Надежная регрессия — это метод, который мы можем использовать в качестве альтернативы обычной регрессии методом наименьших квадратов, когда в наборе данных, с которым мы работаем, есть выбросы или важные наблюдения .
Чтобы выполнить надежную регрессию в R, мы можем использовать функцию rlm() из пакета MASS , которая использует следующий синтаксис:
В следующем пошаговом примере показано, как выполнить надежную регрессию в R для заданного набора данных.
Шаг 1: Создайте данные
Во-первых, давайте создадим поддельный набор данных для работы:
#create data
df <- data.frame(x1=c(1, 3, 3, 4, 4, 6, 6, 8, 9, 3,
11, 16, 16, 18, 19, 20, 23, 23, 24, 25),
x2=c(7, 7, 4, 29, 13, 34, 17, 19, 20, 12,
25, 26, 26, 26, 27, 29, 30, 31, 31, 32),
y=c(17, 170, 19, 194, 24, 2, 25, 29, 30, 32,
44, 60, 61, 63, 63, 64, 61, 67, 59, 70))
#view first six rows of data
head(df)
x1 x2 y
1 1 7 17
2 3 7 170
3 3 4 19
4 4 29 194
5 4 13 24
6 6 34 2
Шаг 2: Выполните обычную регрессию методом наименьших квадратов
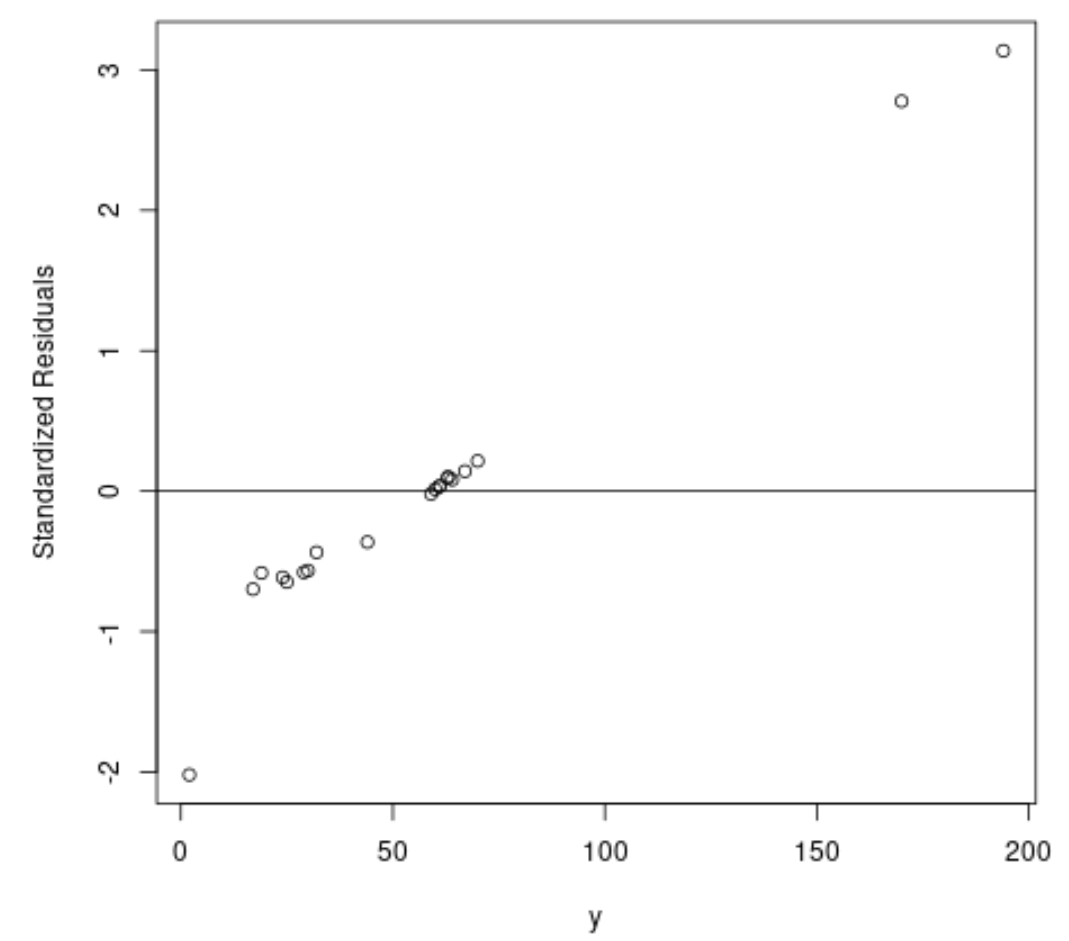
Далее давайте подгоним обычную модель регрессии методом наименьших квадратов и создадим график стандартизированных остатков .
На практике мы часто считаем выбросом любой стандартизированный остаток с абсолютным значением больше 3.
#fit ordinary least squares regression model
ols <- lm(y~x1+x2, data=df)
#create plot of y-values vs. standardized residuals
plot(df$y, rstandard(ols), ylab='Standardized Residuals', xlab='y')
abline(h= 0 )

Из графика видно, что есть два наблюдения со стандартизованными остатками около 3.
Это указывает на то, что в наборе данных есть два потенциальных выброса, и поэтому вместо этого мы можем извлечь выгоду из выполнения надежной регрессии.
Шаг 3: Выполните надежную регрессию
Далее давайте воспользуемся функцией rlm() , чтобы подогнать надежную модель регрессии:
library (MASS)
#fit robust regression model
robust <- rlm(y~x1+x2, data=df)
Чтобы определить, обеспечивает ли эта надежная регрессионная модель лучшее соответствие данным по сравнению с моделью OLS, мы можем рассчитать остаточную стандартную ошибку каждой модели.
Остаточная стандартная ошибка (RSE) — это способ измерения стандартного отклонения остатков в регрессионной модели. Чем ниже значение RSE, тем точнее модель может соответствовать данным.
В следующем коде показано, как рассчитать RSE для каждой модели:
#find residual standard error of ols model
summary(ols)$sigma
[1] 49.41848
#find residual standard error of ols model
summary(robust)$sigma
[1] 9.369349
Мы видим, что RSE для робастной регрессионной модели намного ниже, чем для обычной регрессионной модели наименьших квадратов, что говорит нам о том, что робастная регрессионная модель предлагает лучшее соответствие данным.
Дополнительные ресурсы
Как выполнить простую линейную регрессию в R
Как выполнить множественную линейную регрессию в R
Как выполнить полиномиальную регрессию в R