В статистике мы используем проверку гипотез, чтобы определить, верно ли какое-либо предположение о параметре совокупности .
Проверка гипотезы всегда имеет следующие две гипотезы:
Нулевая гипотеза (H 0 ): данные выборки согласуются с преобладающим мнением о параметре совокупности.
Альтернативная гипотеза ( HA ): выборочные данные предполагают, что предположение, сделанное в нулевой гипотезе, неверно. Другими словами, на данные влияет какая-то неслучайная причина.
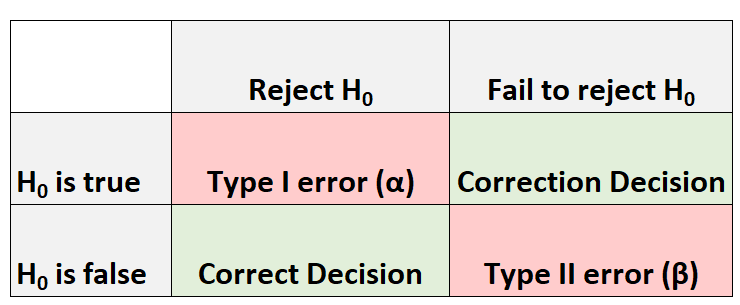
Всякий раз, когда мы проводим проверку гипотезы, всегда есть четыре возможных результата:
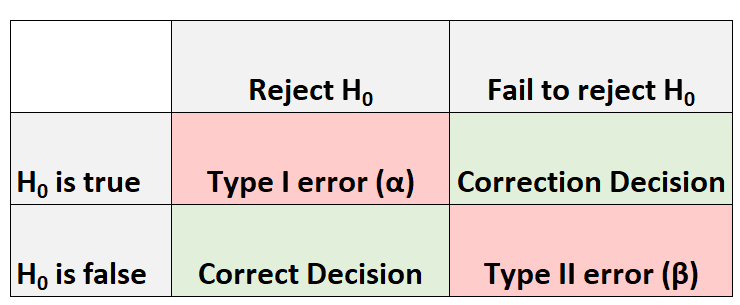
Есть два типа ошибок, которые мы можем совершить:
- Ошибка первого рода: мы отвергаем нулевую гипотезу, если она действительно верна. Вероятность совершения ошибки такого типа обозначается как α .
- Ошибка типа II: мы не можем отвергнуть нулевую гипотезу, когда она на самом деле ложна. Вероятность совершения ошибки такого типа обозначается как β .
Отношения между Альфой и Бетой
В идеале исследователи хотят, чтобы как вероятность совершения ошибки первого рода, так и вероятность совершения ошибки второго рода были низкими.
Однако между этими двумя вероятностями существует компромисс. Если мы уменьшим альфа-уровень, мы можем уменьшить вероятность отклонения нулевой гипотезы, когда она на самом деле верна, но на самом деле это увеличивает бета-уровень — вероятность того, что мы не сможем отвергнуть нулевую гипотезу, когда она на самом деле ложна.
Отношения между мощностью и бета
Мощность проверки гипотезы относится к вероятности обнаружения эффекта или различия, когда эффект или различие действительно присутствует. Другими словами, это вероятность правильного отклонения ложной нулевой гипотезы.
Он рассчитывается как:
Мощность = 1 – β
Как правило, исследователи хотят, чтобы мощность теста была высокой, чтобы, если какой-то эффект или различие действительно существует, тест мог их обнаружить.
Из приведенного выше уравнения видно, что лучший способ повысить мощность теста — снизить бета-уровень. И лучший способ уменьшить бета-уровень, как правило, — это увеличить размер выборки.
В следующих примерах показано, как рассчитать бета-уровень проверки гипотезы, и показано, почему увеличение размера выборки может снизить бета-уровень.
Пример 1: расчет бета для проверки гипотезы
Предположим, исследователь хочет проверить, меньше ли средний вес изделий, произведенных на фабрике, 500 унций. Известно, что стандартное отклонение весов составляет 24 унции, и исследователь решает собрать случайную выборку из 40 штук.
Он выполнит следующую гипотезу при α = 0,05:
- H 0 : μ = 500
- Н А : мк < 500
Теперь представьте, что средний вес производимых изделий составляет 490 унций. Другими словами, нулевая гипотеза должна быть отвергнута.
Мы можем использовать следующие шаги для расчета бета-уровня — вероятности того, что нулевая гипотеза не будет отвергнута, когда ее действительно следует отвергнуть:
Шаг 1: Найдите неотклоняемую область.
Согласно Калькулятору критического значения Z , левостороннее критическое значение при α = 0,05 составляет -1,645 .
Шаг 2: Найдите минимальное значение выборки, которое мы не сможем отклонить.
Статистика теста рассчитывается как z = ( x - μ) / (s / √ n )
Таким образом, мы можем решить это уравнение для выборочного среднего:
- х = μ - z * (с / √ п )
- х = 500 – 1,645*(24/ √40 )
- х = 493,758
Шаг 3: Найдите вероятность того, что минимальное среднее значение выборки действительно произойдет.
Мы можем рассчитать эту вероятность как:
- P(Z ≥ (493,758 – 490) / (24/√ 40 ))
- Р(Z ≥ 0,99)
Согласно калькулятору нормального CDF , вероятность того, что Z ≥ 0,99, составляет 0,1611 .
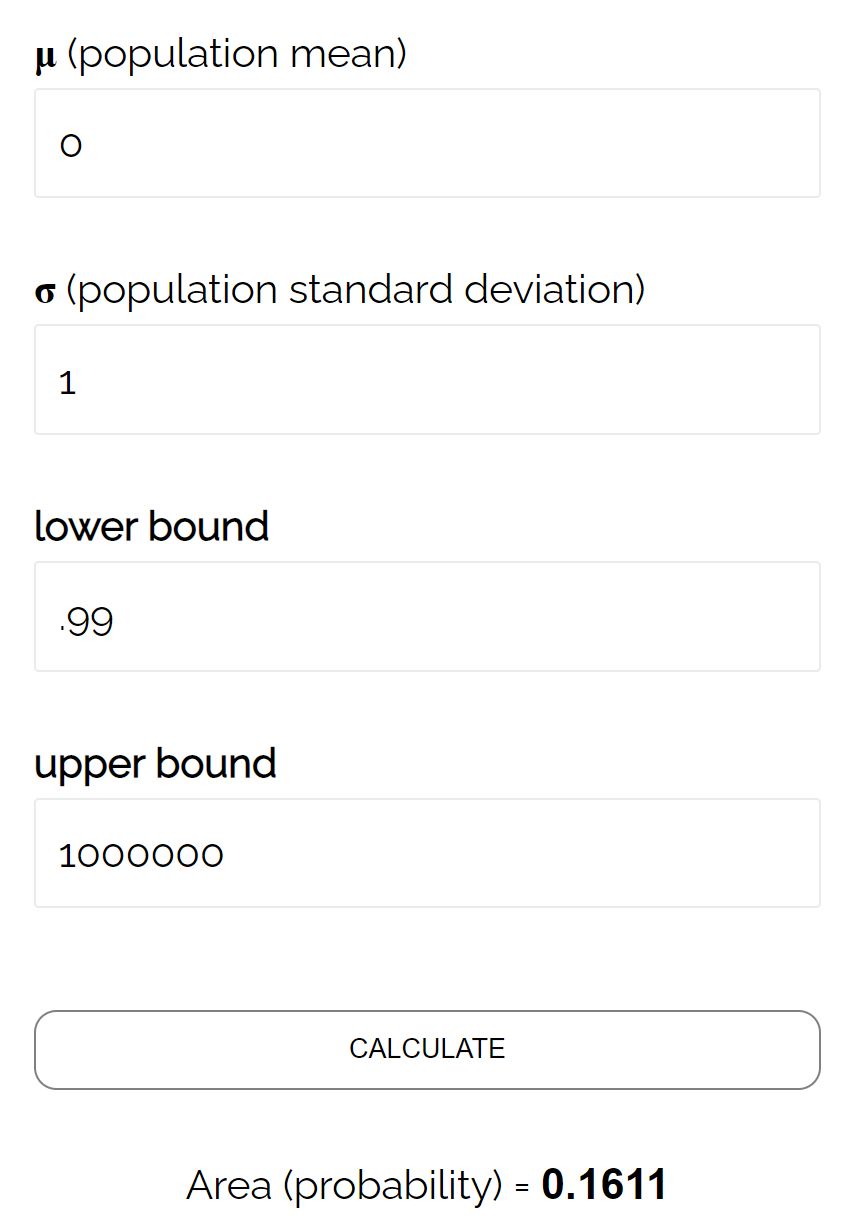
Таким образом, бета-уровень для этого теста составляет β = 0,1611. Это означает, что существует 16,11%-ная вероятность того, что разница не будет обнаружена, если реальное среднее значение составляет 490 унций.
Пример 2. Вычисление коэффициента бета для теста с большим объемом выборки
Теперь предположим, что исследователь выполняет ту же самую проверку гипотезы, но вместо этого использует размер выборки n = 100 виджетов. Мы можем повторить те же три шага, чтобы рассчитать бета-уровень для этого теста:
Шаг 1: Найдите неотклоняемую область.
Согласно Калькулятору критического значения Z , левостороннее критическое значение при α = 0,05 составляет -1,645 .
Шаг 2: Найдите минимальное значение выборки, которое мы не сможем отклонить.
Статистика теста рассчитывается как z = ( x - μ) / (s / √ n )
Таким образом, мы можем решить это уравнение для выборочного среднего:
- х = μ - z * (с / √ п )
- х = 500 – 1,645*(24/ √100 )
- х = 496,05
Шаг 3: Найдите вероятность того, что минимальное среднее значение выборки действительно произойдет.
Мы можем рассчитать эту вероятность как:
- P(Z ≥ (496,05 – 490) / (24/√ 100 ))
- P(Z ≥ 2,52)
Согласно калькулятору нормального CDF , вероятность того, что Z ≥ 2,52, составляет 0,0059.
Таким образом, бета-уровень для этого теста составляет β = 0,0059. Это означает, что вероятность того, что разница не будет обнаружена, составляет всего 0,59%, если реальное среднее значение составляет 490 унций.
Обратите внимание, что просто увеличив размер выборки с 40 до 100, исследователь смог снизить бета-уровень с 0,1611 до 0,0059.
Бонус: используйте этот калькулятор ошибок типа II для автоматического расчета бета-уровня теста.
Дополнительные ресурсы
Введение в проверку гипотез
Как написать нулевую гипотезу (5 примеров)
Объяснение P-значений и статистической значимости