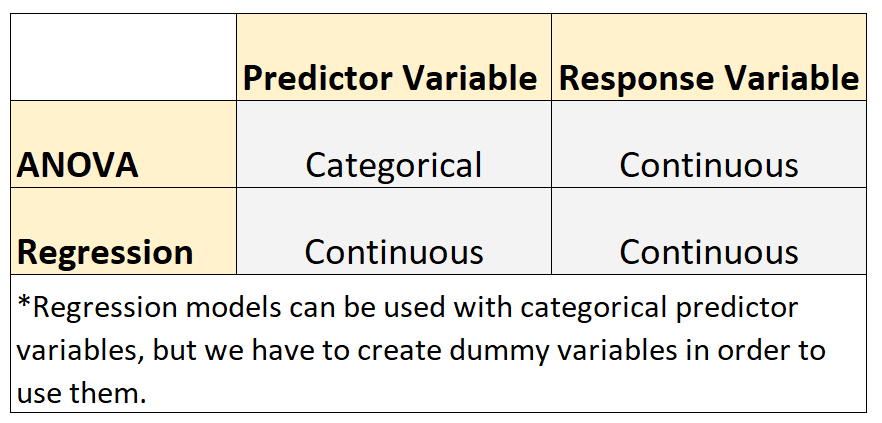
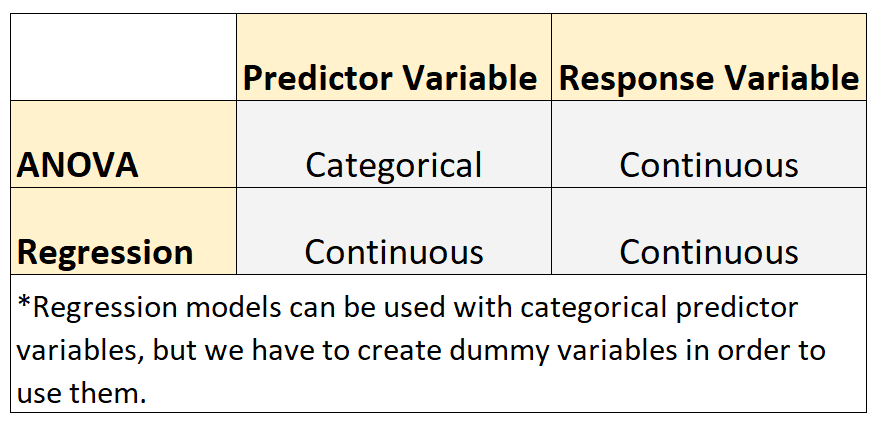
В статистике обычно используются две модели: ANOVA и регрессионные модели.
Эти два типа моделей имеют следующее сходство:
- Переменная отклика в каждой модели непрерывна. Примеры непрерывных переменных включают вес, рост, длину, ширину, время, возраст и т. д.
Однако эти два типа моделей имеют следующее различие :
- Модели ANOVA используются, когда переменные-предикторы являются категориальными. Примеры категориальных переменных включают уровень образования, цвет глаз, семейное положение и т. д.
- Модели регрессии используются, когда переменные-предикторы являются непрерывными.*
*Модели регрессии можно использовать с категориальными переменными-предикторами, но для их использования необходимо создать фиктивные переменные .
В следующих примерах показано, когда на практике следует использовать ANOVA и регрессионные модели.
Пример 1: предпочтительная модель ANOVA
Предположим, биолог хочет понять, приводят ли четыре разных удобрения к одинаковому среднему росту растений (в дюймах) в течение одного месяца. Чтобы проверить это, она применяет каждое удобрение к 20 растениям и записывает рост каждого растения через месяц.
В этом сценарии биолог должен использовать однофакторную модель ANOVA для анализа различий между удобрениями, поскольку существует одна предикторная переменная, и она является категориальной.
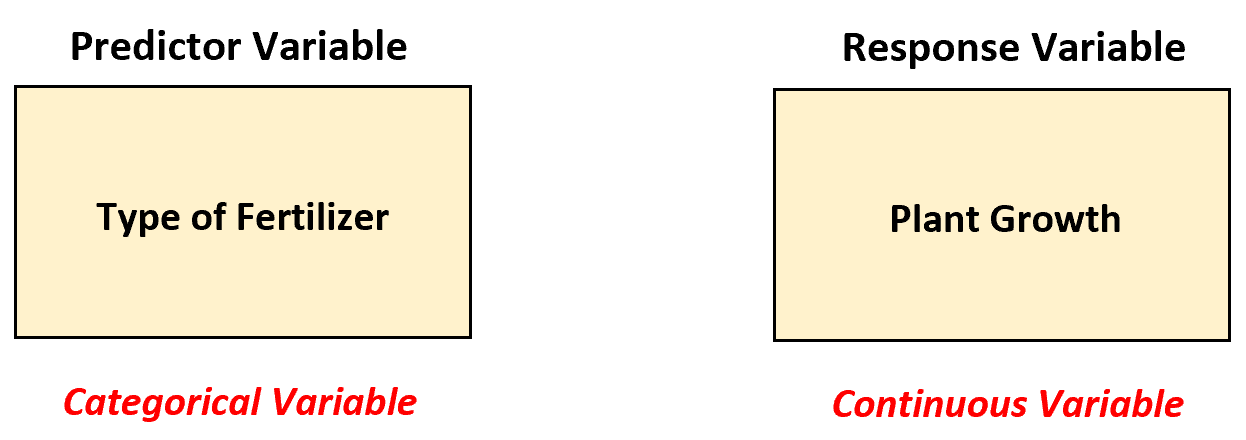
Другими словами, значения переменной-предиктора можно разделить на следующие «категории»:
- Удобрение 1
- Удобрение 2
- Удобрение 3
- Удобрение 4
Однофакторный дисперсионный анализ покажет биологу, одинаков ли средний рост растений между четырьмя различными удобрениями.
Пример 2: Предпочтительная модель регрессии
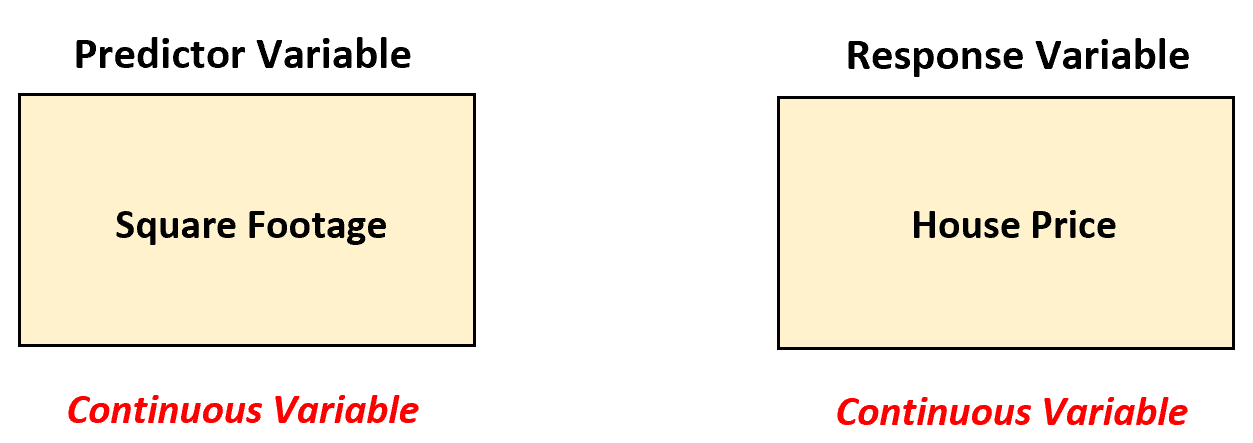
Предположим, агент по недвижимости хочет понять взаимосвязь между площадью в квадратных футах и ценой дома. Чтобы проанализировать эту взаимосвязь, он собирает данные о площади и стоимости 200 домов в определенном городе.
В этом сценарии агент по недвижимости должен использовать простую модель линейной регрессии для анализа взаимосвязи между этими двумя переменными, поскольку предикторная переменная (квадратные метры) непрерывна.
Используя простую линейную регрессию, агент по недвижимости может подобрать следующую регрессионную модель:
Цена дома = β 0 + β 1 (квадратные метры)
Значение для β 1 будет представлять собой среднее изменение цены дома, связанное с каждым дополнительным квадратным футом.
Это позволит агенту по недвижимости количественно оценить взаимосвязь между квадратными метрами и ценой дома.
Пример 3: Модель регрессии с предпочтительными фиктивными переменными
Предположим, агент по недвижимости хочет понять взаимосвязь между переменными-предикторами «квадратные метры» и «тип дома» (односемейный, квартира, таунхаус) с ответной переменной цены дома.
В этом сценарии агент по недвижимости может использовать множественную линейную регрессию, преобразуя «тип дома» в фиктивную переменную, поскольку в настоящее время это категориальная переменная.
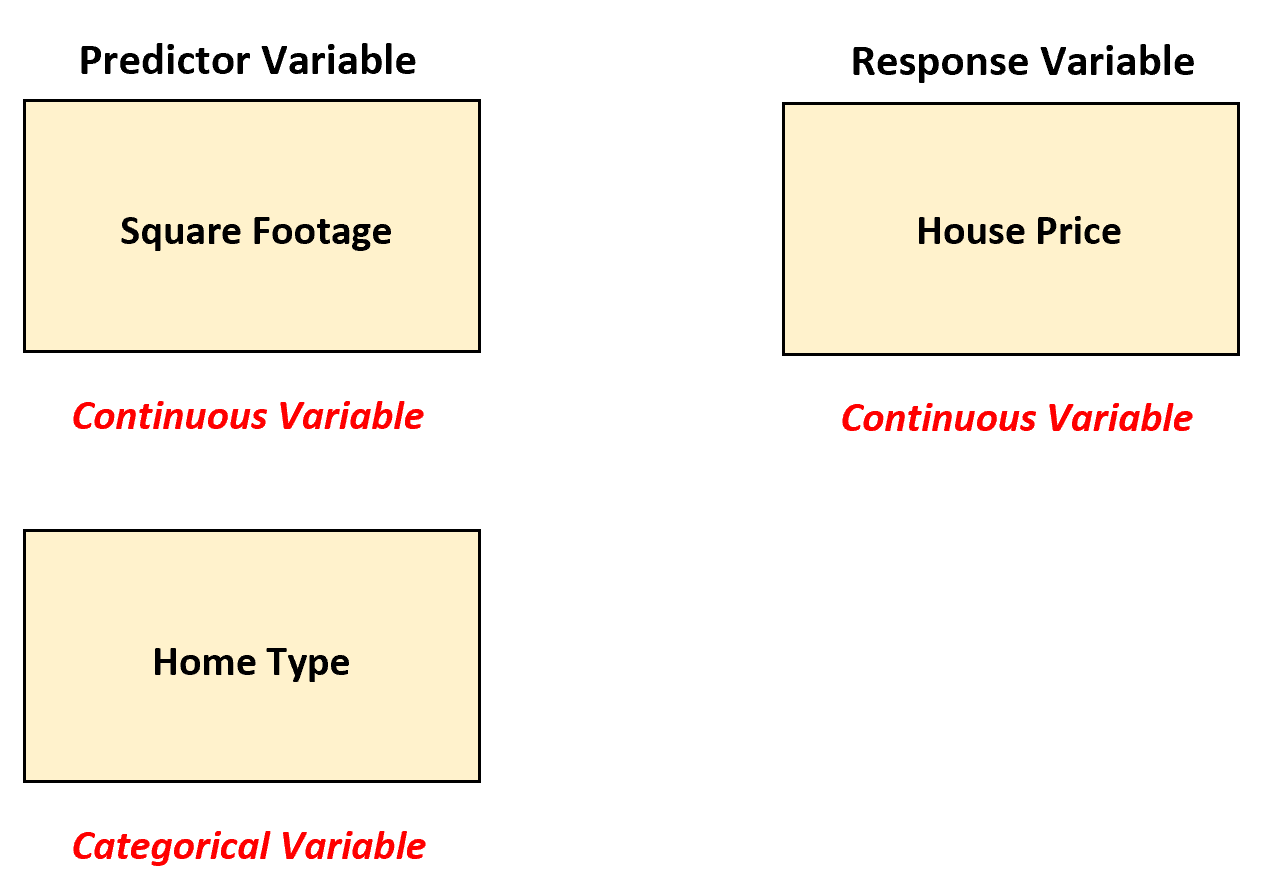
Затем агент по недвижимости может подобрать следующую модель множественной линейной регрессии:
Цена дома = β 0 + β 1 (квадратный метр) + β 2 (односемейный) + β 3 (квартира)
Вот как мы будем интерпретировать коэффициенты в модели:
- β 1 : Среднее изменение цены дома, связанное с одним дополнительным квадратным футом.
- β 2 : Средняя разница в цене между домом на одну семью и городским домом, при условии, что площадь в квадратных футах остается постоянной.
- β 3 : Средняя разница в цене между домом на одну семью и квартирой, при условии, что квадратные метры остаются постоянными.
Ознакомьтесь со следующими руководствами, чтобы узнать, как создавать фиктивные переменные в различных статистических программах:
Дополнительные ресурсы
Следующие учебные пособия предлагают углубленное введение в модели ANOVA:
Следующие руководства предлагают углубленное введение в модели линейной регрессии: