Дерево решений — это тип модели машинного обучения, который используется, когда связь между набором переменных-предикторов и переменной отклика нелинейна.
Основная идея дерева решений состоит в том, чтобы построить «дерево» с использованием набора переменных-предикторов, которые предсказывают значение некоторой переменной ответа с использованием правил принятия решений.
Например, мы можем использовать предикторные переменные «количество лет игры» и «среднее количество хоум-ранов», чтобы предсказать годовую зарплату профессиональных бейсболистов.
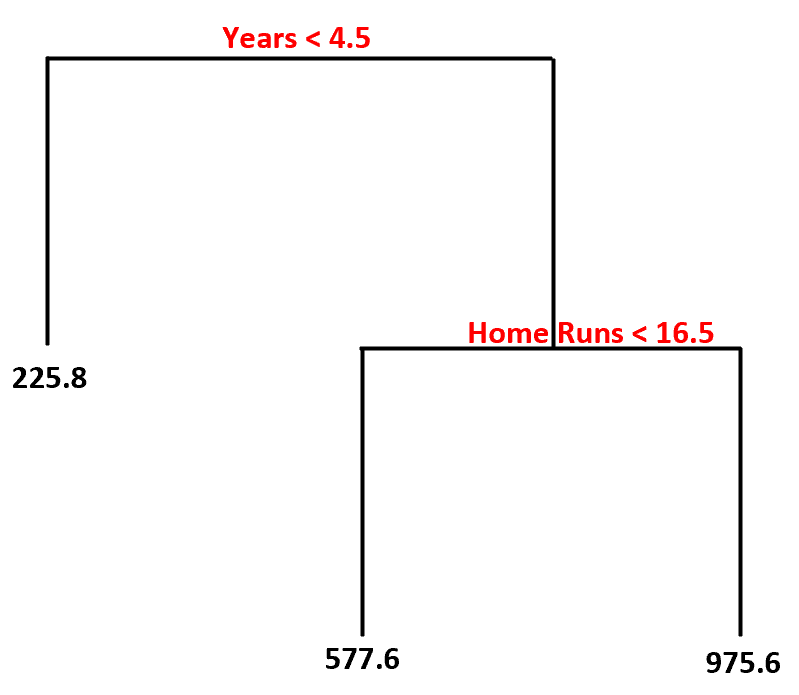
Используя этот набор данных, вот как может выглядеть модель дерева решений:

Вот как мы интерпретируем это дерево решений:
- Прогнозируемая зарплата игроков, игравших менее 4,5 лет, составляет 225,8 тысяч долларов .
- Прогнозируемая зарплата игроков со стажем игры более или равным 4,5 года и средним показателем хоумранов менее 16,5 имеет прогнозируемую зарплату в размере 577,6 тыс.долларов.
- Прогнозируемая зарплата игроков со стажем игры не менее 4,5 лет и средним показателем хоумранов не менее 16,5 имеет прогнозируемую зарплату в размере 975,6 тыс.долларов.
Основное преимущество дерева решений заключается в том, что его можно быстро подогнать к набору данных, а окончательную модель можно аккуратно визуализировать и интерпретировать с помощью «древовидной» диаграммы, подобной приведенной выше.
Основным недостатком является то, что дерево решений склонно к переоснащению обучающего набора данных, а это означает, что оно может плохо работать с невидимыми данными. На него также могут сильно влиять выбросы в наборе данных.
Расширением дерева решений является модель, известная как случайный лес , которая по сути представляет собой набор деревьев решений.
Вот шаги, которые мы используем для построения модели случайного леса:
1. Возьмите загрузочные образцы из исходного набора данных.
2. Для каждой выборки с начальной загрузкой постройте дерево решений, используя случайное подмножество переменных-предикторов.
3. Усредните прогнозы каждого дерева, чтобы получить окончательную модель.
Преимущество случайных лесов заключается в том, что они, как правило, работают намного лучше, чем деревья решений, на невидимых данных и менее подвержены выбросам.
Недостатком случайных лесов является то, что нет возможности визуализировать окончательную модель, и их создание может занять много времени, если у вас недостаточно вычислительной мощности или если набор данных, с которым вы работаете, чрезвычайно велик.
Плюсы и минусы: деревья решений против случайных лесов
В следующей таблице приведены плюсы и минусы деревьев решений по сравнению со случайными лесами:
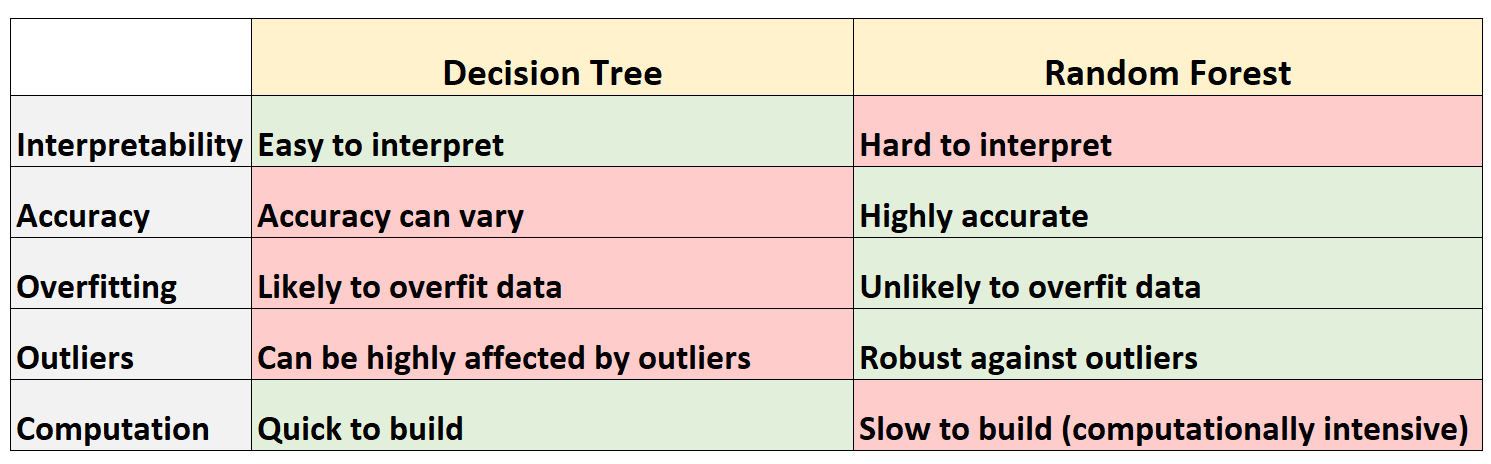
Вот краткое объяснение каждой строки в таблице:
1. Интерпретируемость
Деревья решений легко интерпретировать, потому что мы можем создать древовидную диаграмму, чтобы визуализировать и понять окончательную модель.
И наоборот, мы не можем визуализировать случайный лес, и часто бывает трудно понять, как окончательная модель случайного леса принимает решения.
2. Точность
Поскольку деревья решений, скорее всего, будут соответствовать обучающему набору данных, они, как правило, работают хуже, чем на невидимых наборах данных.
И наоборот, случайные леса, как правило, очень точны для невидимых наборов данных, поскольку они избегают переобучения обучающих наборов данных.
3. Переобучение
Как упоминалось ранее, деревья решений часто превосходят обучающие данные — это означает, что они, скорее всего, соответствуют «шуму» в наборе данных, а не истинному базовому шаблону.
И наоборот, поскольку случайные леса используют только некоторые переменные-предикторы для построения каждого отдельного дерева решений, окончательные деревья, как правило, декоррелированы, что означает, что модели случайного леса вряд ли будут соответствовать наборам данных.
4. Выбросы
Деревья решений очень подвержены влиянию выбросов.
И наоборот, поскольку модель случайного леса строит множество отдельных деревьев решений, а затем берет среднее значение предсказаний этих деревьев, гораздо меньше вероятность того, что на нее повлияют выбросы.
5. Расчет
Деревья решений можно быстро адаптировать к наборам данных.
И наоборот, случайные леса требуют гораздо больше вычислительных ресурсов, и их создание может занять много времени в зависимости от размера набора данных.
Когда использовать деревья решений против случайных лесов
Как правило большого пальца:
Вам следует использовать дерево решений, если вы хотите быстро построить нелинейную модель и хотите иметь возможность легко интерпретировать, как модель принимает решения.
Тем не менее, вам следует использовать случайный лес , если у вас достаточно вычислительных способностей и вы хотите построить модель, которая, вероятно, будет очень точной, не беспокоясь о том, как ее интерпретировать.
В реальном мире инженеры по машинному обучению и специалисты по данным часто используют случайные леса, потому что они очень точны, а современные компьютеры и системы часто могут обрабатывать большие наборы данных, которые раньше не могли обрабатываться.
Дополнительные ресурсы
Следующие руководства содержат введение как в деревья решений, так и в модели случайного леса:
В следующих руководствах объясняется, как подогнать деревья решений и случайные леса в R: