При использовании моделей классификации в машинном обучении одной метрикой, которую мы часто используем для оценки качества модели, является точность .
Точность — это просто процент всех наблюдений, которые правильно классифицируются моделью.
Он рассчитывается как:
Точность = (количество истинно положительных результатов + # истинно отрицательных результатов) / (общий размер выборки)
Один вопрос, который часто возникает у студентов о точности:
Что считается «хорошим» значением точности модели машинного обучения?
Хотя точность модели может варьироваться от 0% до 100%, не существует универсального порога, который мы используем, чтобы определить, имеет ли модель «хорошую» точность или нет.
Вместо этого мы обычно сравниваем точность нашей модели с точностью некоторой базовой модели.
Базовая модель — это модель, которая просто предсказывает, что каждое наблюдение в наборе данных принадлежит к наиболее распространенному классу.
На практике любая классификационная модель, имеющая более высокую точность, чем базовая модель, может считаться «полезной», но очевидно, что чем больше разница в точности между нашей моделью и базовой моделью, тем лучше.
В следующем примере показано, как приблизительно определить, имеет ли модель классификации «хорошую» точность или нет.
Пример: определение того, имеет ли модель «хорошую» точность
Предположим, мы используем модель логистической регрессии, чтобы предсказать, попадут ли в НБА 400 разных баскетболистов из колледжей.
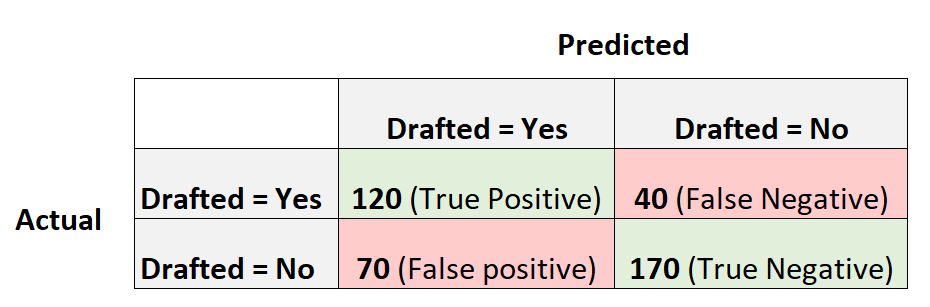
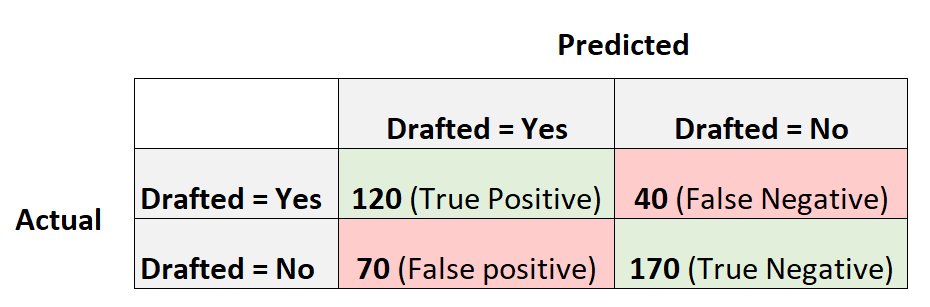
Следующая матрица путаницы суммирует прогнозы, сделанные моделью:
Вот как рассчитать точность этой модели:
- Точность = (количество истинно положительных результатов + # истинно отрицательных результатов) / (общий размер выборки)
- Точность = (120 + 170) / (400)
- Точность = 0,725
Модель правильно предсказала исход для 72,5% игроков.
Чтобы получить представление о том, является ли точность «хорошей», мы можем рассчитать точность базовой модели.
В этом примере наиболее частым исходом для игроков было не попасть на драфт. В частности, 240 из 400 игроков не были задрафтованы.
Базовая модель — это та, которая просто предсказывает, что каждый игрок не будет выбран на драфте.
Точность этой модели будет рассчитываться как:
- Точность = (количество истинно положительных результатов + # истинно отрицательных результатов) / (общий размер выборки)
- Точность = (0 + 240) / (400)
- Точность = 0,6
Эта базовая модель правильно предсказывает результат для 60% игроков.
В этом сценарии наша модель логистической регрессии предлагает заметное улучшение точности по сравнению с базовой моделью, поэтому мы считаем нашу модель как минимум «полезной».
На практике мы, вероятно, подойдем к нескольким различным моделям классификации и выберем окончательную модель как ту, которая предлагает наибольший прирост точности по сравнению с базовой моделью.
Предостережения относительно использования точности для оценки производительности модели
Точность является широко используемой метрикой, потому что ее легко интерпретировать.
Например, если мы говорим, что модель точна на 90%, мы знаем, что она правильно классифицировала 90% наблюдений.
Однако точность не учитывает, как распределяются данные.
Например, предположим, что 90% всех игроков не попадают в НБА. Если у нас есть модель, которая просто предсказывает, что каждый игрок не будет выбран на драфте, модель будет правильно предсказывать результат для 90% игроков.
Это значение кажется высоким, но на самом деле модель не может правильно предсказать любого игрока, который будет выбран на драфте.
Альтернативная метрика, которая часто используется, называется F1 Score , которая учитывает, как распределяются данные.
Например, если данные сильно несбалансированы (например, 90% всех игроков не выбираются на драфт, а 10% выбираются), то оценка F1 обеспечит лучшую оценку эффективности модели.
Подробнее о различиях между точностью и оценкой F1 читайте здесь .
Дополнительные ресурсы
В следующих руководствах представлена дополнительная информация о метриках, используемых в моделях классификации в машинном обучении:
Что такое сбалансированная точность?
Что считается «хорошей» оценкой F1?