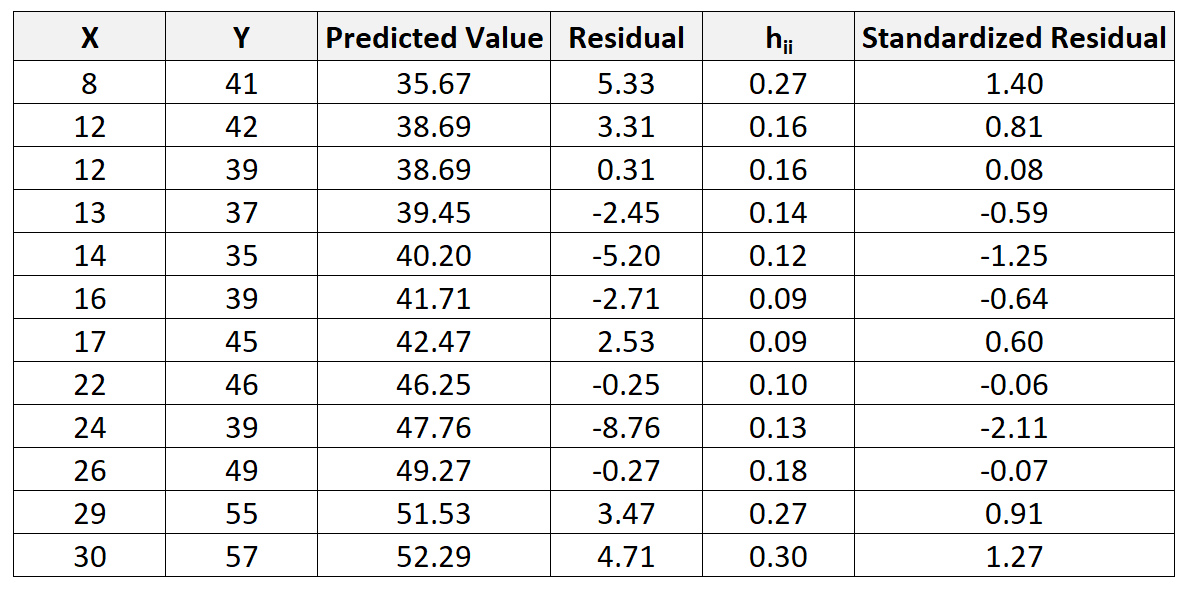
Затем мы можем создать быструю диаграмму рассеяния значений предиктора по сравнению со стандартизованными остатками, чтобы визуально увидеть, превышает ли какой-либо из стандартизованных остатков порог абсолютного значения, равный 3:
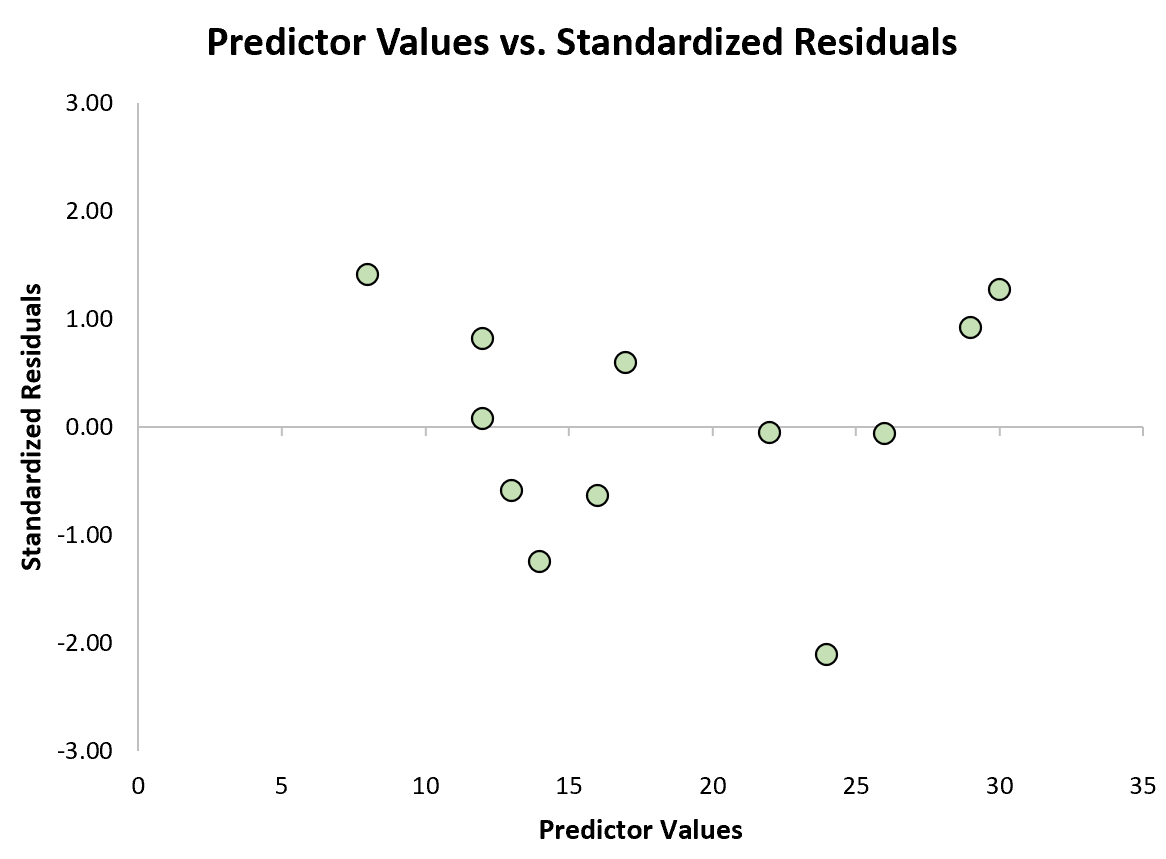
Из графика видно, что ни один из стандартизованных остатков не превышает абсолютного значения 3. Таким образом, ни одно из наблюдений не является выбросом.
Стоит отметить, что в некоторых случаях исследователи считают наблюдения со стандартизованными остатками, превышающими абсолютное значение 2, выбросами.
Вам решать, в зависимости от области, в которой вы работаете, и конкретной проблемы, над которой вы работаете, использовать ли абсолютное значение 2 или 3 в качестве порога для выбросов.
Дополнительные ресурсы
Что такое остатки в статистике?
Как рассчитать стандартизированные остатки в Excel
Как рассчитать стандартизованные остатки в R
Как рассчитать стандартизованные остатки в Python