Простая линейная регрессия — это метод, который мы можем использовать для понимания взаимосвязи между одной переменной-предиктором и переменной- откликом .
Этот метод находит линию, которая лучше всего «соответствует» данным, и принимает следующий вид:
ŷ = б 0 + б 1 х
куда:
- ŷ : Расчетное значение отклика
- b 0 : точка пересечения линии регрессии
- b 1 : Наклон линии регрессии
Это уравнение помогает нам понять взаимосвязь между переменной-предиктором и переменной-ответом.
В следующем пошаговом примере показано, как выполнить простую линейную регрессию в SAS.
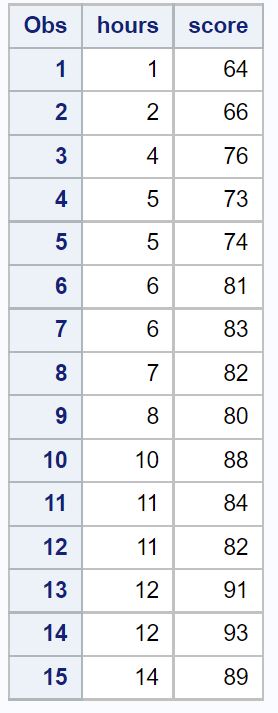
Шаг 1: Создайте данные
В этом примере мы создадим набор данных, содержащий общее количество часов обучения и итоговую оценку экзамена для 15 студентов.
Мы подгоним простую модель линейной регрессии, используя часы в качестве переменной-предиктора и оценку в качестве переменной-ответа.
Следующий код показывает, как создать этот набор данных в SAS:
/\*create dataset\*/
data exam_data;
input hours score;
datalines ;
1 64
2 66
4 76
5 73
5 74
6 81
6 83
7 82
8 80
10 88
11 84
11 82
12 91
12 93
14 89
;
run ;
/\*view dataset\*/
proc print data =exam_data;
Шаг 2: Подберите простую модель линейной регрессии
Далее мы будем использовать proc reg для соответствия простой модели линейной регрессии:
/\*fit simple linear regression model\*/
proc reg data =exam_data;
model score = hours;
run ;
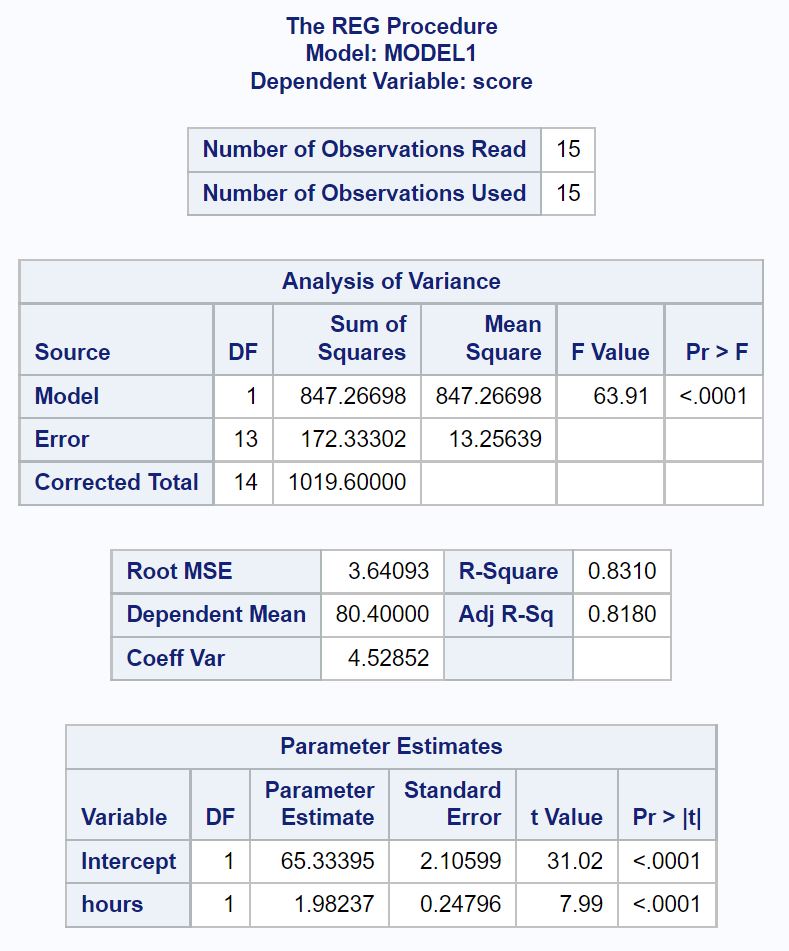
Вот как интерпретировать наиболее важные значения из каждой таблицы в выходных данных:
Таблица анализа дисперсии:
Общее F-значение регрессионной модели составляет 63,91 , а соответствующее p-значение <0,0001 .
Поскольку это p-значение меньше 0,05, мы заключаем, что регрессионная модель в целом является статистически значимой. Другими словами, количество часов является полезной переменной для прогнозирования результатов экзамена.
Таблица соответствия модели:
Значение R-Square говорит нам о процентной вариации экзаменационных баллов, которую можно объяснить количеством часов обучения.
В общем, чем больше значение R-квадрата регрессионной модели, тем лучше переменные-предикторы способны предсказать значение переменной отклика.
В этом случае 83,1% разброса экзаменационных баллов можно объяснить количеством часов обучения. Это значение довольно велико, что указывает на то, что количество часов обучения является очень полезной переменной для прогнозирования результатов экзамена.
Таблица оценок параметров:
Из этой таблицы мы можем увидеть подобранное уравнение регрессии:
Оценка = 65,33 + 1,98 * (часы)
Мы интерпретируем это так, что каждый дополнительный час обучения связан со средним увеличением экзаменационного балла на 1,98 балла .
Значение перехвата говорит нам, что средний балл на экзамене для студента, который учится без часов, составляет 65,33 .
Мы также можем использовать это уравнение, чтобы найти ожидаемую оценку экзамена на основе количества часов, которые изучает студент.
Например, студент, который занимается 10 часов, должен получить экзаменационный балл 85,13 :
Оценка = 65,33 + 1,98 * (10) = 85,13
Поскольку p-значение (<0,0001) для часов меньше 0,05 в этой таблице, мы делаем вывод, что это статистически значимая предикторная переменная.
Шаг 3: проанализируйте остаточные графики
Простая линейная регрессия делает два важных предположения об остатках модели:
- Остатки распределены нормально.
- Остатки имеют одинаковую дисперсию (« гомоскедастичность ») на каждом уровне предиктора.
Если эти допущения нарушаются, то результаты нашей регрессионной модели могут быть ненадежными.
Чтобы убедиться, что эти предположения выполняются, мы можем проанализировать остаточные графики, которые SAS автоматически выдает:
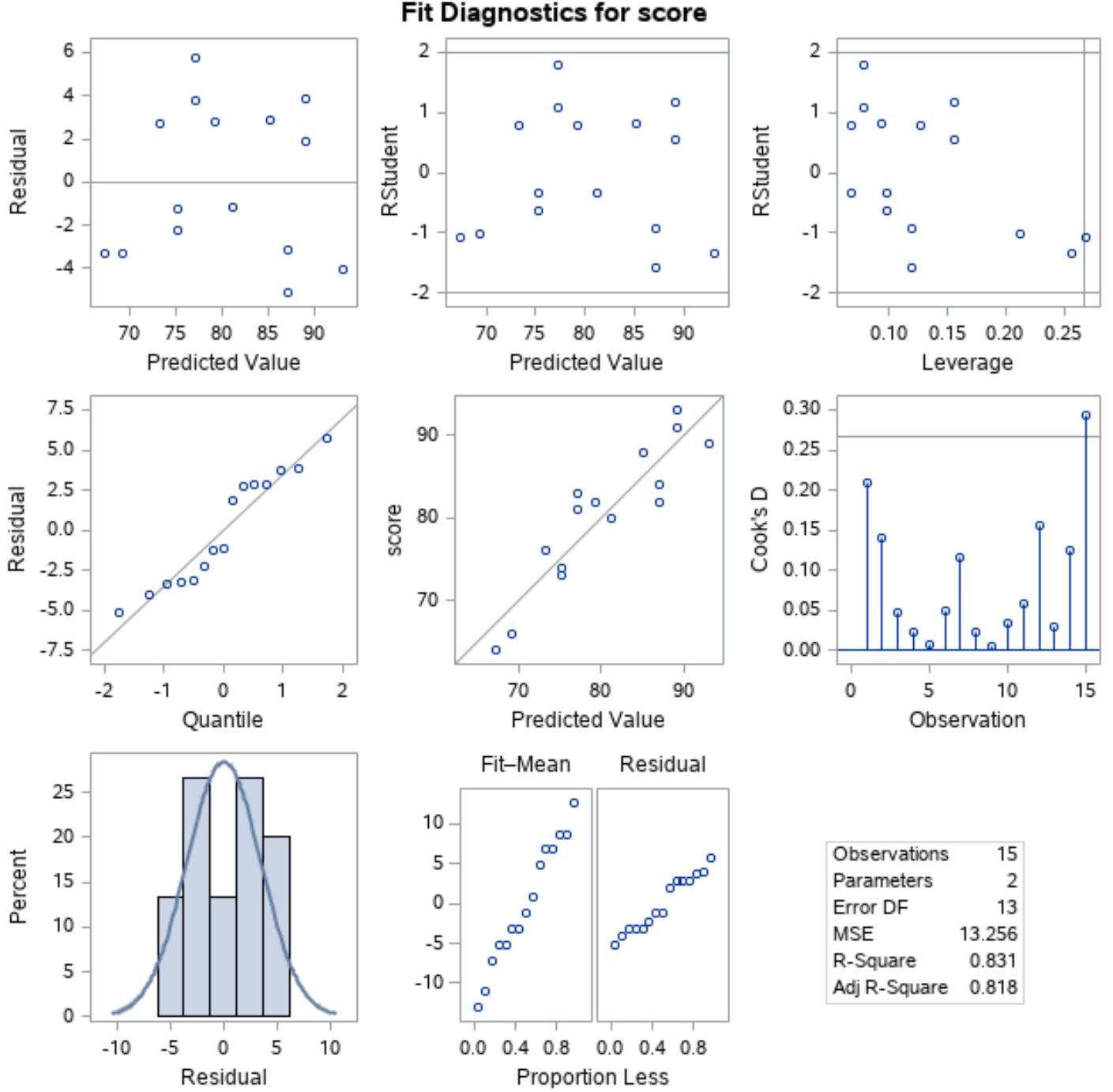
Чтобы убедиться, что остатки распределены нормально , мы можем проанализировать график в левой позиции средней строки с «Квантиль» по оси X и «Остаток» по оси Y.
Этот график называется графиком QQ , сокращением от графика «квантиль-квантиль», и используется для определения того, нормально ли распределены данные. Если данные распределены нормально, точки на графике QQ будут лежать на прямой диагональной линии.
Из графика видно, что точки падают примерно по прямой диагональной линии, поэтому можно предположить, что остатки распределены нормально.
Затем, чтобы убедиться, что остатки гомоскедастичны , мы можем посмотреть на график в левой позиции первой строки с «Прогнозируемым значением» по оси X и «Остатком» по оси Y.
Если точки на графике случайным образом разбросаны вокруг нуля без четкой закономерности, мы можем предположить, что остатки гомоскедастичны.
Из графика видно, что точки разбросаны около нуля случайным образом с примерно одинаковой дисперсией на каждом уровне по всему графику, поэтому мы можем предположить, что остатки гомоскедастичны.
Поскольку выполняются оба предположения, мы можем предположить, что результаты простой модели линейной регрессии надежны.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные задачи в SAS:
Как выполнить односторонний ANOVA в SAS
Как выполнить двухсторонний ANOVA в SAS
Как рассчитать корреляцию в SAS