Когда у нас есть набор данных с одной переменной-предиктором и одной переменной-ответом , мы часто используем простую линейную регрессию для количественной оценки взаимосвязи между двумя переменными.
Однако простая линейная регрессия (SLR) предполагает, что связь между предиктором и переменной отклика является линейной. Записанный в математической нотации, SLR предполагает, что отношение принимает форму:
Y = β 0 + β 1 X + ε
Но на практике взаимосвязь между двумя переменными может быть нелинейной, и попытка использовать линейную регрессию может привести к плохо подходящей модели.
Один из способов учета нелинейной связи между предиктором и переменной отклика состоит в использовании полиномиальной регрессии , которая принимает форму:
Y = β 0 + β 1 X + β 2 X 2 + … + β h X h + ε
В этом уравнении h называется степенью многочлена.
Когда мы увеличиваем значение h , модель лучше соответствует нелинейным отношениям, но на практике мы редко выбираем h больше 3 или 4. За пределами этой точки модель становится слишком гибкой и подгоняет данные .
Технические примечания
- Хотя полиномиальная регрессия может соответствовать нелинейным данным, она по-прежнему считается формой линейной регрессии, поскольку она является линейной по коэффициентам β 1 , β 2 , …, β h .
- Полиномиальную регрессию можно использовать и для нескольких переменных-предикторов, но это создает условия взаимодействия в модели, что может сделать модель чрезвычайно сложной, если используется более нескольких переменных-предикторов.
Когда использовать полиномиальную регрессию
Мы используем полиномиальную регрессию, когда связь между предиктором и переменной отклика нелинейна.
Существует три распространенных способа обнаружения нелинейной зависимости:
1. Создайте диаграмму рассеяния.
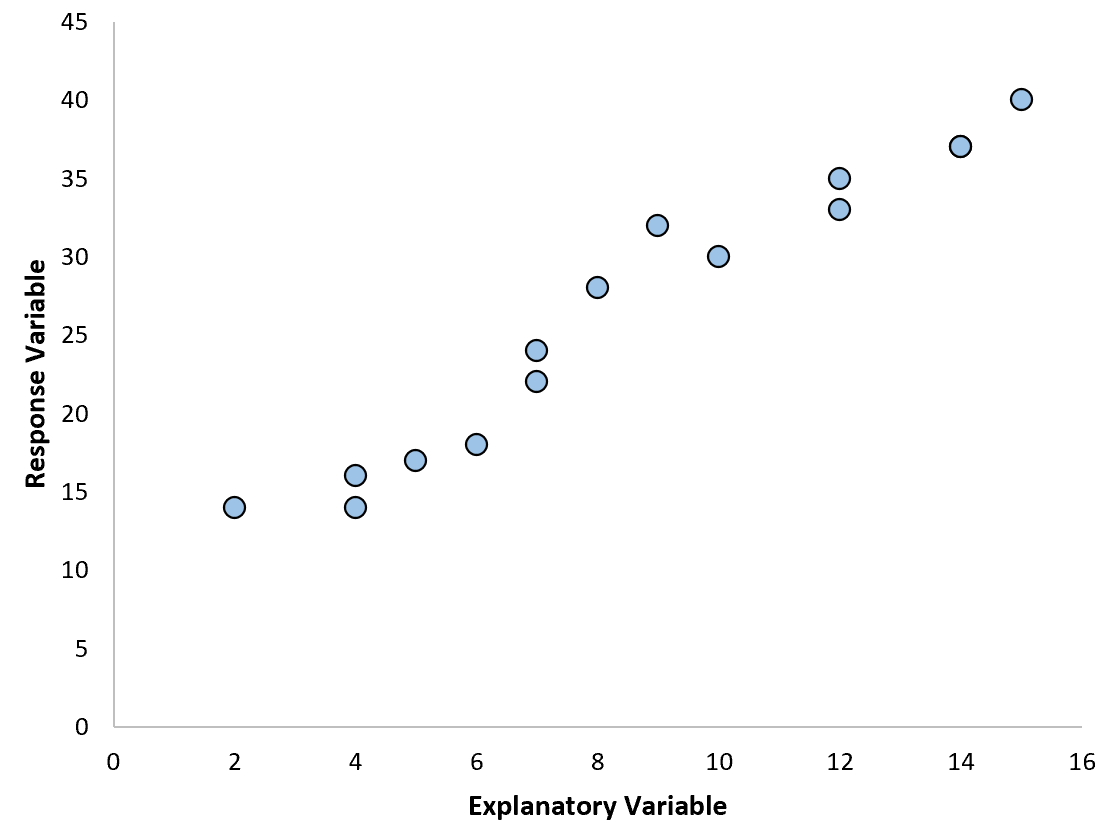
Самый простой способ обнаружить нелинейную связь — создать диаграмму рассеяния отклика по сравнению с переменной-предиктором.
Например, если мы создадим следующую диаграмму рассеяния, то увидим, что связь между двумя переменными является примерно линейной, поэтому простая линейная регрессия, вероятно, будет хорошо работать с этими данными.
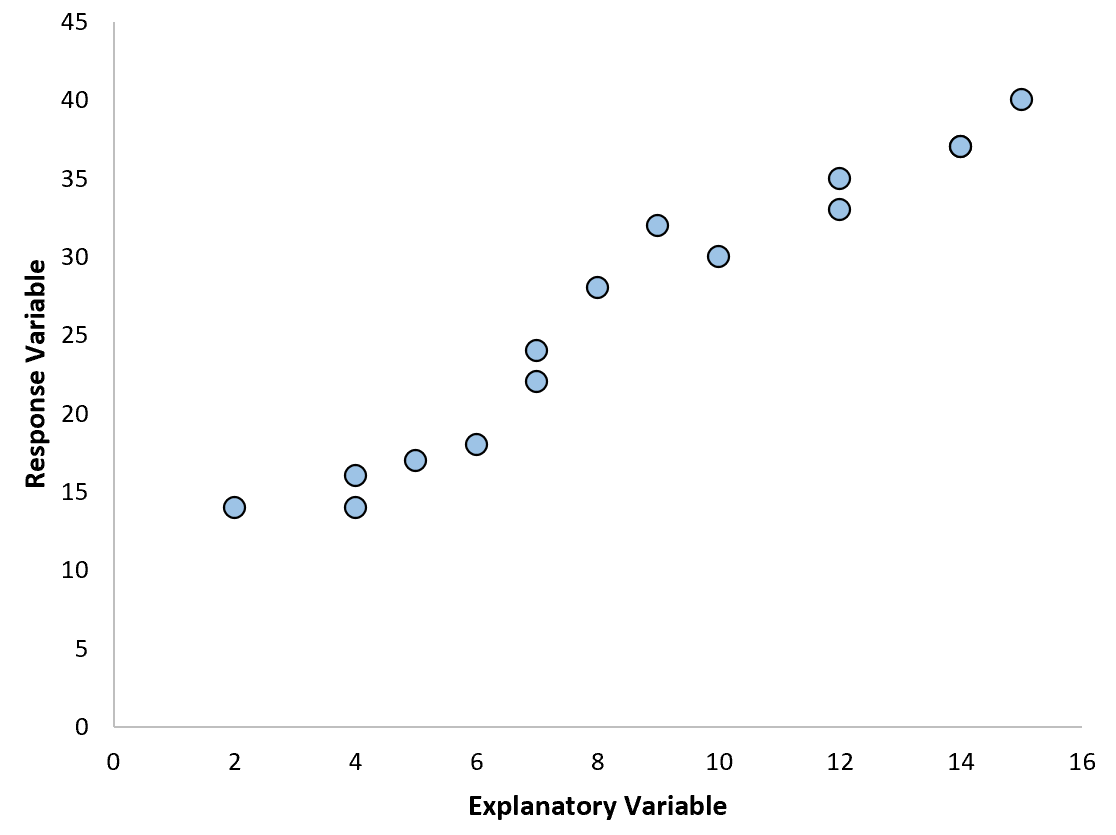
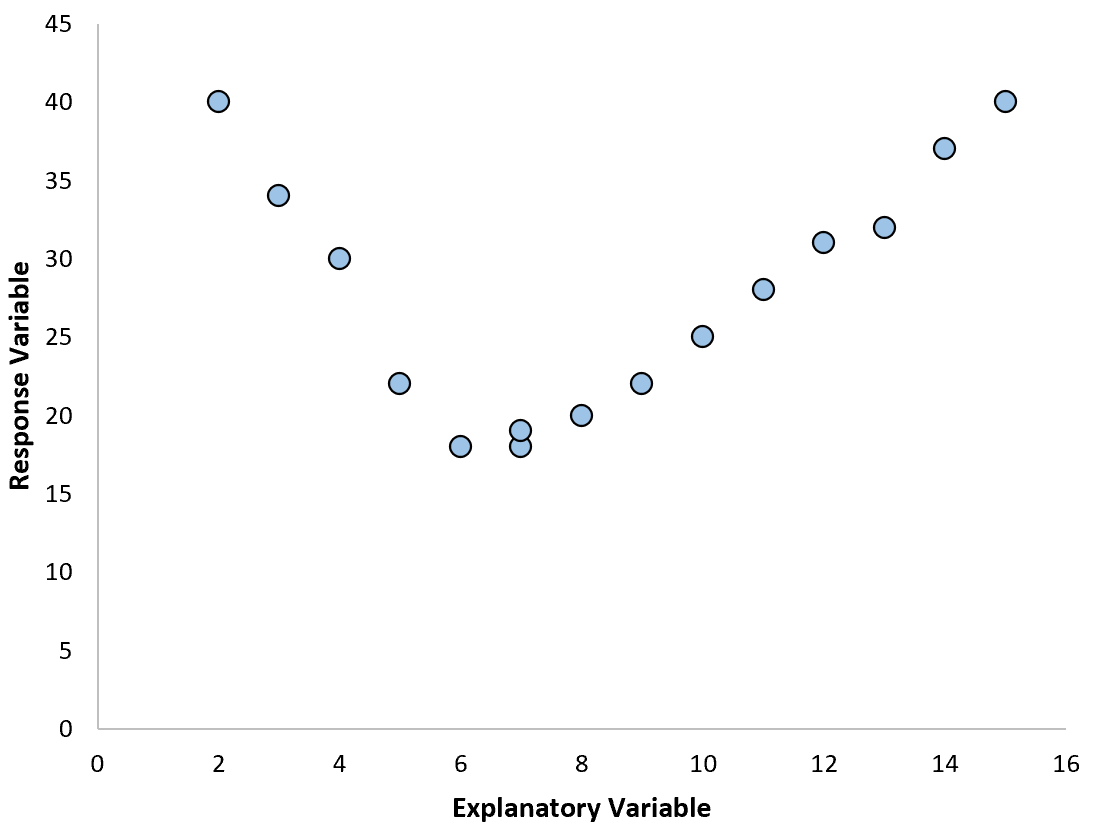
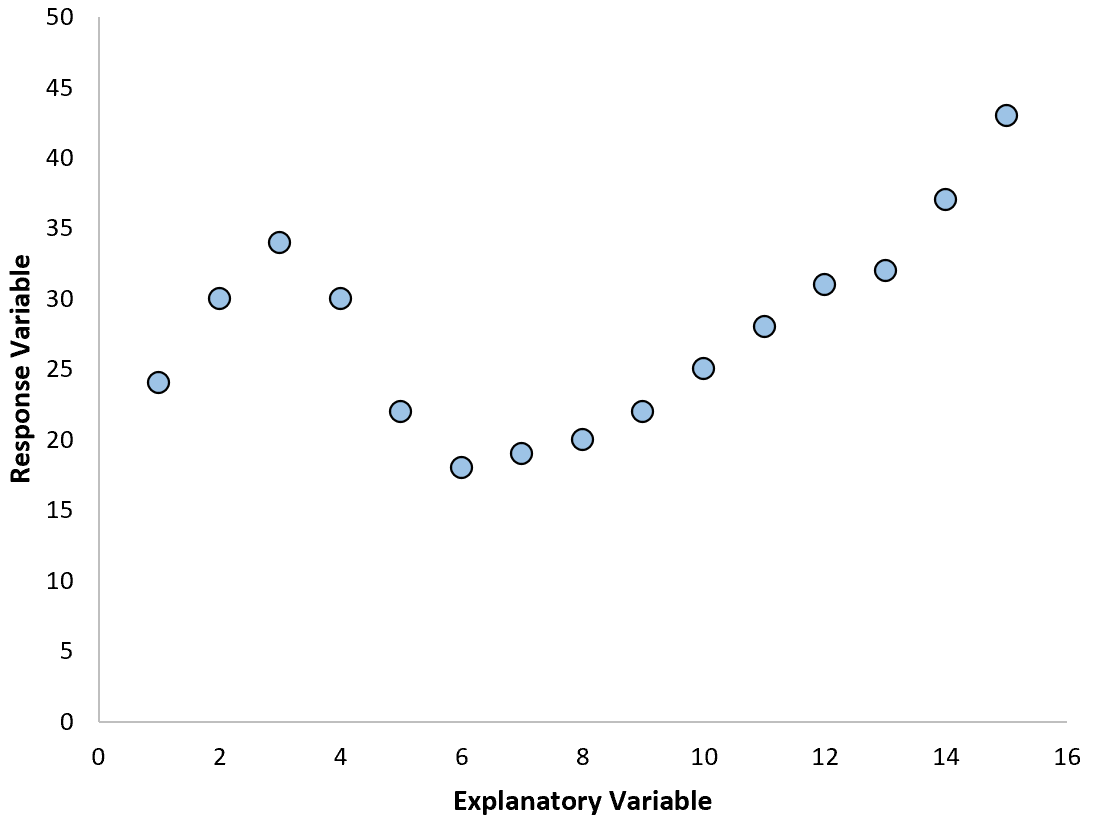
Однако, если наша диаграмма рассеяния выглядит как один из следующих графиков, мы можем видеть, что связь нелинейна, и поэтому полиномиальная регрессия была бы хорошей идеей:
2. Создайте график невязки по сравнению с подогнанным графиком.
Еще один способ обнаружить нелинейность — подогнать к данным простую модель линейной регрессии, а затем построить график зависимости невязок от подогнанных значений .
Если остатки графика примерно равномерно распределены вокруг нуля без четкой закономерности, то, вероятно, будет достаточно простой линейной регрессии.
Однако если остатки отображают на графике нелинейный шаблон, то это признак того, что взаимосвязь между предиктором и откликом, вероятно, нелинейна.
3. Рассчитайте R 2 модели.
Значение R 2 регрессионной модели сообщает вам процентную долю вариации переменной отклика, которая может быть объяснена предикторной переменной (переменными).
Если вы подгоняете простую модель линейной регрессии к набору данных, а значение R 2 модели довольно низкое, это может указывать на то, что взаимосвязь между предиктором и переменной отклика более сложна, чем простая линейная взаимосвязь.
Это может быть признаком того, что вам, возможно, придется попробовать полиномиальную регрессию.
Связанный:Что такое хорошее значение R-квадрата?
Как выбрать степень многочлена
Модель полиномиальной регрессии принимает следующий вид:
Y = β 0 + β 1 X + β 2 X 2 + … + β h X h + ε
В этом уравнении h — степень многочлена.
Но как мы выбираем значение для h ?
На практике мы подбираем несколько разных моделей с разными значениями h и выполняем k-кратную перекрестную проверку , чтобы определить, какая модель дает наименьшую среднеквадратичную ошибку теста (MSE).
Например, мы можем подогнать следующие модели к заданному набору данных:
- Y = β 0 + β 1 X
- Y = β 0 + β 1 X + β 2 X 2
- Y = β 0 + β 1 X + β 2 X 2 + β 3 X 3
- Y = β 0 + β 1 X + β 2 X 2 + β 3 X 3 + β 4 X 4
Затем мы можем использовать k-кратную перекрестную проверку для расчета тестовой MSE каждой модели, которая покажет нам, насколько хорошо каждая модель работает с данными, которых она раньше не видела.
Компромисс между смещением и дисперсией полиномиальной регрессии
При использовании полиномиальной регрессии существует компромисс между смещением и дисперсией.По мере увеличения степени полинома смещение уменьшается (так как модель становится более гибкой), но увеличивается дисперсия.
Как и во всех моделях машинного обучения, мы должны найти оптимальный компромисс между предвзятостью и дисперсией.
В большинстве случаев это помогает увеличить степень полинома до некоторой степени, но после определенного значения модель начинает соответствовать шуму данных, и тестовая СКО начинает уменьшаться.
Чтобы гарантировать, что мы подбираем модель, которая является гибкой, но не слишком гибкой, мы используем перекрестную проверку k-кратного размера, чтобы найти модель, которая дает наименьшую тестовую MSE.
Как выполнить полиномиальную регрессию
В следующих руководствах представлены примеры выполнения полиномиальной регрессии в различных программах:
Как выполнить полиномиальную регрессию в Excel
Как выполнить полиномиальную регрессию в R
Как выполнить полиномиальную регрессию в Python