Односторонний дисперсионный анализ используется для определения того, равны ли средние значения трех или более независимых групп.
Однофакторный дисперсионный анализ использует следующие нулевую и альтернативную гипотезы:
- H 0 : Все средние группы равны.
- H A : По крайней мере одно среднее значение группы отличается от остальных.
Всякий раз, когда вы выполняете односторонний ANOVA, вы получите сводную таблицу, которая выглядит следующим образом:
| Источник | Сумма квадратов (СС) | дф | Средние квадраты (MS) | Ф | P-значение | | --- | --- | --- | --- | --- | --- | | Уход | 192,2 | 2 | 96,1 | 2,358 | 0,1138 | | Ошибка | 1100,6 | 27 | 40,8 | | | | Общий | 1292,8 | 29 | | | |
Значение F в таблице рассчитывается как:
- F-значение = Обработка средних квадратов / Ошибка средних квадратов
Другой способ написать это выглядит следующим образом:
- F-значение = вариация между средними значениями выборки / вариация внутри выборок
Если вариация между выборочными средними высока по сравнению с вариацией внутри каждой из выборок, то F-значение будет большим.
Например, значение F в приведенной выше таблице рассчитывается как:
- F-значение = 96,1 / 40,8 = 2,358
Чтобы найти p-значение , соответствующее этому F-значению, мы можем использовать калькулятор F-распределения со степенями свободы в числителе = df Treatment и степенями свободы в знаменателе = df Error.
Например, p-значение, соответствующее F-значению 2,358, числителю df = 2 и знаменателю df = 27, равно 0,1138 .
Поскольку это p-значение не меньше α = 0,05, мы не можем отвергнуть нулевую гипотезу. Это означает, что нет статистически значимой разницы между средними значениями трех групп.
Визуализация F-значения дисперсионного анализа
Чтобы получить интуитивное представление о F-значении в таблице ANOVA, рассмотрим следующий пример.
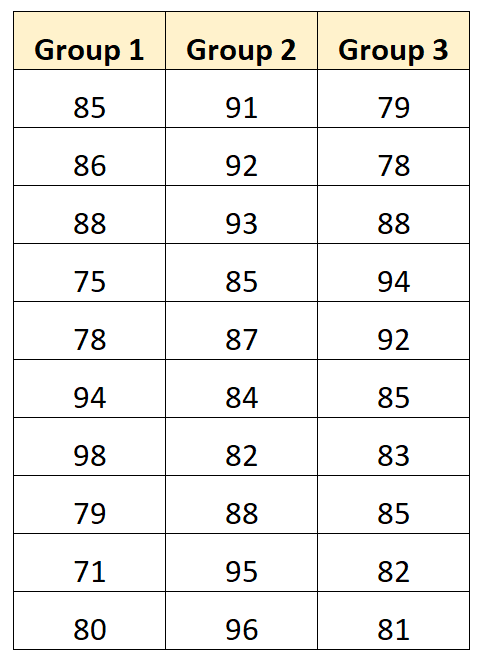
Предположим, мы хотим выполнить однофакторный дисперсионный анализ, чтобы определить, дают ли три разных метода обучения разные средние баллы на экзаменах. В следующей таблице показаны экзаменационные баллы 10 студентов, использовавших каждый метод:
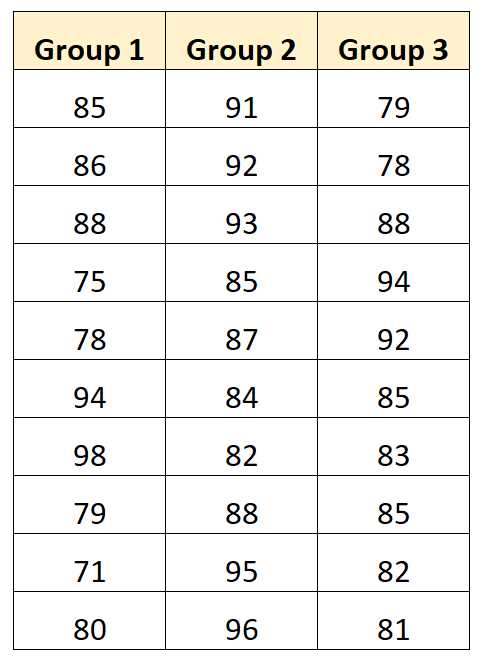
Мы можем создать следующий график, чтобы визуализировать результаты экзаменов по группам:
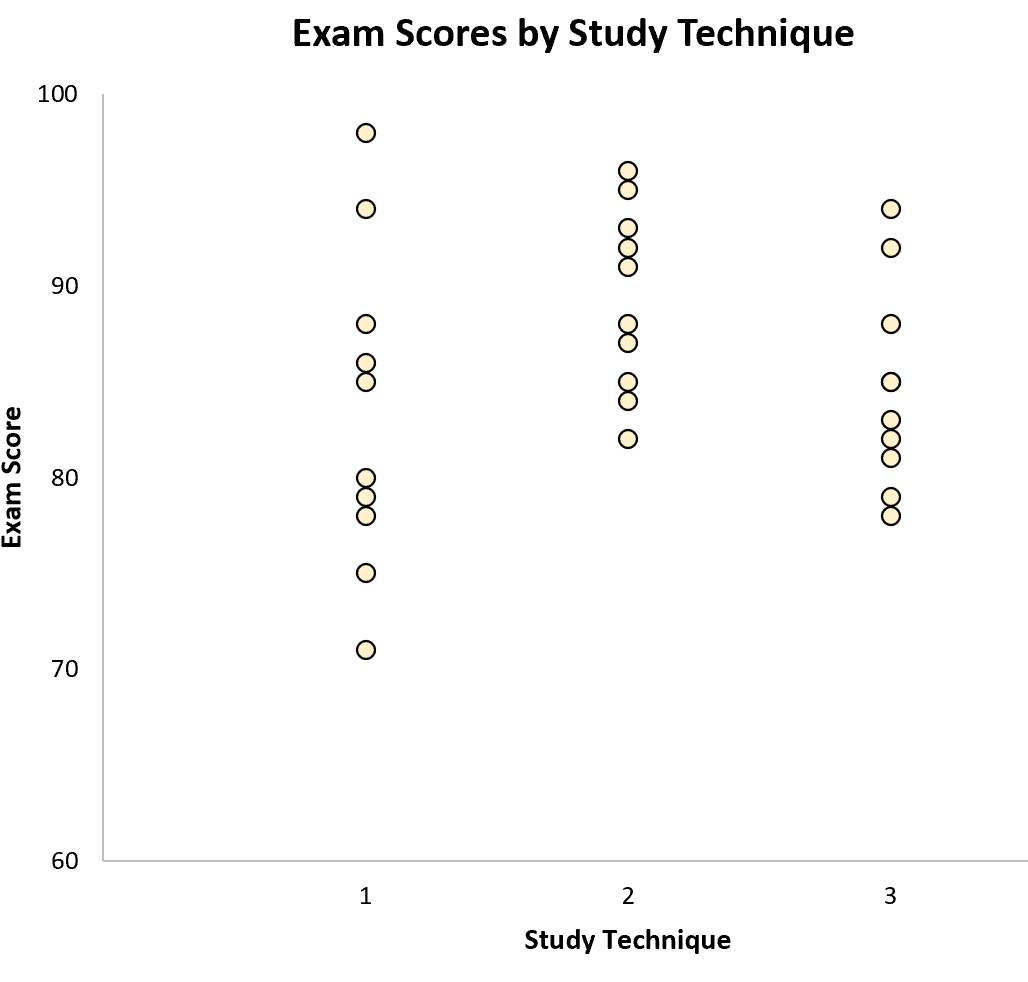
Вариация внутри выборки представлена разбросом значений в каждой отдельной выборке:
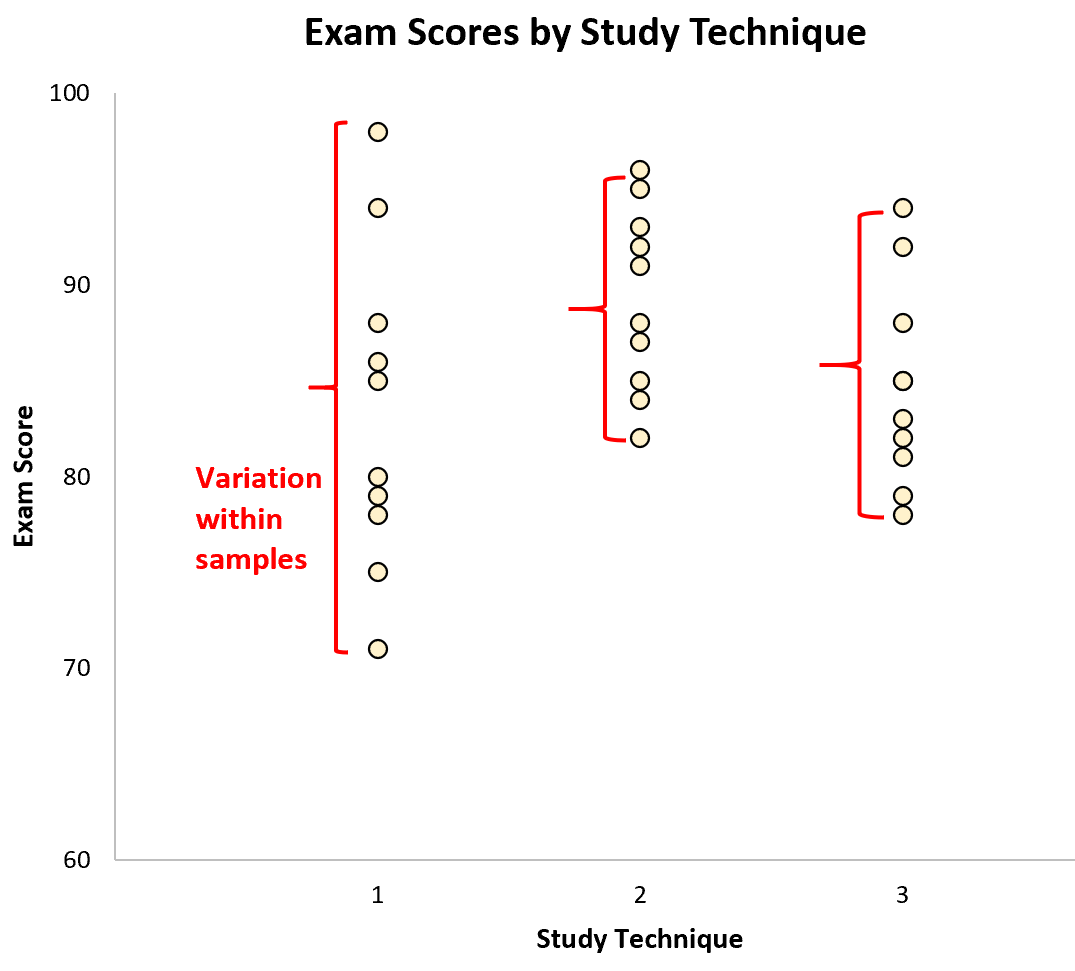
Различия между выборками представлены различиями между выборочными средними:
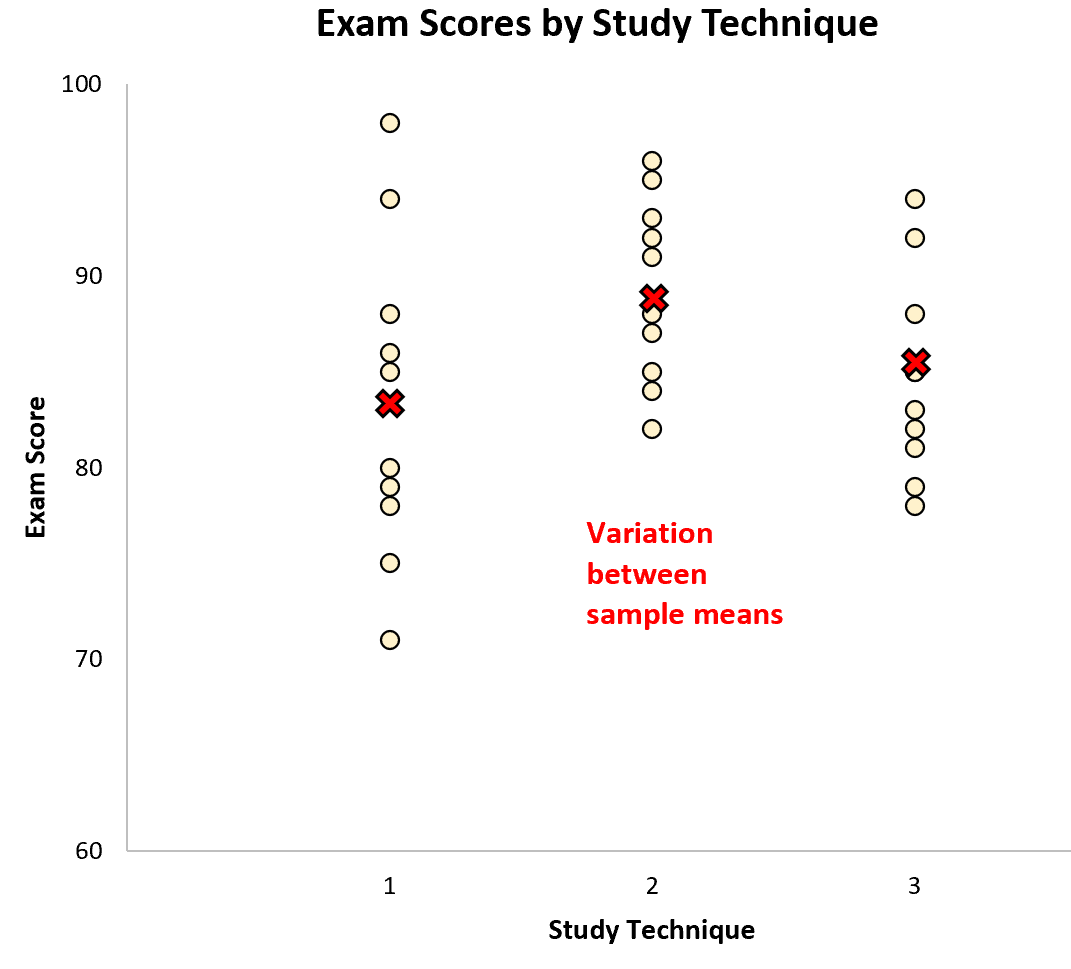
Выполнив однофакторный дисперсионный анализ для этого набора данных, мы обнаруживаем, что значение F равно 2,358 , а соответствующее значение p равно 0,1138 .
Поскольку это p-значение не меньше 0,05, мы не можем отвергнуть нулевую гипотезу. Это означает, что у нас нет достаточных доказательств того, что используемая методика обучения вызывает статистически значимые различия в средних результатах экзаменов.
Другими словами, это говорит нам о том, что вариация между выборочными средними недостаточно высока по сравнению с вариацией внутри выборок, чтобы отвергнуть нулевую гипотезу.
Вывод
Вот краткое изложение основных моментов в этой статье:
- Значение F в дисперсионном анализе рассчитывается как: вариация между средними значениями выборки / вариация внутри выборок.
- Чем выше значение F в дисперсионном анализе, тем выше вариация между выборочными средними по сравнению с вариациями внутри выборок.
- Чем выше значение F, тем ниже соответствующее значение p.
- Если p-значение ниже определенного порога (например, α = 0,05), мы можем отклонить нулевую гипотезу дисперсионного анализа и сделать вывод о наличии статистически значимой разницы между средними группами.
Дополнительные ресурсы
Как выполнить однофакторный дисперсионный анализ в Excel
Как выполнить однофакторный дисперсионный анализ вручную
Калькулятор однофакторного дисперсионного анализа