Термин одномерный анализ относится к анализу одной переменной. Вы можете запомнить это, потому что приставка «уни» означает «один».
Существует три распространенных способа выполнения одномерного анализа одной переменной:
1. Сводная статистика – измеряет центр и разброс значений.
2. Таблица частот – описывает, как часто встречаются разные значения.
3. Диаграммы — используются для визуализации распределения значений.
В этом руководстве представлен пример выполнения одномерного анализа со следующим кадром данных pandas:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'points': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2],
'assists': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6],
'rebounds': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]})
#view first five rows of DataFrame
df.head ()
points assists rebounds
0 1.0 5 11
1 1.0 7 8
2 2.0 7 10
3 3.5 9 6
4 4.0 12 6
1. Рассчитать сводную статистику
Мы можем использовать следующий синтаксис для вычисления различных сводных статистических данных для переменной 'points' в DataFrame:
#calculate mean of 'points'
df['points'].mean()
5.706666666666667
#calculate median of 'points'
df['points']. median ()
5.0
#calculate standard deviation of 'points'
df['points']. std()
3.858287308169384
2. Создайте таблицу частот
Мы можем использовать следующий синтаксис для создания таблицы частот для переменной «точки»:
#create frequency table for 'points'
df['points']. value_counts ()
4.0 3
1.0 2
5.0 2
2.0 1
3.5 1
6.5 1
7.0 1
7.4 1
8.0 1
13.0 1
14.2 1
Name: points, dtype: int64
Это говорит нам о том, что:
- Значение 4 встречается 3 раза
- Значение 1 встречается 2 раза
- Значение 5 встречается 2 раза
- Значение 2 встречается 1 раз
И так далее.
Связанный: Как создать частотные таблицы в Python
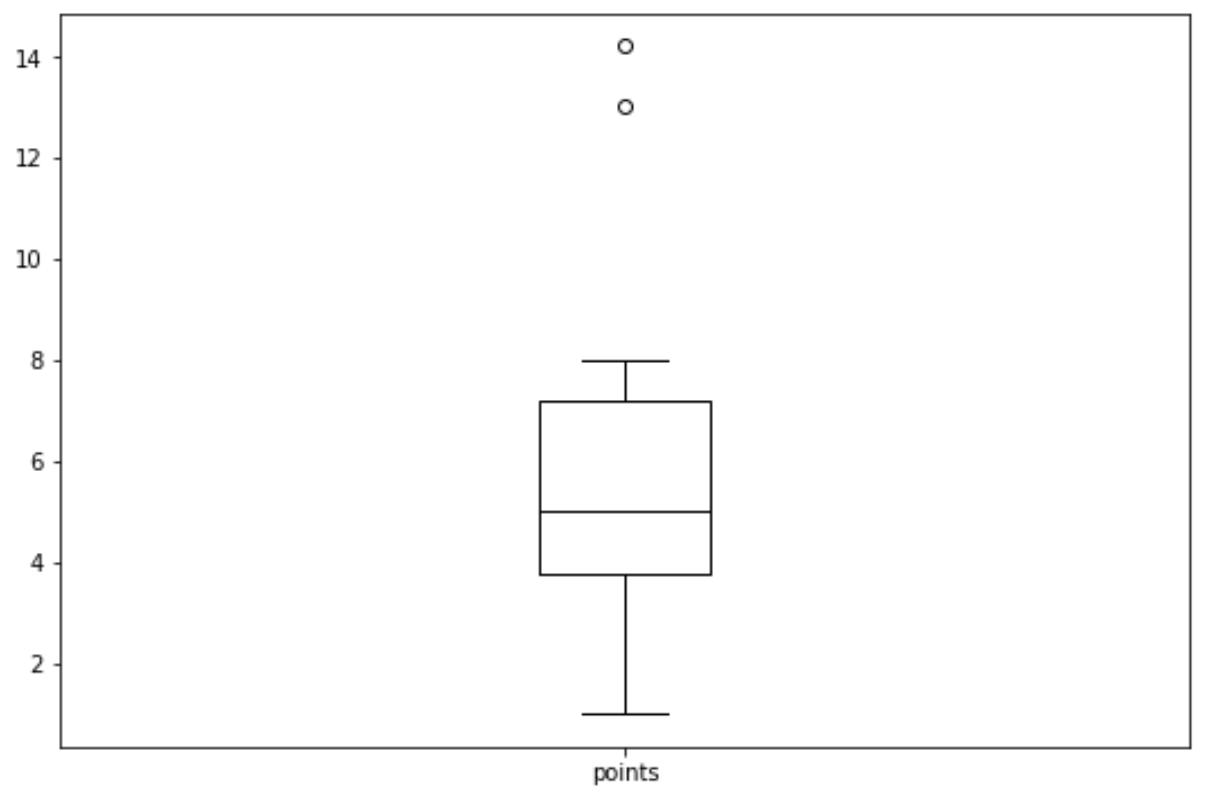
3. Создайте диаграммы
Мы можем использовать следующий синтаксис, чтобы создать коробчатую диаграмму для переменной «точки»:
import matplotlib.pyplot as plt
df.boxplot(column=['points'], grid= False , color='black')

Связанный: Как создать Boxplot из Pandas DataFrame
Мы можем использовать следующий синтаксис для создания гистограммы для переменной «точки»:
import matplotlib.pyplot as plt
df.hist (column='points', grid= False , edgecolor='black')

Связанный: Как создать гистограмму из Pandas DataFrame
Мы можем использовать следующий синтаксис для создания кривой плотности для переменной 'points':
import seaborn as sns
sns.kdeplot(df['points'])

Связанный: Как создать график плотности в Matplotlib
Каждая из этих диаграмм дает нам уникальный способ визуализации распределения значений переменной «точки».